 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Rapid Shared Human-AI Mental Model Alignment via the After-Action Review
Mar 25, 2025In this work, we present two novel contributions toward improving research in human-machine teaming (HMT): 1) a Minecraft testbed to accelerate testing and deployment of collaborative AI agents and 2) a tool to allow users to revisit and analyze behaviors within an HMT episode to facilitate shared mental model development. Our browser-based Minecraft testbed allows for rapid testing of collaborative agents in a continuous-space, real-time, partially-observable environment with real humans without cumbersome setup typical to human-AI interaction user studies. As Minecraft has an extensive player base and a rich ecosystem of pre-built AI agents, we hope this contribution can help to facilitate research quickly in the design of new collaborative agents and in understanding different human factors within HMT. Our mental model alignment tool facilitates user-led post-mission analysis by including video displays of first-person perspectives of the team members (i.e., the human and AI) that can be replayed, and a chat interface that leverages GPT-4 to provide answers to various queries regarding the AI's experiences and model details.
Towards Automated Semantic Interpretability in Reinforcement Learning via Vision-Language Models
Mar 20, 2025Semantic Interpretability in Reinforcement Learning (RL) enables transparency, accountability, and safer deployment by making the agent's decisions understandable and verifiable. Achieving this, however, requires a feature space composed of human-understandable concepts, which traditionally rely on human specification and fail to generalize to unseen environments. In this work, we introduce Semantically Interpretable Reinforcement Learning with Vision-Language Models Empowered Automation (SILVA), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and interpretable tree-based models for policy optimization. SILVA first queries a VLM to identify relevant semantic features for an unseen environment, then extracts these features from the environment. Finally, it trains an Interpretable Control Tree via RL, mapping the extracted features to actions in a transparent and interpretable manner. To address the computational inefficiency of extracting features directly with VLMs, we develop a feature extraction pipeline that generates a dataset for training a lightweight convolutional network, which is subsequently used during RL. By leveraging VLMs to automate tree-based RL, SILVA removes the reliance on human annotation previously required by interpretable models while also overcoming the inability of VLMs alone to generate valid robot policies, enabling semantically interpretable reinforcement learning without human-in-the-loop.
Asynchronous Training of Mixed-Role Human Actors in a Partially-Observable Environment
Dec 23, 2024In cooperative training, humans within a team coordinate on complex tasks, building mental models of their teammates and learning to adapt to teammates' actions in real-time. To reduce the often prohibitive scheduling constraints associated with cooperative training, this article introduces a paradigm for cooperative asynchronous training of human teams in which trainees practice coordination with autonomous teammates rather than humans. We introduce a novel experimental design for evaluating autonomous teammates for use as training partners in cooperative training. We apply the design to a human-subjects experiment where humans are trained with either another human or an autonomous teammate and are evaluated with a new human subject in a new, partially observable, cooperative game developed for this study. Importantly, we employ a method to cluster teammate trajectories from demonstrations performed in the experiment to form a smaller number of training conditions. This results in a simpler experiment design that enabled us to conduct a complex cooperative training human-subjects study in a reasonable amount of time. Through a demonstration of the proposed experimental design, we provide takeaways and design recommendations for future research in the development of cooperative asynchronous training systems utilizing robot surrogates for human teammates.
Faster Model Predictive Control via Self-Supervised Initialization Learning
Aug 06, 2024



Optimization for robot control tasks, spanning various methodologies, includes Model Predictive Control (MPC). However, the complexity of the system, such as non-convex and non-differentiable cost functions and prolonged planning horizons often drastically increases the computation time, limiting MPC's real-world applicability. Prior works in speeding up the optimization have limitations on solving convex problem and generalizing to hold out domains. To overcome this challenge, we develop a novel framework aiming at expediting optimization processes. In our framework, we combine offline self-supervised learning and online fine-tuning through reinforcement learning to improve the control performance and reduce optimization time. We demonstrate the effectiveness of our method on a novel, challenging Formula-1-track driving task, achieving 3.9\% higher performance in optimization time and 3.6\% higher performance in tracking accuracy on challenging holdout tracks.
Designs for Enabling Collaboration in Human-Machine Teaming via Interactive and Explainable Systems
Jun 07, 2024Collaborative robots and machine learning-based virtual agents are increasingly entering the human workspace with the aim of increasing productivity and enhancing safety. Despite this, we show in a ubiquitous experimental domain, Overcooked-AI, that state-of-the-art techniques for human-machine teaming (HMT), which rely on imitation or reinforcement learning, are brittle and result in a machine agent that aims to decouple the machine and human's actions to act independently rather than in a synergistic fashion. To remedy this deficiency, we develop HMT approaches that enable iterative, mixed-initiative team development allowing end-users to interactively reprogram interpretable AI teammates. Our 50-subject study provides several findings that we summarize into guidelines. While all approaches underperform a simple collaborative heuristic (a critical, negative result for learning-based methods), we find that white-box approaches supported by interactive modification can lead to significant team development, outperforming white-box approaches alone, and black-box approaches are easier to train and result in better HMT performance highlighting a tradeoff between explainability and interactivity versus ease-of-training. Together, these findings present three important directions: 1) Improving the ability to generate collaborative agents with white-box models, 2) Better learning methods to facilitate collaboration rather than individualized coordination, and 3) Mixed-initiative interfaces that enable users, who may vary in ability, to improve collaboration.
Why Would You Suggest That? Human Trust in Language Model Responses
Jun 04, 2024
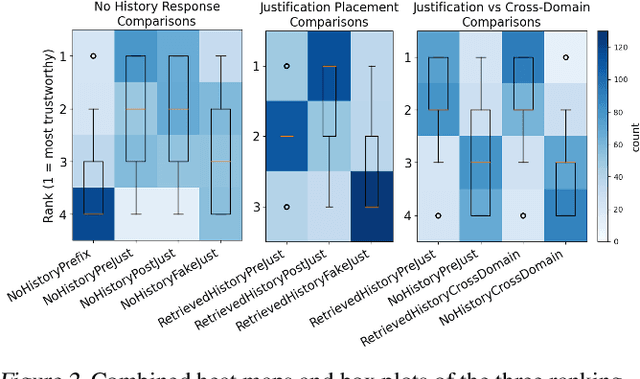

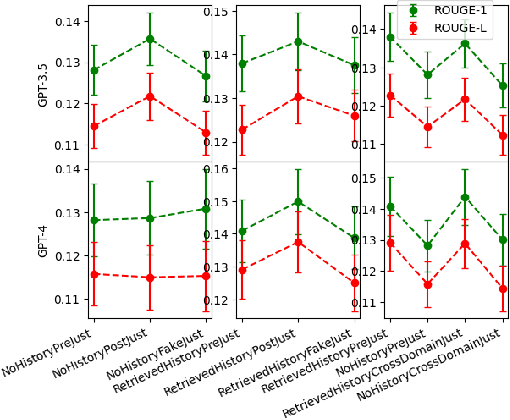
The emergence of Large Language Models (LLMs) has revealed a growing need for human-AI collaboration, especially in creative decision-making scenarios where trust and reliance are paramount. Through human studies and model evaluations on the open-ended News Headline Generation task from the LaMP benchmark, we analyze how the framing and presence of explanations affect user trust and model performance. Overall, we provide evidence that adding an explanation in the model response to justify its reasoning significantly increases self-reported user trust in the model when the user has the opportunity to compare various responses. Position and faithfulness of these explanations are also important factors. However, these gains disappear when users are shown responses independently, suggesting that humans trust all model responses, including deceptive ones, equitably when they are shown in isolation. Our findings urge future research to delve deeper into the nuanced evaluation of trust in human-machine teaming systems.
Interpretable Reinforcement Learning for Robotics and Continuous Control
Nov 16, 2023



Interpretability in machine learning is critical for the safe deployment of learned policies across legally-regulated and safety-critical domains. While gradient-based approaches in reinforcement learning have achieved tremendous success in learning policies for continuous control problems such as robotics and autonomous driving, the lack of interpretability is a fundamental barrier to adoption. We propose Interpretable Continuous Control Trees (ICCTs), a tree-based model that can be optimized via modern, gradient-based, reinforcement learning approaches to produce high-performing, interpretable policies. The key to our approach is a procedure for allowing direct optimization in a sparse decision-tree-like representation. We validate ICCTs against baselines across six domains, showing that ICCTs are capable of learning policies that parity or outperform baselines by up to 33% in autonomous driving scenarios while achieving a 300x-600x reduction in the number of parameters against deep learning baselines. We prove that ICCTs can serve as universal function approximators and display analytically that ICCTs can be verified in linear time. Furthermore, we deploy ICCTs in two realistic driving domains, based on interstate Highway-94 and 280 in the US. Finally, we verify ICCT's utility with end-users and find that ICCTs are rated easier to simulate, quicker to validate, and more interpretable than neural networks.
Learning Models of Adversarial Agent Behavior under Partial Observability
Jul 05, 2023The need for opponent modeling and tracking arises in several real-world scenarios, such as professional sports, video game design, and drug-trafficking interdiction. In this work, we present Graph based Adversarial Modeling with Mutal Information (GrAMMI) for modeling the behavior of an adversarial opponent agent. GrAMMI is a novel graph neural network (GNN) based approach that uses mutual information maximization as an auxiliary objective to predict the current and future states of an adversarial opponent with partial observability. To evaluate GrAMMI, we design two large-scale, pursuit-evasion domains inspired by real-world scenarios, where a team of heterogeneous agents is tasked with tracking and interdicting a single adversarial agent, and the adversarial agent must evade detection while achieving its own objectives. With the mutual information formulation, GrAMMI outperforms all baselines in both domains and achieves 31.68% higher log-likelihood on average for future adversarial state predictions across both domains.
Adversarial Search and Track with Multiagent Reinforcement Learning in Sparsely Observable Environment
Jun 20, 2023We study a search and tracking (S&T) problem for a team of dynamic search agents to capture an adversarial evasive agent with only sparse temporal and spatial knowledge of its location in this paper. The domain is challenging for traditional Reinforcement Learning (RL) approaches as the large space leads to sparse observations of the adversary and in turn sparse rewards for the search agents. Additionally, the opponent's behavior is reactionary to the search agents, which causes a data distribution shift for RL during training as search agents improve their policies. We propose a differentiable Multi-Agent RL (MARL) architecture that utilizes a novel filtering module to supplement estimated adversary location information and enables the effective learning of a team policy. Our algorithm learns how to balance information from prior knowledge and a motion model to remain resilient to the data distribution shift and outperforms all baseline methods with a 46% increase of detection rate.
The Effect of Robot Skill Level and Communication in Rapid, Proximate Human-Robot Collaboration
Apr 07, 2023As high-speed, agile robots become more commonplace, these robots will have the potential to better aid and collaborate with humans. However, due to the increased agility and functionality of these robots, close collaboration with humans can create safety concerns that alter team dynamics and degrade task performance. In this work, we aim to enable the deployment of safe and trustworthy agile robots that operate in proximity with humans. We do so by 1) Proposing a novel human-robot doubles table tennis scenario to serve as a testbed for studying agile, proximate human-robot collaboration and 2) Conducting a user-study to understand how attributes of the robot (e.g., robot competency or capacity to communicate) impact team dynamics, perceived safety, and perceived trust, and how these latent factors affect human-robot collaboration (HRC) performance. We find that robot competency significantly increases perceived trust ($p<.001$), extending skill-to-trust assessments in prior studies to agile, proximate HRC. Furthermore, interestingly, we find that when the robot vocalizes its intention to perform a task, it results in a significant decrease in team performance ($p=.037$) and perceived safety of the system ($p=.009$).