 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSUGA: LLM-Enhanced Recommendation with Hierarchical Semantic Understanding and Group-Aware Alignment
May 12, 2026Large language model (LLM)-enhanced sequential recommendation typically aims to improve two core components: user semantic embedding extraction and utilization. Despite promising results, existing methods still have two limitations: 1) In the extraction stage, most methods directly input long interaction sequence fragments into LLM for preference summarization. However, excessively long sequences increase inference difficulty, making it challenging to reliably infer accurate user embeddings. 2) In the utilization stage, most methods employ the same semantic embedding utilization strategy for all users, neglecting the differences caused by user activity levels, leading to suboptimal performance. To address these issues, we propose HSUGA, which introduces a simple yet effective plugin for each of the two core components: Hierarchical Semantic Understanding (HSU) and Group-Aware Alignment (GAA). HSU performs a staged two-phase preference mining and models preference evolution through constrained editing operations, thereby improving the reliability of user semantic extraction. GAA adjusts the intensity of semantic utilization based on user activity levels, providing weaker alignment for active users and stronger guidance for users with sparse historical data. Finally, extensive experiments on three benchmark datasets demonstrate the effectiveness and compatibility of HSUGA.
Retrieve-then-Adapt: Retrieval-Augmented Test-Time Adaptation for Sequential Recommendation
Apr 07, 2026The sequential recommendation (SR) task aims to predict the next item based on users' historical interaction sequences. Typically trained on historical data, SR models often struggle to adapt to real-time preference shifts during inference due to challenges posed by distributional divergence and parameterized constraints. Existing approaches to address this issue include test-time training, test-time augmentation, and retrieval-augmented fine-tuning. However, these methods either introduce significant computational overhead, rely on random augmentation strategies, or require a carefully designed two-stage training paradigm. In this paper, we argue that the key to effective test-time adaptation lies in achieving both effective augmentation and efficient adaptation. To this end, we propose Retrieve-then-Adapt (ReAd), a novel framework that dynamically adapts a deployed SR model to the test distribution through retrieved user preference signals. Specifically, given a trained SR model, ReAd first retrieves collaboratively similar items for a test user from a constructed collaborative memory database. A lightweight retrieval learning module then integrates these items into an informative augmentation embedding that captures both collaborative signals and prediction-refinement cues. Finally, the initial SR prediction is refined via a fusion mechanism that incorporates this embedding. Extensive experiments across five benchmark datasets demonstrate that ReAd consistently outperforms existing SR methods.
Data-Driven Function Calling Improvements in Large Language Model for Online Financial QA
Apr 07, 2026Large language models (LLMs) have been incorporated into numerous industrial applications. Meanwhile, a vast array of API assets is scattered across various functions in the financial domain. An online financial question-answering system can leverage both LLMs and private APIs to provide timely financial analysis and information. The key is equipping the LLM model with function calling capability tailored to a financial scenario. However, a generic LLM requires customized financial APIs to call and struggles to adapt to the financial domain. Additionally, online user queries are diverse and contain out-of-distribution parameters compared with the required function input parameters, which makes it more difficult for a generic LLM to serve online users. In this paper, we propose a data-driven pipeline to enhance function calling in LLM for our online, deployed financial QA, comprising dataset construction, data augmentation, and model training. Specifically, we construct a dataset based on a previous study and update it periodically, incorporating queries and an augmentation method named AugFC. The addition of user query-related samples will \textit{exploit} our financial toolset in a data-driven manner, and AugFC explores the possible parameter values to enhance the diversity of our updated dataset. Then, we train an LLM with a two-step method, which enables the use of our financial functions. Extensive experiments on existing offline datasets, as well as the deployment of an online scenario, illustrate the superiority of our pipeline. The related pipeline has been adopted in the financial QA of YuanBao\footnote{https://yuanbao.tencent.com/chat/}, one of the largest chat platforms in China.
SLSREC: Self-Supervised Contrastive Learning for Adaptive Fusion of Long- and Short-Term User Interests
Apr 06, 2026User interests typically encompass both long-term preferences and short-term intentions, reflecting the dynamic nature of user behaviors across different timeframes. The uneven temporal distribution of user interactions highlights the evolving patterns of interests, making it challenging to accurately capture shifts in interests using comprehensive historical behaviors. To address this, we propose SLSRec, a novel Session-based model with the fusion of Long- and Short-term Recommendations that effectively captures the temporal dynamics of user interests by segmenting historical behaviors over time. Unlike conventional models that combine long- and short-term user interests into a single representation, compromising recommendation accuracy, SLSRec utilizes a self-supervised learning framework to disentangle these two types of interests. A contrastive learning strategy is introduced to ensure accurate calibration of long- and short-term interest representations. Additionally, an attention-based fusion network is designed to adaptively aggregate interest representations, optimizing their integration to enhance recommendation performance. Extensive experiments on three public benchmark datasets demonstrate that SLSRec consistently outperforms state-of-the-art models while exhibiting superior robustness across various scenarios.We will release all source code upon acceptance.
PreferRec: Learning and Transferring Pareto Preferences for Multi-objective Re-ranking
Mar 23, 2026Multi-objective re-ranking has become a critical component of modern multi-stage recommender systems, as it tasked to balance multiple conflicting objectives such as accuracy, diversity, and fairness. Existing multi-objective re-ranking methods typically optimize aggregate objectives at the item level using static or handcrafted preference weights. This design overlooks that users inherently exhibit Pareto-optimal preferences at the intent level, reflecting personalized trade-offs among objectives rather than fixed weight combinations. Moreover, most approaches treat re-ranking task for each user as an isolated problem, and repeatedly learn the preferences from scratch. Such a paradigm not only incurs high computational cost, but also ignores the fact that users often share similar preference trade-off structures across objectives. Inspired by the existence of homogeneous multi-objective optimization spaces where Pareto-optimal patterns are transferable, we propose PreferRec, a novel framework that explicitly models and transfers Pareto preferences across users. Specifically, PreferRec is built upon three tightly coupled components: Preference-Aware Pareto Learning aims to capture user intrinsic trade-offs among multiple conflicting objectives at the intent level. By learning Pareto preference representations from re-ranking populations, this component explicitly models how users prioritize different objectives under diverse contexts. Knowledge-Guided Transfer facilitates efficient cross-user knowledge transfer by distilling shared optimization patterns across homogeneous optimization spaces. The transferred knowledge is then used to guide solution selection and personalized re-ranking, biasing the optimization process toward high-quality regions of the Pareto front while preserving user-specific preference characteristics.
Efficient Long-Sequence Diffusion Modeling for Symbolic Music Generation
Feb 28, 2026Symbolic music generation is a challenging task in multimedia generation, involving long sequences with hierarchical temporal structures, long-range dependencies, and fine-grained local details. Though recent diffusion-based models produce high quality generations, they tend to suffer from high training and inference costs with long symbolic sequences due to iterative denoising and sequence-length-related costs. To deal with such problem, we put forth a diffusing strategy named SMDIM to combine efficient global structure construction and light local refinement. SMDIM uses structured state space models to capture long range musical context at near linear cost, and selectively refines local musical details via a hybrid refinement scheme. Experiments performed on a wide range of symbolic music datasets which encompass various Western classical music, popular music and traditional folk music show that the SMDIM model outperforms the other state-of-the-art approaches on both the generation quality and the computational efficiency, and it has robust generalization to underexplored musical styles. These results show that SMDIM offers a principled solution for long-sequence symbolic music generation, including associated attributes that accompany the sequences. We provide a project webpage with audio examples and supplementary materials at https://3328702107.github.io/smdim-music/.
Give Users the Wheel: Towards Promptable Recommendation Paradigm
Feb 21, 2026Conventional sequential recommendation models have achieved remarkable success in mining implicit behavioral patterns. However, these architectures remain structurally blind to explicit user intent: they struggle to adapt when a user's immediate goal (e.g., expressed via a natural language prompt) deviates from their historical habits. While Large Language Models (LLMs) offer the semantic reasoning to interpret such intent, existing integration paradigms force a dilemma: LLM-as-a-recommender paradigm sacrifices the efficiency and collaborative precision of ID-based retrieval, while Reranking methods are inherently bottlenecked by the recall capabilities of the underlying model. In this paper, we propose Decoupled Promptable Sequential Recommendation (DPR), a model-agnostic framework that empowers conventional sequential backbones to natively support Promptable Recommendation, the ability to dynamically steer the retrieval process using natural language without abandoning collaborative signals. DPR modulates the latent user representation directly within the retrieval space. To achieve this, we introduce a Fusion module to align the collaborative and semantic signals, a Mixture-of-Experts (MoE) architecture that disentangles the conflicting gradients from positive and negative steering, and a three-stage training strategy that progressively aligns the semantic space of prompts with the collaborative space. Extensive experiments on real-world datasets demonstrate that DPR significantly outperforms state-of-the-art baselines in prompt-guided tasks while maintaining competitive performance in standard sequential recommendation scenarios.
Tutti: Expressive Multi-Singer Synthesis via Structure-Level Timbre Control and Vocal Texture Modeling
Feb 09, 2026While existing Singing Voice Synthesis systems achieve high-fidelity solo performances, they are constrained by global timbre control, failing to address dynamic multi-singer arrangement and vocal texture within a single song. To address this, we propose Tutti, a unified framework designed for structured multi-singer generation. Specifically, we introduce a Structure-Aware Singer Prompt to enable flexible singer scheduling evolving with musical structure, and propose Complementary Texture Learning via Condition-Guided VAE to capture implicit acoustic textures (e.g., spatial reverberation and spectral fusion) that are complementary to explicit controls. Experiments demonstrate that Tutti excels in precise multi-singer scheduling and significantly enhances the acoustic realism of choral generation, offering a novel paradigm for complex multi-singer arrangement. Audio samples are available at https://annoauth123-ctrl.github.io/Tutii_Demo/.
Automated Information Flow Selection for Multi-scenario Multi-task Recommendation
Dec 15, 2025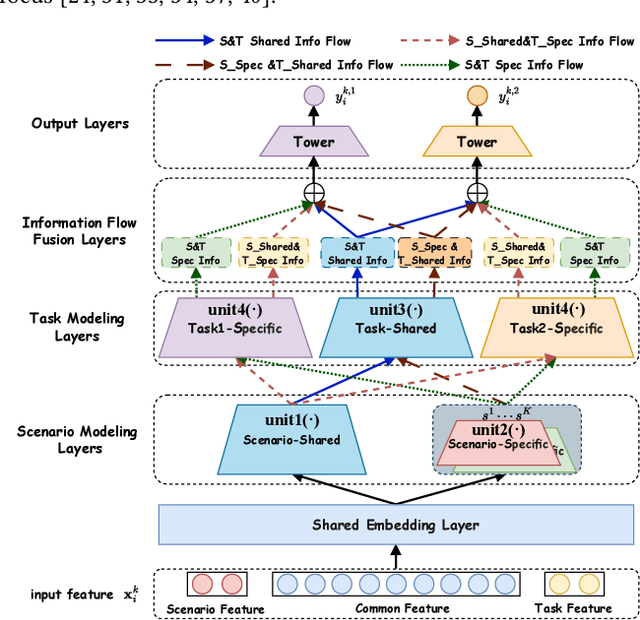
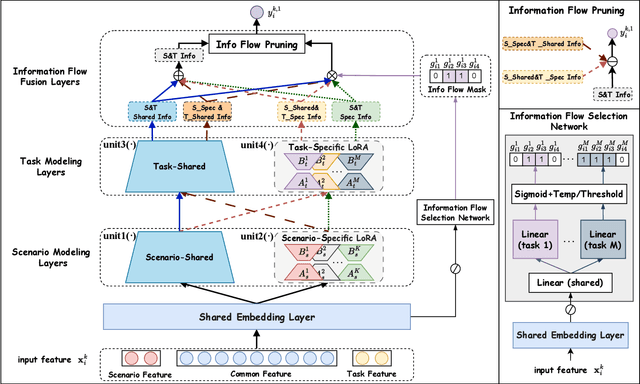
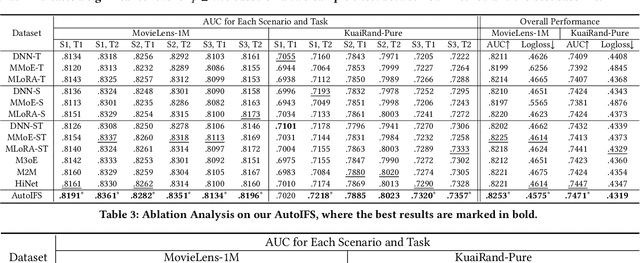
Multi-scenario multi-task recommendation (MSMTR) systems must address recommendation demands across diverse scenarios while simultaneously optimizing multiple objectives, such as click-through rate and conversion rate. Existing MSMTR models typically consist of four information units: scenario-shared, scenario-specific, task-shared, and task-specific networks. These units interact to generate four types of relationship information flows, directed from scenario-shared or scenario-specific networks to task-shared or task-specific networks. However, these models face two main limitations: 1) They often rely on complex architectures, such as mixture-of-experts (MoE) networks, which increase the complexity of information fusion, model size, and training cost. 2) They extract all available information flows without filtering out irrelevant or even harmful content, introducing potential noise. Regarding these challenges, we propose a lightweight Automated Information Flow Selection (AutoIFS) framework for MSMTR. To tackle the first issue, AutoIFS incorporates low-rank adaptation (LoRA) to decouple the four information units, enabling more flexible and efficient information fusion with minimal parameter overhead. To address the second issue, AutoIFS introduces an information flow selection network that automatically filters out invalid scenario-task information flows based on model performance feedback. It employs a simple yet effective pruning function to eliminate useless information flows, thereby enhancing the impact of key relationships and improving model performance. Finally, we evaluate AutoIFS and confirm its effectiveness through extensive experiments on two public benchmark datasets and an online A/B test.
Exploring Test-time Scaling via Prediction Merging on Large-Scale Recommendation
Dec 08, 2025Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.