 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Single-Multi Evolution Loop for Self-Improving Model Collaboration Systems
Feb 05, 2026Model collaboration -- systems where multiple language models (LMs) collaborate -- combines the strengths of diverse models with cost in loading multiple LMs. We improve efficiency while preserving the strengths of collaboration by distilling collaborative patterns into a single model, where the model is trained on the outputs of the model collaboration system. At inference time, only the distilled model is employed: it imitates the collaboration while only incurring the cost of a single model. Furthermore, we propose the single-multi evolution loop: multiple LMs collaborate, each distills from the collaborative outputs, and these post-distillation improved LMs collaborate again, forming a collective evolution ecosystem where models evolve and self-improve by interacting with an environment of other models. Extensive experiments with 7 collaboration strategies and 15 tasks (QA, reasoning, factuality, etc.) demonstrate that: 1) individual models improve by 8.0% on average, absorbing the strengths of collaboration while reducing the cost to a single model; 2) the collaboration also benefits from the stronger and more synergistic LMs after distillation, improving over initial systems without evolution by 14.9% on average. Analysis reveals that the single-multi evolution loop outperforms various existing evolutionary AI methods, is compatible with diverse model/collaboration/distillation settings, and helps solve problems where the initial model/system struggles to.
Probability-Entropy Calibration: An Elastic Indicator for Adaptive Fine-tuning
Feb 02, 2026Token-level reweighting is a simple yet effective mechanism for controlling supervised fine-tuning, but common indicators are largely one-dimensional: the ground-truth probability reflects downstream alignment, while token entropy reflects intrinsic uncertainty induced by the pre-training prior. Ignoring entropy can misidentify noisy or easily replaceable tokens as learning-critical, while ignoring probability fails to reflect target-specific alignment. RankTuner introduces a probability--entropy calibration signal, the Relative Rank Indicator, which compares the rank of the ground-truth token with its expected rank under the prediction distribution. The inverse indicator is used as a token-wise Relative Scale to reweight the fine-tuning objective, focusing updates on truly under-learned tokens without over-penalizing intrinsically uncertain positions. Experiments on multiple backbones show consistent improvements on mathematical reasoning benchmarks, transfer gains on out-of-distribution reasoning, and pre code generation performance over probability-only or entropy-only reweighting baselines.
Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning
Dec 17, 2025
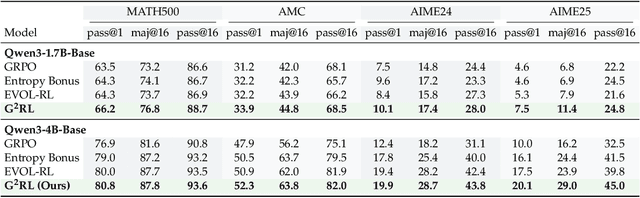
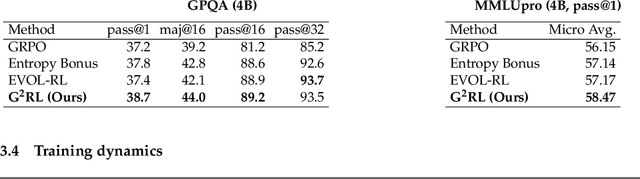
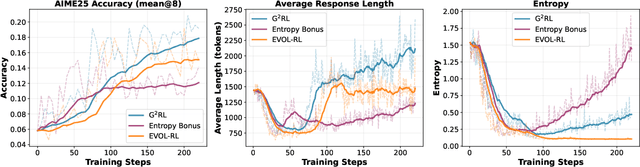
Reinforcement learning has become essential for strengthening the reasoning abilities of large language models, yet current exploration mechanisms remain fundamentally misaligned with how these models actually learn. Entropy bonuses and external semantic comparators encourage surface level variation but offer no guarantee that sampled trajectories differ in the update directions that shape optimization. We propose G2RL, a gradient guided reinforcement learning framework in which exploration is driven not by external heuristics but by the model own first order update geometry. For each response, G2RL constructs a sequence level feature from the model final layer sensitivity, obtainable at negligible cost from a standard forward pass, and measures how each trajectory would reshape the policy by comparing these features within a sampled group. Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler, while redundant or off manifold updates are deemphasized, yielding a self referential exploration signal that is naturally aligned with PPO style stability and KL control. Across math and general reasoning benchmarks (MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) on Qwen3 base 1.7B and 4B models, G2RL consistently improves pass@1, maj@16, and pass@k over entropy based GRPO and external embedding methods. Analyzing the induced geometry, we find that G2RL expands exploration into substantially more orthogonal and often opposing gradient directions while maintaining semantic coherence, revealing that a policy own update space provides a far more faithful and effective basis for guiding exploration in large language model reinforcement learning.
MotionEdit: Benchmarking and Learning Motion-Centric Image Editing
Dec 14, 2025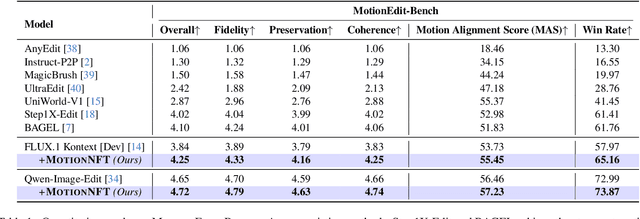

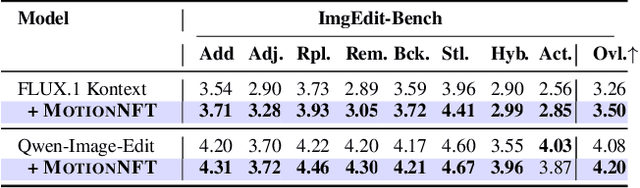

We introduce MotionEdit, a novel dataset for motion-centric image editing-the task of modifying subject actions and interactions while preserving identity, structure, and physical plausibility. Unlike existing image editing datasets that focus on static appearance changes or contain only sparse, low-quality motion edits, MotionEdit provides high-fidelity image pairs depicting realistic motion transformations extracted and verified from continuous videos. This new task is not only scientifically challenging but also practically significant, powering downstream applications such as frame-controlled video synthesis and animation. To evaluate model performance on the novel task, we introduce MotionEdit-Bench, a benchmark that challenges models on motion-centric edits and measures model performance with generative, discriminative, and preference-based metrics. Benchmark results reveal that motion editing remains highly challenging for existing state-of-the-art diffusion-based editing models. To address this gap, we propose MotionNFT (Motion-guided Negative-aware Fine Tuning), a post-training framework that computes motion alignment rewards based on how well the motion flow between input and model-edited images matches the ground-truth motion, guiding models toward accurate motion transformations. Extensive experiments on FLUX.1 Kontext and Qwen-Image-Edit show that MotionNFT consistently improves editing quality and motion fidelity of both base models on the motion editing task without sacrificing general editing ability, demonstrating its effectiveness. Our code is at https://github.com/elainew728/motion-edit/.
Evaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
Modified-Emergency Index (MEI): A Criticality Metric for Autonomous Driving in Lateral Conflict
Oct 31, 2025Effective, reliable, and efficient evaluation of autonomous driving safety is essential to demonstrate its trustworthiness. Criticality metrics provide an objective means of assessing safety. However, as existing metrics primarily target longitudinal conflicts, accurately quantifying the risks of lateral conflicts - prevalent in urban settings - remains challenging. This paper proposes the Modified-Emergency Index (MEI), a metric designed to quantify evasive effort in lateral conflicts. Compared to the original Emergency Index (EI), MEI refines the estimation of the time available for evasive maneuvers, enabling more precise risk quantification. We validate MEI on a public lateral conflict dataset based on Argoverse-2, from which we extract over 1,500 high-quality AV conflict cases, including more than 500 critical events. MEI is then compared with the well-established ACT and the widely used PET metrics. Results show that MEI consistently outperforms them in accurately quantifying criticality and capturing risk evolution. Overall, these findings highlight MEI as a promising metric for evaluating urban conflicts and enhancing the safety assessment framework for autonomous driving. The open-source implementation is available at https://github.com/AutoChengh/MEI.
Understanding and Enhancing Mamba-Transformer Hybrids for Memory Recall and Language Modeling
Oct 30, 2025Hybrid models that combine state space models (SSMs) with attention mechanisms have shown strong performance by leveraging the efficiency of SSMs and the high recall ability of attention. However, the architectural design choices behind these hybrid models remain insufficiently understood. In this work, we analyze hybrid architectures through the lens of memory utilization and overall performance, and propose a complementary method to further enhance their effectiveness. We first examine the distinction between sequential and parallel integration of SSM and attention layers. Our analysis reveals several interesting findings, including that sequential hybrids perform better on shorter contexts, whereas parallel hybrids are more effective for longer contexts. We also introduce a data-centric approach of continually training on datasets augmented with paraphrases, which further enhances recall while preserving other capabilities. It generalizes well across different base models and outperforms architectural modifications aimed at enhancing recall. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases.
VOGUE: Guiding Exploration with Visual Uncertainty Improves Multimodal Reasoning
Oct 01, 2025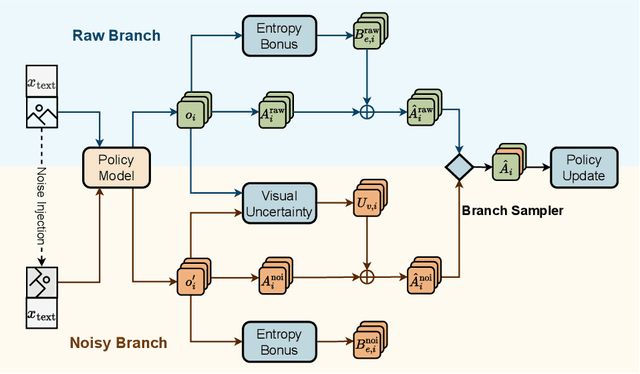
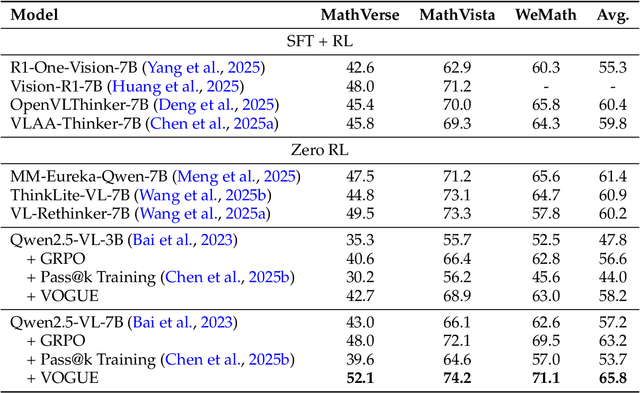
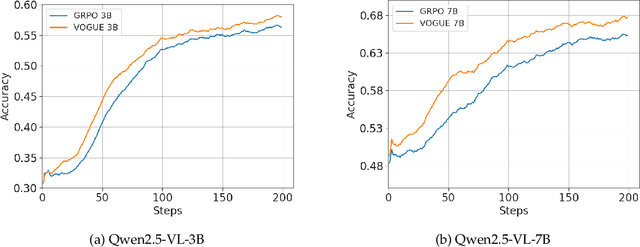
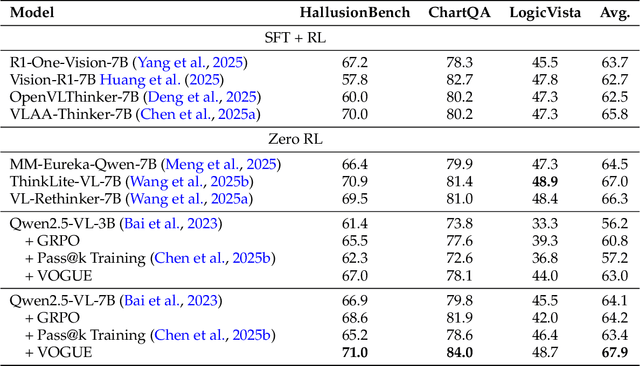
Reinforcement learning with verifiable rewards (RLVR) improves reasoning in large language models (LLMs) but struggles with exploration, an issue that still persists for multimodal LLMs (MLLMs). Current methods treat the visual input as a fixed, deterministic condition, overlooking a critical source of ambiguity and struggling to build policies robust to plausible visual variations. We introduce $\textbf{VOGUE (Visual Uncertainty Guided Exploration)}$, a novel method that shifts exploration from the output (text) to the input (visual) space. By treating the image as a stochastic context, VOGUE quantifies the policy's sensitivity to visual perturbations using the symmetric KL divergence between a "raw" and "noisy" branch, creating a direct signal for uncertainty-aware exploration. This signal shapes the learning objective via an uncertainty-proportional bonus, which, combined with a token-entropy bonus and an annealed sampling schedule, effectively balances exploration and exploitation. Implemented within GRPO on two model scales (Qwen2.5-VL-3B/7B), VOGUE boosts pass@1 accuracy by an average of 2.6% on three visual math benchmarks and 3.7% on three general-domain reasoning benchmarks, while simultaneously increasing pass@4 performance and mitigating the exploration decay commonly observed in RL fine-tuning. Our work shows that grounding exploration in the inherent uncertainty of visual inputs is an effective strategy for improving multimodal reasoning.
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Sep 18, 2025Large language models (LLMs) are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing label-free methods, confidence minimization, self-consistency, or majority-vote objectives, stabilize learning but steadily shrink exploration, causing an entropy collapse: generations become shorter, less diverse, and brittle. Unlike prior approaches such as Test-Time Reinforcement Learning (TTRL), which primarily adapt models to the immediate unlabeled dataset at hand, our goal is broader: to enable general improvements without sacrificing the model's inherent exploration capacity and generalization ability, i.e., evolving. We formalize this issue and propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting. EVOL-RL keeps the majority-voted answer as a stable anchor (selection) while adding a novelty-aware reward that favors responses whose reasoning differs from what has already been produced (variation), measured in semantic space. Implemented with GRPO, EVOL-RL also uses asymmetric clipping to preserve strong signals and an entropy regularizer to sustain search. This majority-for-selection + novelty-for-variation design prevents collapse, maintains longer and more informative chains of thought, and improves both pass@1 and pass@n. EVOL-RL consistently outperforms the majority-only TTRL baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from TTRL's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents diversity collapse but also unlocks stronger generalization across domains (e.g., GPQA). Furthermore, we demonstrate that EVOL-RL also boosts performance in the RLVR setting, highlighting its broad applicability.
Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
Sep 09, 2025Parallel thinking has emerged as a novel approach for enhancing the reasoning capabilities of large language models (LLMs) by exploring multiple reasoning paths concurrently. However, activating such capabilities through training remains challenging, as existing methods predominantly rely on supervised fine-tuning (SFT) over synthetic data, which encourages teacher-forced imitation rather than exploration and generalization. Different from them, we propose \textbf{Parallel-R1}, the first reinforcement learning (RL) framework that enables parallel thinking behaviors for complex real-world reasoning tasks. Our framework employs a progressive curriculum that explicitly addresses the cold-start problem in training parallel thinking with RL. We first use SFT on prompt-generated trajectories from easier tasks to instill the parallel thinking ability, then transition to RL to explore and generalize this skill on harder problems. Experiments on various math benchmarks, including MATH, AMC23, and AIME, show that Parallel-R1 successfully instills parallel thinking, leading to 8.4% accuracy improvements over the sequential thinking model trained directly on challenging tasks with RL. Further analysis reveals a clear shift in the model's thinking behavior: at an early stage, it uses parallel thinking as an exploration strategy, while in a later stage, it uses the same capability for multi-perspective verification. Most significantly, we validate parallel thinking as a \textbf{mid-training exploration scaffold}, where this temporary exploratory phase unlocks a higher performance ceiling after RL, yielding a 42.9% improvement over the baseline on AIME25. Our model, data, and code will be open-source at https://github.com/zhengkid/Parallel-R1.