 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Foundation Model for Chest Radiography
Sep 04, 2025The scarcity of well-annotated diverse medical images is a major hurdle for developing reliable AI models in healthcare. Substantial technical advances have been made in generative foundation models for natural images. Here we develop `ChexGen', a generative vision-language foundation model that introduces a unified framework for text-, mask-, and bounding box-guided synthesis of chest radiographs. Built upon the latent diffusion transformer architecture, ChexGen was pretrained on the largest curated chest X-ray dataset to date, consisting of 960,000 radiograph-report pairs. ChexGen achieves accurate synthesis of radiographs through expert evaluations and quantitative metrics. We demonstrate the utility of ChexGen for training data augmentation and supervised pretraining, which led to performance improvements across disease classification, detection, and segmentation tasks using a small fraction of training data. Further, our model enables the creation of diverse patient cohorts that enhance model fairness by detecting and mitigating demographic biases. Our study supports the transformative role of generative foundation models in building more accurate, data-efficient, and equitable medical AI systems.
EEG-Driven 3D Object Reconstruction with Color Consistency and Diffusion Prior
Oct 29, 2024



EEG-based visual perception reconstruction has become a current research hotspot. Neuroscientific studies have shown that humans can perceive various types of visual information, such as color, shape, and texture, when observing objects. However, existing technical methods often face issues such as inconsistencies in texture, shape, and color between the visual stimulus images and the reconstructed images. In this paper, we propose a method for reconstructing 3D objects with color consistency based on EEG signals. The method adopts a two-stage strategy: in the first stage, we train an implicit neural EEG encoder with the capability of perceiving 3D objects, enabling it to capture regional semantic features; in the second stage, based on the latent EEG codes obtained in the first stage, we integrate a diffusion model, neural style loss, and NeRF to implicitly decode the 3D objects. Finally, through experimental validation, we demonstrate that our method can reconstruct 3D objects with color consistency using EEG.
DTBS: Dual-Teacher Bi-directional Self-training for Domain Adaptation in Nighttime Semantic Segmentation
Jan 02, 2024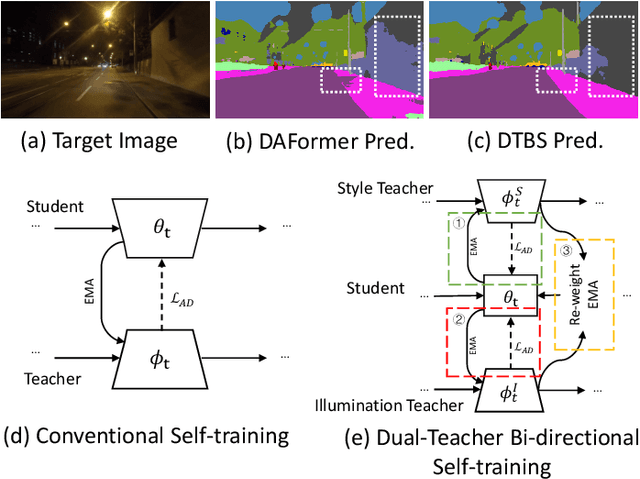
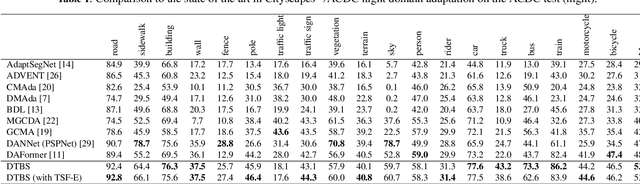
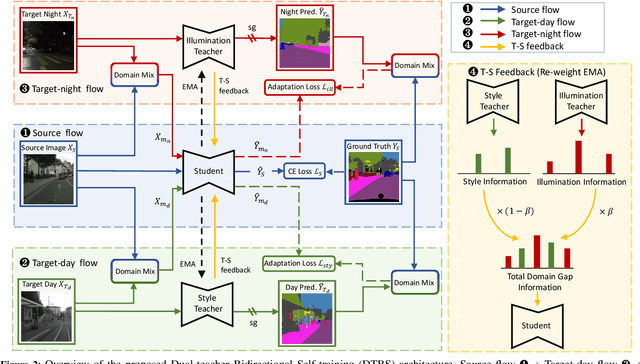
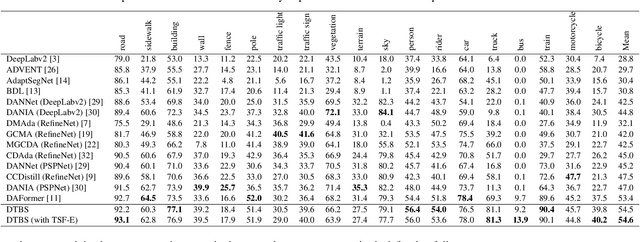
Due to the poor illumination and the difficulty in annotating, nighttime conditions pose a significant challenge for autonomous vehicle perception systems. Unsupervised domain adaptation (UDA) has been widely applied to semantic segmentation on such images to adapt models from normal conditions to target nighttime-condition domains. Self-training (ST) is a paradigm in UDA, where a momentum teacher is utilized for pseudo-label prediction, but a confirmation bias issue exists. Because the one-directional knowledge transfer from a single teacher is insufficient to adapt to a large domain shift. To mitigate this issue, we propose to alleviate domain gap by incrementally considering style influence and illumination change. Therefore, we introduce a one-stage Dual-Teacher Bi-directional Self-training (DTBS) framework for smooth knowledge transfer and feedback. Based on two teacher models, we present a novel pipeline to respectively decouple style and illumination shift. In addition, we propose a new Re-weight exponential moving average (EMA) to merge the knowledge of style and illumination factors, and provide feedback to the student model. In this way, our method can be embedded in other UDA methods to enhance their performance. For example, the Cityscapes to ACDC night task yielded 53.8 mIoU (\%), which corresponds to an improvement of +5\% over the previous state-of-the-art. The code is available at \url{https://github.com/hf618/DTBS}.
Legal Decision-making for Highway Automated Driving
Jul 10, 2023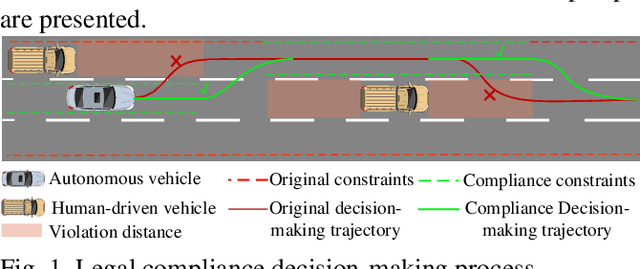
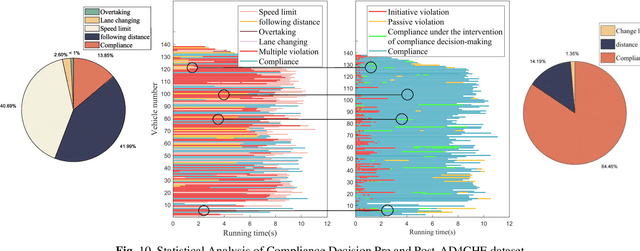
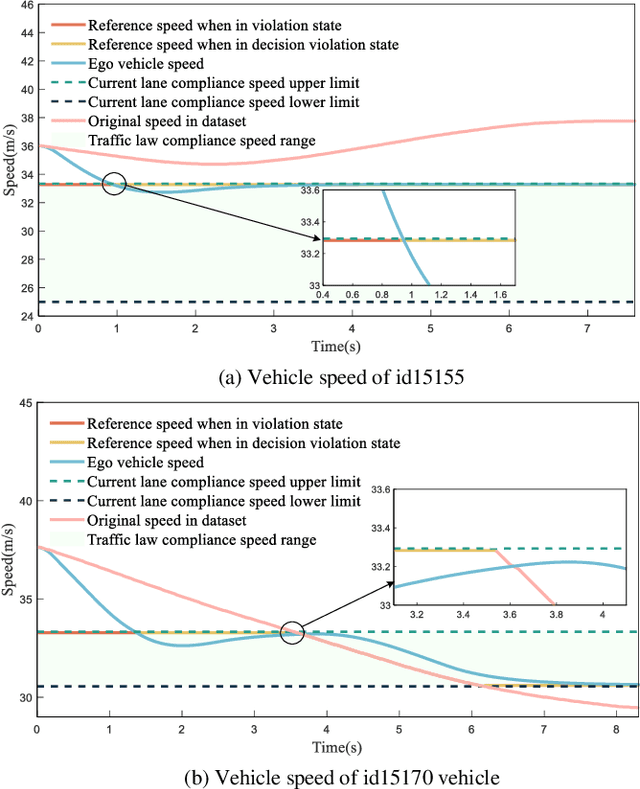
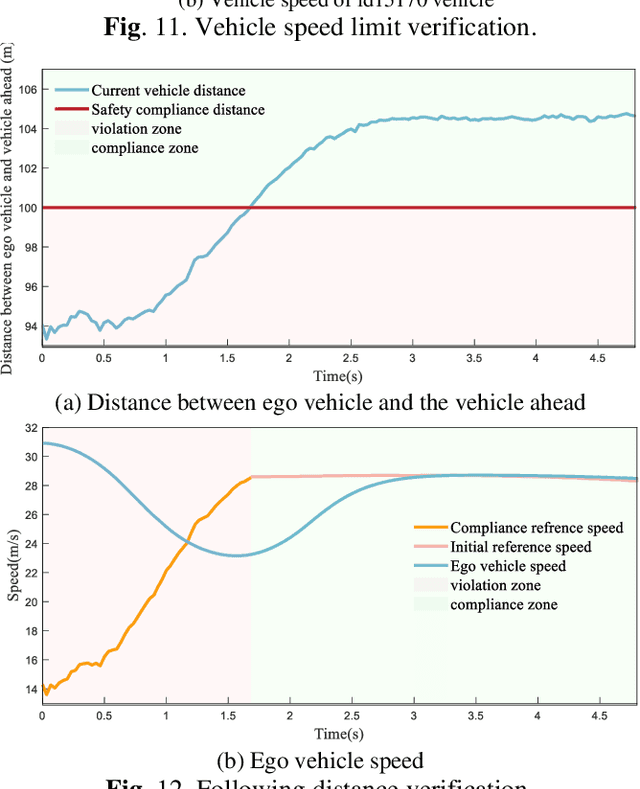
Compliance with traffic laws is a fundamental requirement for human drivers on the road, and autonomous vehicles must adhere to traffic laws as well. However, current autonomous vehicles prioritize safety and collision avoidance primarily in their decision-making and planning, which will lead to misunderstandings and distrust from human drivers and may even result in accidents in mixed traffic flow. Therefore, ensuring the compliance of the autonomous driving decision-making system is essential for ensuring the safety of autonomous driving and promoting the widespread adoption of autonomous driving technology. To this end, the paper proposes a trigger-based layered compliance decision-making framework. This framework utilizes the decision intent at the highest level as a signal to activate an online violation monitor that identifies the type of violation committed by the vehicle. Then, a four-layer architecture for compliance decision-making is employed to generate compliantly trajectories. Using this system, autonomous vehicles can detect and correct potential violations in real-time, thereby enhancing safety and building public confidence in autonomous driving technology. Finally, the proposed method is evaluated on the DJI AD4CHE highway dataset under four typical highway scenarios: speed limit, following distance, overtaking, and lane-changing. The results indicate that the proposed method increases the vehicle's overall compliance rate from 13.85% to 84.46%, while reducing the proportion of active violations to 0%, demonstrating its effectiveness.
PCR-CG: Point Cloud Registration via Deep Color and Geometry
Feb 28, 2023In this paper, we introduce PCR-CG: a novel 3D point cloud registration module explicitly embedding the color signals into the geometry representation. Different from previous methods that only use geometry representation, our module is specifically designed to effectively correlate color into geometry for the point cloud registration task. Our key contribution is a 2D-3D cross-modality learning algorithm that embeds the deep features learned from color signals to the geometry representation. With our designed 2D-3D projection module, the pixel features in a square region centered at correspondences perceived from images are effectively correlated with point clouds. In this way, the overlapped regions can be inferred not only from point cloud but also from the texture appearances. Adding color is non-trivial. We compare against a variety of baselines designed for adding color to 3D, such as exhaustively adding per-pixel features or RGB values in an implicit manner. We leverage Predator [25] as the baseline method and incorporate our proposed module onto it. To validate the effectiveness of 2D features, we ablate different 2D pre-trained networks and show a positive correlation between the pre-trained weights and the task performance. Our experimental results indicate a significant improvement of 6.5% registration recall over the baseline method on the 3DLoMatch benchmark. We additionally evaluate our approach on SOTA methods and observe consistent improvements, such as an improvement of 2.4% registration recall over GeoTransformer as well as 3.5% over CoFiNet. Our study reveals a significant advantages of correlating explicit deep color features to the point cloud in the registration task.
Road Traffic Law Adaptive Decision-making for Self-Driving Vehicles
Apr 26, 2022
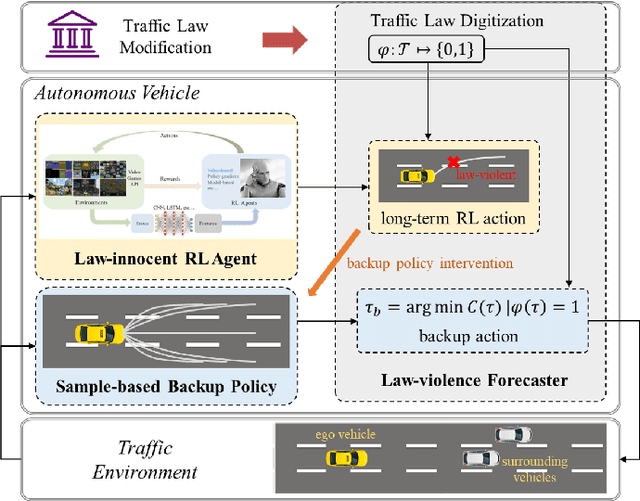
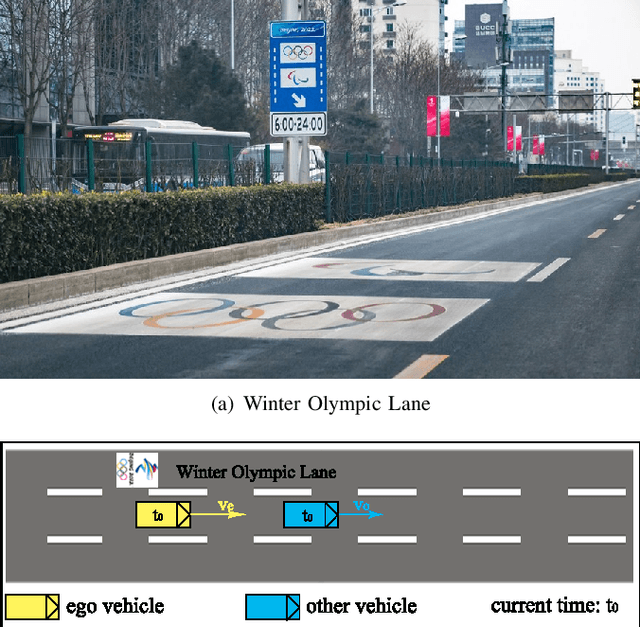
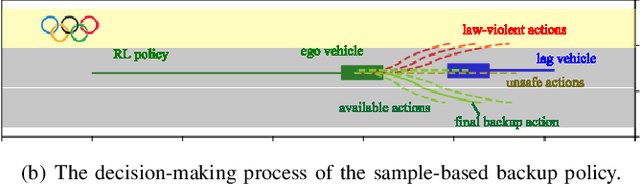
Self-driving vehicles have their own intelligence to drive on open roads. However, vehicle managers, e.g., government or industrial companies, still need a way to tell these self-driving vehicles what behaviors are encouraged or forbidden. Unlike human drivers, current self-driving vehicles cannot understand the traffic laws, thus rely on the programmers manually writing the corresponding principles into the driving systems. It would be less efficient and hard to adapt some temporary traffic laws, especially when the vehicles use data-driven decision-making algorithms. Besides, current self-driving vehicle systems rarely take traffic law modification into consideration. This work aims to design a road traffic law adaptive decision-making method. The decision-making algorithm is designed based on reinforcement learning, in which the traffic rules are usually implicitly coded in deep neural networks. The main idea is to supply the adaptability to traffic laws of self-driving vehicles by a law-adaptive backup policy. In this work, the natural language-based traffic laws are first translated into a logical expression by the Linear Temporal Logic method. Then, the system will try to monitor in advance whether the self-driving vehicle may break the traffic laws by designing a long-term RL action space. Finally, a sample-based planning method will re-plan the trajectory when the vehicle may break the traffic rules. The method is validated in a Beijing Winter Olympic Lane scenario and an overtaking case, built in CARLA simulator. The results show that by adopting this method, the self-driving vehicles can comply with new issued or updated traffic laws effectively. This method helps self-driving vehicles governed by digital traffic laws, which is necessary for the wide adoption of autonomous driving.
Revisiting Rubik's Cube: Self-supervised Learning with Volume-wise Transformation for 3D Medical Image Segmentation
Jul 17, 2020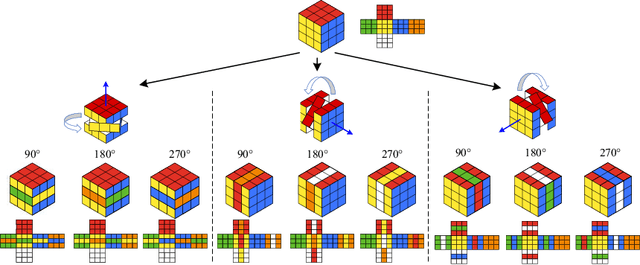
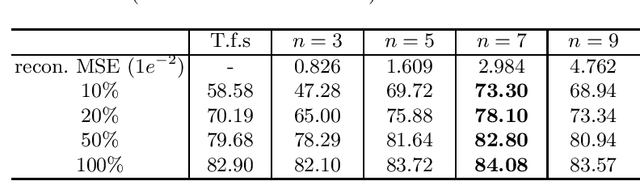
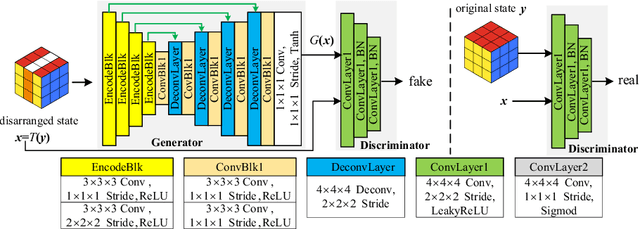
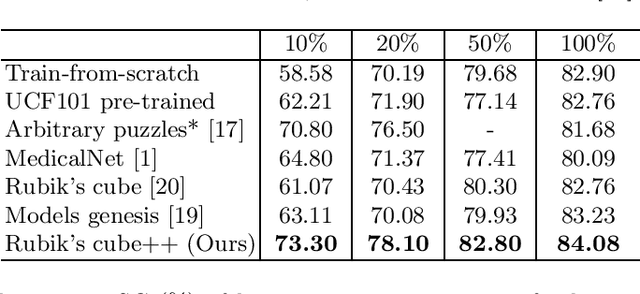
Deep learning highly relies on the quantity of annotated data. However, the annotations for 3D volumetric medical data require experienced physicians to spend hours or even days for investigation. Self-supervised learning is a potential solution to get rid of the strong requirement of training data by deeply exploiting raw data information. In this paper, we propose a novel self-supervised learning framework for volumetric medical images. Specifically, we propose a context restoration task, i.e., Rubik's cube++, to pre-train 3D neural networks. Different from the existing context-restoration-based approaches, we adopt a volume-wise transformation for context permutation, which encourages network to better exploit the inherent 3D anatomical information of organs. Compared to the strategy of training from scratch, fine-tuning from the Rubik's cube++ pre-trained weight can achieve better performance in various tasks such as pancreas segmentation and brain tissue segmentation. The experimental results show that our self-supervised learning method can significantly improve the accuracy of 3D deep learning networks on volumetric medical datasets without the use of extra data.