 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoETTA: Test-Time Adaptation Under Mixed Distribution Shifts with MoE-LayerNorm
Nov 14, 2025Test-Time adaptation (TTA) has proven effective in mitigating performance drops under single-domain distribution shifts by updating model parameters during inference. However, real-world deployments often involve mixed distribution shifts, where test samples are affected by diverse and potentially conflicting domain factors, posing significant challenges even for SOTA TTA methods. A key limitation in existing approaches is their reliance on a unified adaptation path, which fails to account for the fact that optimal gradient directions can vary significantly across different domains. Moreover, current benchmarks focus only on synthetic or homogeneous shifts, failing to capture the complexity of real-world heterogeneous mixed distribution shifts. To address this, we propose MoETTA, a novel entropy-based TTA framework that integrates the Mixture-of-Experts (MoE) architecture. Rather than enforcing a single parameter update rule for all test samples, MoETTA introduces a set of structurally decoupled experts, enabling adaptation along diverse gradient directions. This design allows the model to better accommodate heterogeneous shifts through flexible and disentangled parameter updates. To simulate realistic deployment conditions, we introduce two new benchmarks: potpourri and potpourri+. While classical settings focus solely on synthetic corruptions, potpourri encompasses a broader range of domain shifts--including natural, artistic, and adversarial distortions--capturing more realistic deployment challenges. Additionally, potpourri+ further includes source-domain samples to evaluate robustness against catastrophic forgetting. Extensive experiments across three mixed distribution shifts settings show that MoETTA consistently outperforms strong baselines, establishing SOTA performance and highlighting the benefit of modeling multiple adaptation directions via expert-level diversity.
COSMIC: Clique-Oriented Semantic Multi-space Integration for Robust CLIP Test-Time Adaptation
Mar 30, 2025Recent vision-language models (VLMs) face significant challenges in test-time adaptation to novel domains. While cache-based methods show promise by leveraging historical information, they struggle with both caching unreliable feature-label pairs and indiscriminately using single-class information during querying, significantly compromising adaptation accuracy. To address these limitations, we propose COSMIC (Clique-Oriented Semantic Multi-space Integration for CLIP), a robust test-time adaptation framework that enhances adaptability through multi-granular, cross-modal semantic caching and graph-based querying mechanisms. Our framework introduces two key innovations: Dual Semantics Graph (DSG) and Clique Guided Hyper-class (CGH). The Dual Semantics Graph constructs complementary semantic spaces by incorporating textual features, coarse-grained CLIP features, and fine-grained DINOv2 features to capture rich semantic relationships. Building upon these dual graphs, the Clique Guided Hyper-class component leverages structured class relationships to enhance prediction robustness through correlated class selection. Extensive experiments demonstrate COSMIC's superior performance across multiple benchmarks, achieving significant improvements over state-of-the-art methods: 15.81% gain on out-of-distribution tasks and 5.33% on cross-domain generation with CLIP RN-50. Code is available at github.com/hf618/COSMIC.
DTBS: Dual-Teacher Bi-directional Self-training for Domain Adaptation in Nighttime Semantic Segmentation
Jan 02, 2024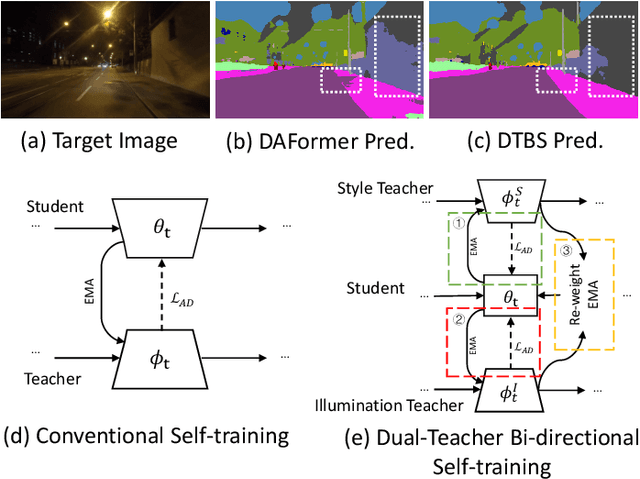
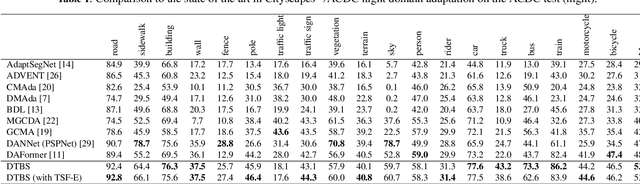
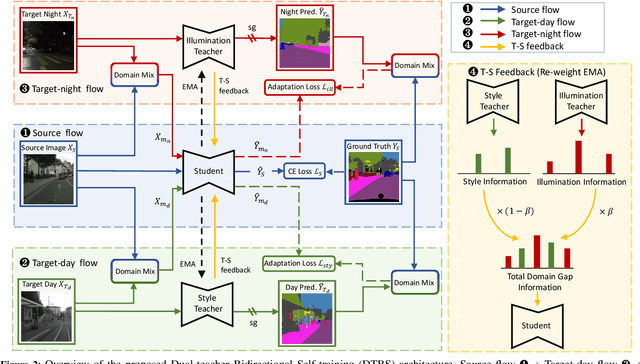
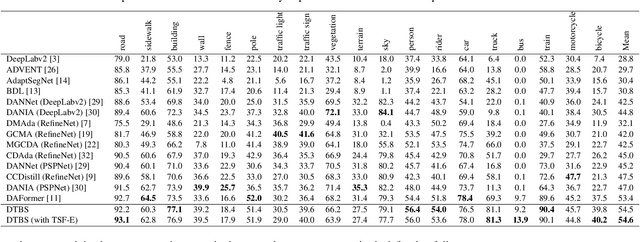
Due to the poor illumination and the difficulty in annotating, nighttime conditions pose a significant challenge for autonomous vehicle perception systems. Unsupervised domain adaptation (UDA) has been widely applied to semantic segmentation on such images to adapt models from normal conditions to target nighttime-condition domains. Self-training (ST) is a paradigm in UDA, where a momentum teacher is utilized for pseudo-label prediction, but a confirmation bias issue exists. Because the one-directional knowledge transfer from a single teacher is insufficient to adapt to a large domain shift. To mitigate this issue, we propose to alleviate domain gap by incrementally considering style influence and illumination change. Therefore, we introduce a one-stage Dual-Teacher Bi-directional Self-training (DTBS) framework for smooth knowledge transfer and feedback. Based on two teacher models, we present a novel pipeline to respectively decouple style and illumination shift. In addition, we propose a new Re-weight exponential moving average (EMA) to merge the knowledge of style and illumination factors, and provide feedback to the student model. In this way, our method can be embedded in other UDA methods to enhance their performance. For example, the Cityscapes to ACDC night task yielded 53.8 mIoU (\%), which corresponds to an improvement of +5\% over the previous state-of-the-art. The code is available at \url{https://github.com/hf618/DTBS}.