 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Versatile Humanoid Manipulation with Touch Dreaming
Apr 14, 2026Humanoid robots promise general-purpose assistance, yet real-world humanoid loco-manipulation remains challenging because it requires whole-body stability, dexterous hands, and contact-aware perception under frequent contact changes. In this work, we study dexterous, contact-rich humanoid loco-manipulation. We first develop an RL-based whole-body controller that provides stable lower-body and torso execution during complex manipulation. Built on this controller, we develop a whole-body humanoid data collection system that combines VR-based teleoperation with human-to-humanoid motion mapping, enabling efficient collection of real-world demonstrations. We then propose Humanoid Transformer with Touch Dreaming (HTD), a multimodal encoder--decoder Transformer that models touch as a core modality alongside multi-view vision and proprioception. HTD is trained in a single stage with behavioral cloning augmented by touch dreaming: in addition to predicting action chunks, the policy predicts future hand-joint forces and future tactile latents, encouraging the shared Transformer trunk to learn contact-aware representations for dexterous interaction. Across five contact-rich tasks, Insert-T, Book Organization, Towel Folding, Cat Litter Scooping, and Tea Serving, HTD achieves a 90.9% relative improvement in average success rate over the stronger baseline. Ablation results further show that latent-space tactile prediction is more effective than raw tactile prediction, yielding a 30% relative gain in success rate. These results demonstrate that combining robust whole-body execution, scalable humanoid data collection, and predictive touch-centered learning enables versatile, high-dexterity humanoid manipulation in the real world. Project webpage: humanoid-touch-dream.github.io.
HALyPO: Heterogeneous-Agent Lyapunov Policy Optimization for Human-Robot Collaboration
Mar 04, 2026To improve generalization and resilience in human-robot collaboration (HRC), robots must handle the combinatorial diversity of human behaviors and contexts, motivating multi-agent reinforcement learning (MARL). However, inherent heterogeneity between robots and humans creates a rationality gap (RG) in the learning process-a variational mismatch between decentralized best-response dynamics and centralized cooperative ascent. The resulting learning problem is a general-sum differentiable game, so independent policy-gradient updates can oscillate or diverge without added structure. We propose heterogeneous-agent Lyapunov policy optimization (HALyPO), which establishes formal stability directly in the policy-parameter space by enforcing a per-step Lyapunov decrease condition on a parameter-space disagreement metric. Unlike Lyapunov-based safe RL, which targets state/trajectory constraints in constrained Markov decision processes, HALyPO uses Lyapunov certification to stabilize decentralized policy learning. HALyPO rectifies decentralized gradients via optimal quadratic projections, ensuring monotonic contraction of RG and enabling effective exploration of open-ended interaction spaces. Extensive simulations and real-world humanoid-robot experiments show that this certified stability improves generalization and robustness in collaborative corner cases.
Dexterous Manipulation Policies from RGB Human Videos via 4D Hand-Object Trajectory Reconstruction
Feb 09, 2026Multi-finger robotic hand manipulation and grasping are challenging due to the high-dimensional action space and the difficulty of acquiring large-scale training data. Existing approaches largely rely on human teleoperation with wearable devices or specialized sensing equipment to capture hand-object interactions, which limits scalability. In this work, we propose VIDEOMANIP, a device-free framework that learns dexterous manipulation directly from RGB human videos. Leveraging recent advances in computer vision, VIDEOMANIP reconstructs explicit 4D robot-object trajectories from monocular videos by estimating human hand poses, object meshes, and retargets the reconstructed human motions to robotic hands for manipulation learning. To make the reconstructed robot data suitable for dexterous manipulation training, we introduce hand-object contact optimization with interaction-centric grasp modeling, as well as a demonstration synthesis strategy that generates diverse training trajectories from a single video, enabling generalizable policy learning without additional robot demonstrations. In simulation, the learned grasping model achieves a 70.25% success rate across 20 diverse objects using the Inspire Hand. In the real world, manipulation policies trained from RGB videos achieve an average 62.86% success rate across seven tasks using the LEAP Hand, outperforming retargeting-based methods by 15.87%. Project videos are available at videomanip.github.io.
QuietPaw: Learning Quadrupedal Locomotion with Versatile Noise Preference Alignment
Mar 06, 2025When operating at their full capacity, quadrupedal robots can produce loud footstep noise, which can be disruptive in human-centered environments like homes, offices, and hospitals. As a result, balancing locomotion performance with noise constraints is crucial for the successful real-world deployment of quadrupedal robots. However, achieving adaptive noise control is challenging due to (a) the trade-off between agility and noise minimization, (b) the need for generalization across diverse deployment conditions, and (c) the difficulty of effectively adjusting policies based on noise requirements. We propose QuietPaw, a framework incorporating our Conditional Noise-Constrained Policy (CNCP), a constrained learning-based algorithm that enables flexible, noise-aware locomotion by conditioning policy behavior on noise-reduction levels. We leverage value representation decomposition in the critics, disentangling state representations from condition-dependent representations and this allows a single versatile policy to generalize across noise levels without retraining while improving the Pareto trade-off between agility and noise reduction. We validate our approach in simulation and the real world, demonstrating that CNCP can effectively balance locomotion performance and noise constraints, achieving continuously adjustable noise reduction.
Learning Multi-Agent Loco-Manipulation for Long-Horizon Quadrupedal Pushing
Nov 14, 2024Recently, quadrupedal locomotion has achieved significant success, but their manipulation capabilities, particularly in handling large objects, remain limited, restricting their usefulness in demanding real-world applications such as search and rescue, construction, industrial automation, and room organization. This paper tackles the task of obstacle-aware, long-horizon pushing by multiple quadrupedal robots. We propose a hierarchical multi-agent reinforcement learning framework with three levels of control. The high-level controller integrates an RRT planner and a centralized adaptive policy to generate subgoals, while the mid-level controller uses a decentralized goal-conditioned policy to guide the robots toward these sub-goals. A pre-trained low-level locomotion policy executes the movement commands. We evaluate our method against several baselines in simulation, demonstrating significant improvements over baseline approaches, with 36.0% higher success rates and 24.5% reduction in completion time than the best baseline. Our framework successfully enables long-horizon, obstacle-aware manipulation tasks like Push-Cuboid and Push-T on Go1 robots in the real world.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024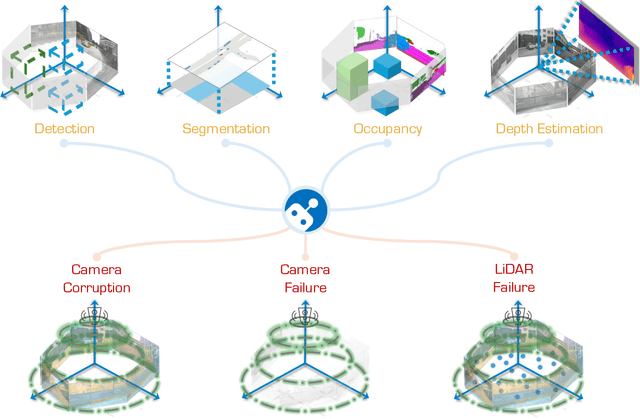


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
LocoMan: Advancing Versatile Quadrupedal Dexterity with Lightweight Loco-Manipulators
Mar 27, 2024



Quadrupedal robots have emerged as versatile agents capable of locomoting and manipulating in complex environments. Traditional designs typically rely on the robot's inherent body parts or incorporate top-mounted arms for manipulation tasks. However, these configurations may limit the robot's operational dexterity, efficiency and adaptability, particularly in cluttered or constrained spaces. In this work, we present LocoMan, a dexterous quadrupedal robot with a novel morphology to perform versatile manipulation in diverse constrained environments. By equipping a Unitree Go1 robot with two low-cost and lightweight modular 3-DoF loco-manipulators on its front calves, LocoMan leverages the combined mobility and functionality of the legs and grippers for complex manipulation tasks that require precise 6D positioning of the end effector in a wide workspace. To harness the loco-manipulation capabilities of LocoMan, we introduce a unified control framework that extends the whole-body controller (WBC) to integrate the dynamics of loco-manipulators. Through experiments, we validate that the proposed whole-body controller can accurately and stably follow desired 6D trajectories of the end effector and torso, which, when combined with the large workspace from our design, facilitates a diverse set of challenging dexterous loco-manipulation tasks in confined spaces, such as opening doors, plugging into sockets, picking objects in narrow and low-lying spaces, and bimanual manipulation.
Interpretable Reinforcement Learning for Robotics and Continuous Control
Nov 16, 2023



Interpretability in machine learning is critical for the safe deployment of learned policies across legally-regulated and safety-critical domains. While gradient-based approaches in reinforcement learning have achieved tremendous success in learning policies for continuous control problems such as robotics and autonomous driving, the lack of interpretability is a fundamental barrier to adoption. We propose Interpretable Continuous Control Trees (ICCTs), a tree-based model that can be optimized via modern, gradient-based, reinforcement learning approaches to produce high-performing, interpretable policies. The key to our approach is a procedure for allowing direct optimization in a sparse decision-tree-like representation. We validate ICCTs against baselines across six domains, showing that ICCTs are capable of learning policies that parity or outperform baselines by up to 33% in autonomous driving scenarios while achieving a 300x-600x reduction in the number of parameters against deep learning baselines. We prove that ICCTs can serve as universal function approximators and display analytically that ICCTs can be verified in linear time. Furthermore, we deploy ICCTs in two realistic driving domains, based on interstate Highway-94 and 280 in the US. Finally, we verify ICCT's utility with end-users and find that ICCTs are rated easier to simulate, quicker to validate, and more interpretable than neural networks.
Safety-aware Causal Representation for Trustworthy Reinforcement Learning in Autonomous Driving
Oct 31, 2023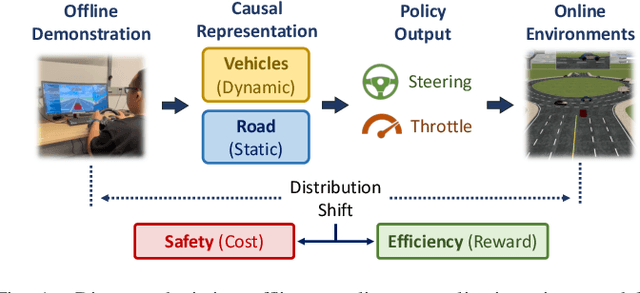
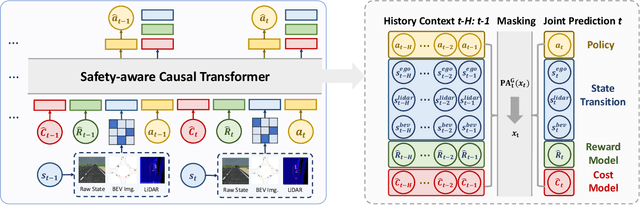
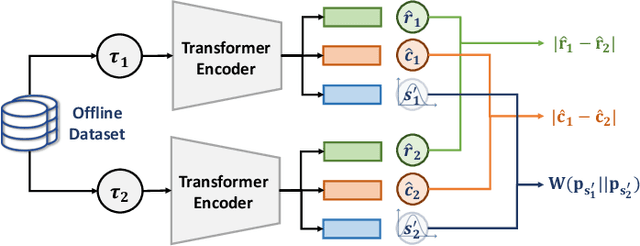

In the domain of autonomous driving, the Learning from Demonstration (LfD) paradigm has exhibited notable efficacy in addressing sequential decision-making problems. However, consistently achieving safety in varying traffic contexts, especially in safety-critical scenarios, poses a significant challenge due to the long-tailed and unforeseen scenarios absent from offline datasets. In this paper, we introduce the saFety-aware strUctured Scenario representatION (FUSION), a pioneering methodology conceived to facilitate the learning of an adaptive end-to-end driving policy by leveraging structured scenario information. FUSION capitalizes on the causal relationships between decomposed reward, cost, state, and action space, constructing a framework for structured sequential reasoning under dynamic traffic environments. We conduct rigorous evaluations in two typical real-world settings of distribution shift in autonomous vehicles, demonstrating the good balance between safety cost and utility reward of FUSION compared to contemporary state-of-the-art safety-aware LfD baselines. Empirical evidence under diverse driving scenarios attests that FUSION significantly enhances the safety and generalizability of autonomous driving agents, even in the face of challenging and unseen environments. Furthermore, our ablation studies reveal noticeable improvements in the integration of causal representation into the safe offline RL problem.
Creative Robot Tool Use with Large Language Models
Oct 19, 2023



Tool use is a hallmark of advanced intelligence, exemplified in both animal behavior and robotic capabilities. This paper investigates the feasibility of imbuing robots with the ability to creatively use tools in tasks that involve implicit physical constraints and long-term planning. Leveraging Large Language Models (LLMs), we develop RoboTool, a system that accepts natural language instructions and outputs executable code for controlling robots in both simulated and real-world environments. RoboTool incorporates four pivotal components: (i) an "Analyzer" that interprets natural language to discern key task-related concepts, (ii) a "Planner" that generates comprehensive strategies based on the language input and key concepts, (iii) a "Calculator" that computes parameters for each skill, and (iv) a "Coder" that translates these plans into executable Python code. Our results show that RoboTool can not only comprehend explicit or implicit physical constraints and environmental factors but also demonstrate creative tool use. Unlike traditional Task and Motion Planning (TAMP) methods that rely on explicit optimization, our LLM-based system offers a more flexible, efficient, and user-friendly solution for complex robotics tasks. Through extensive experiments, we validate that RoboTool is proficient in handling tasks that would otherwise be infeasible without the creative use of tools, thereby expanding the capabilities of robotic systems. Demos are available on our project page: https://creative-robotool.github.io/.