 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlossomRec: Block-level Fused Sparse Attention Mechanism for Sequential Recommendations
Dec 15, 2025Transformer structures have been widely used in sequential recommender systems (SRS). However, as user interaction histories increase, computational time and memory requirements also grow. This is mainly caused by the standard attention mechanism. Although there exist many methods employing efficient attention and SSM-based models, these approaches struggle to effectively model long sequences and may exhibit unstable performance on short sequences. To address these challenges, we design a sparse attention mechanism, BlossomRec, which models both long-term and short-term user interests through attention computation to achieve stable performance across sequences of varying lengths. Specifically, we categorize user interests in recommendation systems into long-term and short-term interests, and compute them using two distinct sparse attention patterns, with the results combined through a learnable gated output. Theoretically, it significantly reduces the number of interactions participating in attention computation. Extensive experiments on four public datasets demonstrate that BlossomRec, when integrated with state-of-the-art Transformer-based models, achieves comparable or even superior performance while significantly reducing memory usage, providing strong evidence of BlossomRec's efficiency and effectiveness.The code is available at https://github.com/ronineume/BlossomRec.
Automated Information Flow Selection for Multi-scenario Multi-task Recommendation
Dec 15, 2025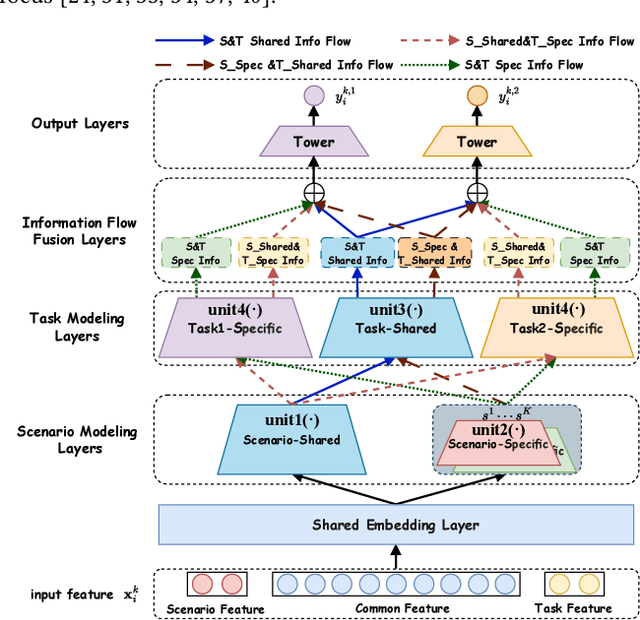
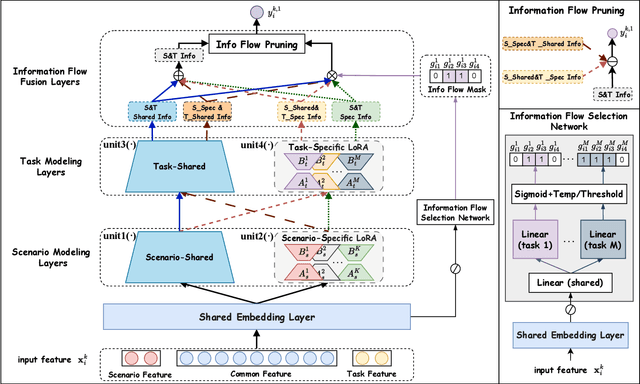
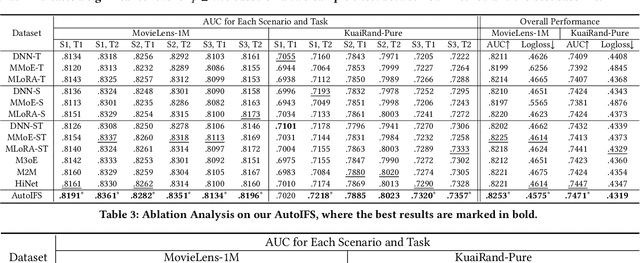
Multi-scenario multi-task recommendation (MSMTR) systems must address recommendation demands across diverse scenarios while simultaneously optimizing multiple objectives, such as click-through rate and conversion rate. Existing MSMTR models typically consist of four information units: scenario-shared, scenario-specific, task-shared, and task-specific networks. These units interact to generate four types of relationship information flows, directed from scenario-shared or scenario-specific networks to task-shared or task-specific networks. However, these models face two main limitations: 1) They often rely on complex architectures, such as mixture-of-experts (MoE) networks, which increase the complexity of information fusion, model size, and training cost. 2) They extract all available information flows without filtering out irrelevant or even harmful content, introducing potential noise. Regarding these challenges, we propose a lightweight Automated Information Flow Selection (AutoIFS) framework for MSMTR. To tackle the first issue, AutoIFS incorporates low-rank adaptation (LoRA) to decouple the four information units, enabling more flexible and efficient information fusion with minimal parameter overhead. To address the second issue, AutoIFS introduces an information flow selection network that automatically filters out invalid scenario-task information flows based on model performance feedback. It employs a simple yet effective pruning function to eliminate useless information flows, thereby enhancing the impact of key relationships and improving model performance. Finally, we evaluate AutoIFS and confirm its effectiveness through extensive experiments on two public benchmark datasets and an online A/B test.
Beyond Zero Initialization: Investigating the Impact of Non-Zero Initialization on LoRA Fine-Tuning Dynamics
May 29, 2025Low-rank adaptation (LoRA) is a widely used parameter-efficient fine-tuning method. In standard LoRA layers, one of the matrices, $A$ or $B$, is initialized to zero, ensuring that fine-tuning starts from the pretrained model. However, there is no theoretical support for this practice. In this paper, we investigate the impact of non-zero initialization on LoRA's fine-tuning dynamics from an infinite-width perspective. Our analysis reveals that, compared to zero initialization, simultaneously initializing $A$ and $B$ to non-zero values improves LoRA's robustness to suboptimal learning rates, particularly smaller ones. Further analysis indicates that although the non-zero initialization of $AB$ introduces random noise into the pretrained weight, it generally does not affect fine-tuning performance. In other words, fine-tuning does not need to strictly start from the pretrained model. The validity of our findings is confirmed through extensive experiments across various models and datasets. The code is available at https://github.com/Leopold1423/non_zero_lora-icml25.
The Panaceas for Improving Low-Rank Decomposition in Communication-Efficient Federated Learning
May 29, 2025To improve the training efficiency of federated learning (FL), previous research has employed low-rank decomposition techniques to reduce communication overhead. In this paper, we seek to enhance the performance of these low-rank decomposition methods. Specifically, we focus on three key issues related to decomposition in FL: what to decompose, how to decompose, and how to aggregate. Subsequently, we introduce three novel techniques: Model Update Decomposition (MUD), Block-wise Kronecker Decomposition (BKD), and Aggregation-Aware Decomposition (AAD), each targeting a specific issue. These techniques are complementary and can be applied simultaneously to achieve optimal performance. Additionally, we provide a rigorous theoretical analysis to ensure the convergence of the proposed MUD. Extensive experimental results show that our approach achieves faster convergence and superior accuracy compared to relevant baseline methods. The code is available at https://github.com/Leopold1423/fedmud-icml25.
Semantic Retrieval Augmented Contrastive Learning for Sequential Recommendation
Mar 06, 2025Sequential recommendation aims to model user preferences based on historical behavior sequences, which is crucial for various online platforms. Data sparsity remains a significant challenge in this area as most users have limited interactions and many items receive little attention. To mitigate this issue, contrastive learning has been widely adopted. By constructing positive sample pairs from the data itself and maximizing their agreement in the embedding space,it can leverage available data more effectively. Constructing reasonable positive sample pairs is crucial for the success of contrastive learning. However, current approaches struggle to generate reliable positive pairs as they either rely on representations learned from inherently sparse collaborative signals or use random perturbations which introduce significant uncertainty. To address these limitations, we propose a novel approach named Semantic Retrieval Augmented Contrastive Learning (SRA-CL), which leverages semantic information to improve the reliability of contrastive samples. SRA-CL comprises two main components: (1) Cross-Sequence Contrastive Learning via User Semantic Retrieval, which utilizes large language models (LLMs) to understand diverse user preferences and retrieve semantically similar users to form reliable positive samples through a learnable sample synthesis method; and (2) Intra-Sequence Contrastive Learning via Item Semantic Retrieval, which employs LLMs to comprehend items and retrieve similar items to perform semantic-based item substitution, thereby creating semantically consistent augmented views for contrastive learning. SRA-CL is plug-and-play and can be integrated into standard sequential recommendation models. Extensive experiments on four public datasets demonstrate the effectiveness and generalizability of the proposed approach.
Mixed-Precision Embeddings for Large-Scale Recommendation Models
Sep 30, 2024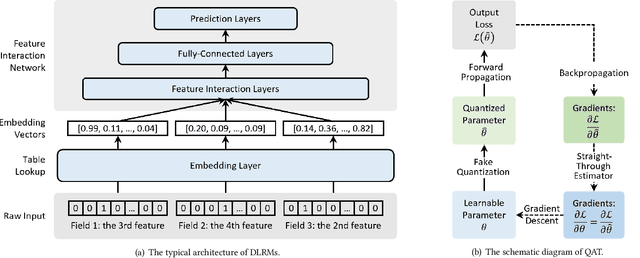
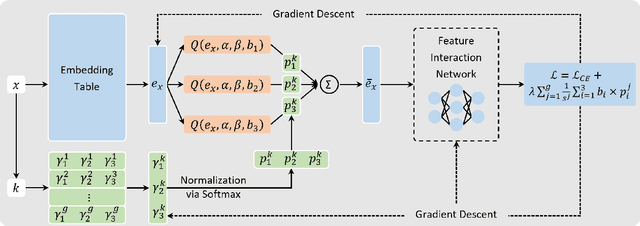
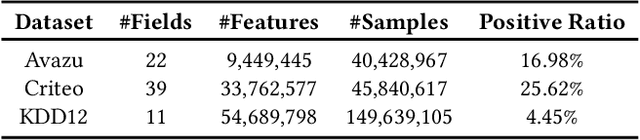
Embedding techniques have become essential components of large databases in the deep learning era. By encoding discrete entities, such as words, items, or graph nodes, into continuous vector spaces, embeddings facilitate more efficient storage, retrieval, and processing in large databases. Especially in the domain of recommender systems, millions of categorical features are encoded as unique embedding vectors, which facilitates the modeling of similarities and interactions among features. However, numerous embedding vectors can result in significant storage overhead. In this paper, we aim to compress the embedding table through quantization techniques. Given that features vary in importance levels, we seek to identify an appropriate precision for each feature to balance model accuracy and memory usage. To this end, we propose a novel embedding compression method, termed Mixed-Precision Embeddings (MPE). Specifically, to reduce the size of the search space, we first group features by frequency and then search precision for each feature group. MPE further learns the probability distribution over precision levels for each feature group, which can be used to identify the most suitable precision with a specially designed sampling strategy. Extensive experiments on three public datasets demonstrate that MPE significantly outperforms existing embedding compression methods. Remarkably, MPE achieves about 200x compression on the Criteo dataset without comprising the prediction accuracy.
FedBAT: Communication-Efficient Federated Learning via Learnable Binarization
Aug 06, 2024



Federated learning is a promising distributed machine learning paradigm that can effectively exploit large-scale data without exposing users' privacy. However, it may incur significant communication overhead, thereby potentially impairing the training efficiency. To address this challenge, numerous studies suggest binarizing the model updates. Nonetheless, traditional methods usually binarize model updates in a post-training manner, resulting in significant approximation errors and consequent degradation in model accuracy. To this end, we propose Federated Binarization-Aware Training (FedBAT), a novel framework that directly learns binary model updates during the local training process, thus inherently reducing the approximation errors. FedBAT incorporates an innovative binarization operator, along with meticulously designed derivatives to facilitate efficient learning. In addition, we establish theoretical guarantees regarding the convergence of FedBAT. Extensive experiments are conducted on four popular datasets. The results show that FedBAT significantly accelerates the convergence and exceeds the accuracy of baselines by up to 9\%, even surpassing that of FedAvg in some cases.
Masked Random Noise for Communication Efficient Federaetd Learning
Aug 06, 2024Federated learning is a promising distributed training paradigm that effectively safeguards data privacy. However, it may involve significant communication costs, which hinders training efficiency. In this paper, we aim to enhance communication efficiency from a new perspective. Specifically, we request the distributed clients to find optimal model updates relative to global model parameters within predefined random noise. For this purpose, we propose Federated Masked Random Noise (FedMRN), a novel framework that enables clients to learn a 1-bit mask for each model parameter and apply masked random noise (i.e., the Hadamard product of random noise and masks) to represent model updates. To make FedMRN feasible, we propose an advanced mask training strategy, called progressive stochastic masking (PSM). After local training, each client only need to transmit local masks and a random seed to the server. Additionally, we provide theoretical guarantees for the convergence of FedMRN under both strongly convex and non-convex assumptions. Extensive experiments are conducted on four popular datasets. The results show that FedMRN exhibits superior convergence speed and test accuracy compared to relevant baselines, while attaining a similar level of accuracy as FedAvg.
Towards Hybrid-grained Feature Interaction Selection for Deep Sparse Network
Oct 30, 2023Deep sparse networks are widely investigated as a neural network architecture for prediction tasks with high-dimensional sparse features, with which feature interaction selection is a critical component. While previous methods primarily focus on how to search feature interaction in a coarse-grained space, less attention has been given to a finer granularity. In this work, we introduce a hybrid-grained feature interaction selection approach that targets both feature field and feature value for deep sparse networks. To explore such expansive space, we propose a decomposed space which is calculated on the fly. We then develop a selection algorithm called OptFeature, which efficiently selects the feature interaction from both the feature field and the feature value simultaneously. Results from experiments on three large real-world benchmark datasets demonstrate that OptFeature performs well in terms of accuracy and efficiency. Additional studies support the feasibility of our method.