 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference of Human-derived Specifications of Object Placement via Demonstration
Aug 26, 2025As robots' manipulation capabilities improve for pick-and-place tasks (e.g., object packing, sorting, and kitting), methods focused on understanding human-acceptable object configurations remain limited expressively with regard to capturing spatial relationships important to humans. To advance robotic understanding of human rules for object arrangement, we introduce positionally-augmented RCC (PARCC), a formal logic framework based on region connection calculus (RCC) for describing the relative position of objects in space. Additionally, we introduce an inference algorithm for learning PARCC specifications via demonstrations. Finally, we present the results from a human study, which demonstrate our framework's ability to capture a human's intended specification and the benefits of learning from demonstration approaches over human-provided specifications.
Enabling Rapid Shared Human-AI Mental Model Alignment via the After-Action Review
Mar 25, 2025In this work, we present two novel contributions toward improving research in human-machine teaming (HMT): 1) a Minecraft testbed to accelerate testing and deployment of collaborative AI agents and 2) a tool to allow users to revisit and analyze behaviors within an HMT episode to facilitate shared mental model development. Our browser-based Minecraft testbed allows for rapid testing of collaborative agents in a continuous-space, real-time, partially-observable environment with real humans without cumbersome setup typical to human-AI interaction user studies. As Minecraft has an extensive player base and a rich ecosystem of pre-built AI agents, we hope this contribution can help to facilitate research quickly in the design of new collaborative agents and in understanding different human factors within HMT. Our mental model alignment tool facilitates user-led post-mission analysis by including video displays of first-person perspectives of the team members (i.e., the human and AI) that can be replayed, and a chat interface that leverages GPT-4 to provide answers to various queries regarding the AI's experiences and model details.
Accelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Games with Delayed Rewards
Nov 26, 2024
In this paper, we tackle the challenging problem of delayed rewards in reinforcement learning (RL). While Proximal Policy Optimization (PPO) has emerged as a leading Policy Gradient method, its performance can degrade under delayed rewards. We introduce two key enhancements to PPO: a hybrid policy architecture that combines an offline policy (trained on expert demonstrations) with an online PPO policy, and a reward shaping mechanism using Time Window Temporal Logic (TWTL). The hybrid architecture leverages offline data throughout training while maintaining PPO's theoretical guarantees. Building on the monotonic improvement framework of Trust Region Policy Optimization (TRPO), we prove that our approach ensures improvement over both the offline policy and previous iterations, with a bounded performance gap of $(2\varsigma\gamma\alpha^2)/(1-\gamma)^2$, where $\alpha$ is the mixing parameter, $\gamma$ is the discount factor, and $\varsigma$ bounds the expected advantage. Additionally, we prove that our TWTL-based reward shaping preserves the optimal policy of the original problem. TWTL enables formal translation of temporal objectives into immediate feedback signals that guide learning. We demonstrate the effectiveness of our approach through extensive experiments on an inverted pendulum and a lunar lander environments, showing improvements in both learning speed and final performance compared to standard PPO and offline-only approaches.
Why Would You Suggest That? Human Trust in Language Model Responses
Jun 04, 2024
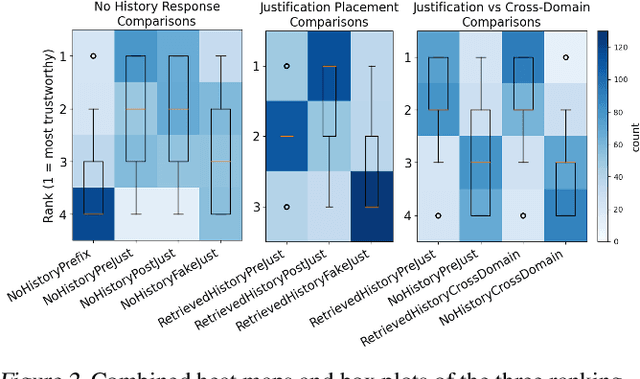

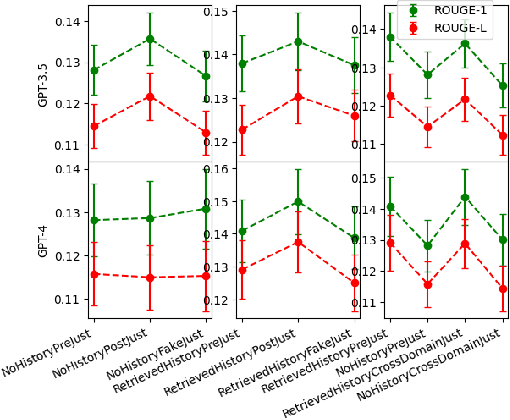
The emergence of Large Language Models (LLMs) has revealed a growing need for human-AI collaboration, especially in creative decision-making scenarios where trust and reliance are paramount. Through human studies and model evaluations on the open-ended News Headline Generation task from the LaMP benchmark, we analyze how the framing and presence of explanations affect user trust and model performance. Overall, we provide evidence that adding an explanation in the model response to justify its reasoning significantly increases self-reported user trust in the model when the user has the opportunity to compare various responses. Position and faithfulness of these explanations are also important factors. However, these gains disappear when users are shown responses independently, suggesting that humans trust all model responses, including deceptive ones, equitably when they are shown in isolation. Our findings urge future research to delve deeper into the nuanced evaluation of trust in human-machine teaming systems.
Tell Me What You Want : Addressing the Expectation Gap for Goal Conveyance from Humans to Robots
Mar 21, 2024

Conveying human goals to autonomous systems (AS) occurs both when the system is being designed and when it is being operated. The design-step conveyance is typically mediated by robotics and AI engineers, who must appropriately capture end-user requirements and concepts of operations, while the operation-step conveyance is mediated by the design, interfaces, and behavior of the AI. However, communication can be difficult during both these periods because of mismatches in the expectations and expertise of the end-user and the roboticist, necessitating more design cycles to resolve. We examine some of the barriers in communicating system design requirements, and develop an augmentation for applied cognitive task analysis (ACTA) methods, that we call robot task analysis (RTA), pertaining specifically to the development of autonomous systems. Further, we introduce a top-down view of an underexplored area of friction between requirements communication -- implied human expectations -- utilizing a collection of work primarily from experimental psychology and social sciences. We show how such expectations can be used in conjunction with task-specific expectations and the system design process for AS to improve design team communication, alleviate barriers to user rejection, and reduce the number of design cycles.
STL: Surprisingly Tricky Logic (for System Validation)
May 26, 2023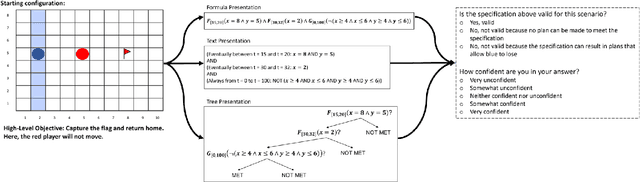
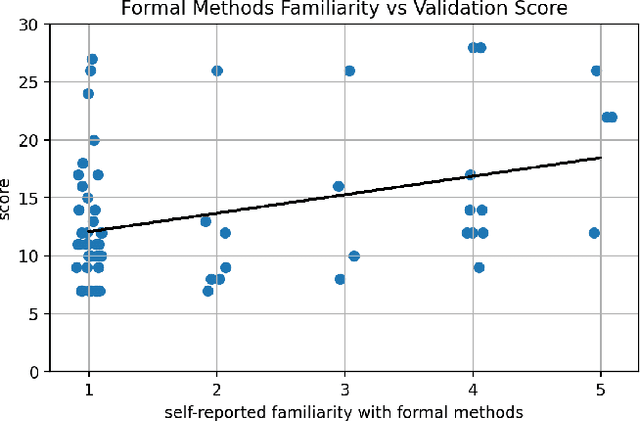
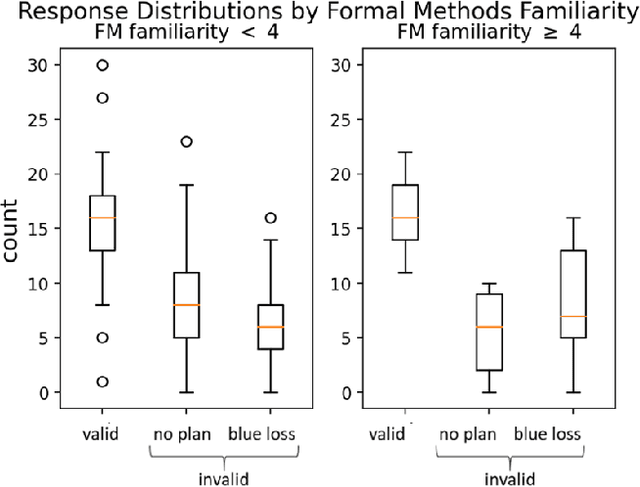
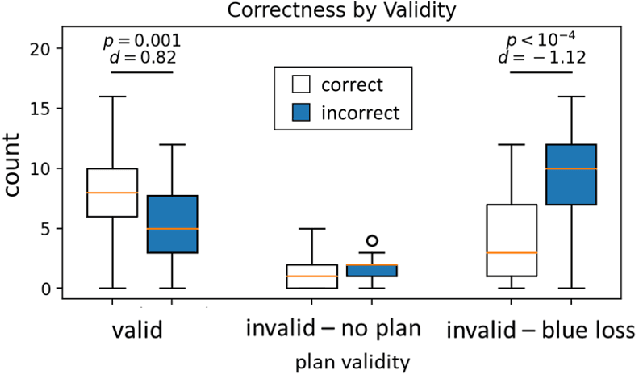
Much of the recent work developing formal methods techniques to specify or learn the behavior of autonomous systems is predicated on a belief that formal specifications are interpretable and useful for humans when checking systems. Though frequently asserted, this assumption is rarely tested. We performed a human experiment (N = 62) with a mix of people who were and were not familiar with formal methods beforehand, asking them to validate whether a set of signal temporal logic (STL) constraints would keep an agent out of harm and allow it to complete a task in a gridworld capture-the-flag setting. Validation accuracy was $45\% \pm 20\%$ (mean $\pm$ standard deviation). The ground-truth validity of a specification, subjects' familiarity with formal methods, and subjects' level of education were found to be significant factors in determining validation correctness. Participants exhibited an affirmation bias, causing significantly increased accuracy on valid specifications, but significantly decreased accuracy on invalid specifications. Additionally, participants, particularly those familiar with formal methods, tended to be overconfident in their answers, and be similarly confident regardless of actual correctness. Our data do not support the belief that formal specifications are inherently human-interpretable to a meaningful degree for system validation. We recommend ergonomic improvements to data presentation and validation training, which should be tested before claims of interpretability make their way back into the formal methods literature.
Maneuver Identification Challenge
Aug 25, 2021
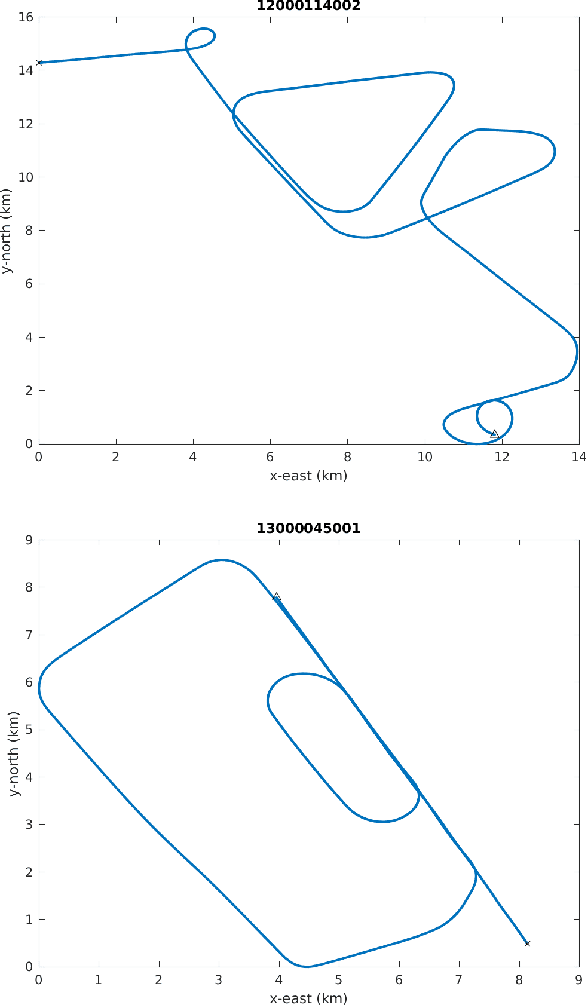
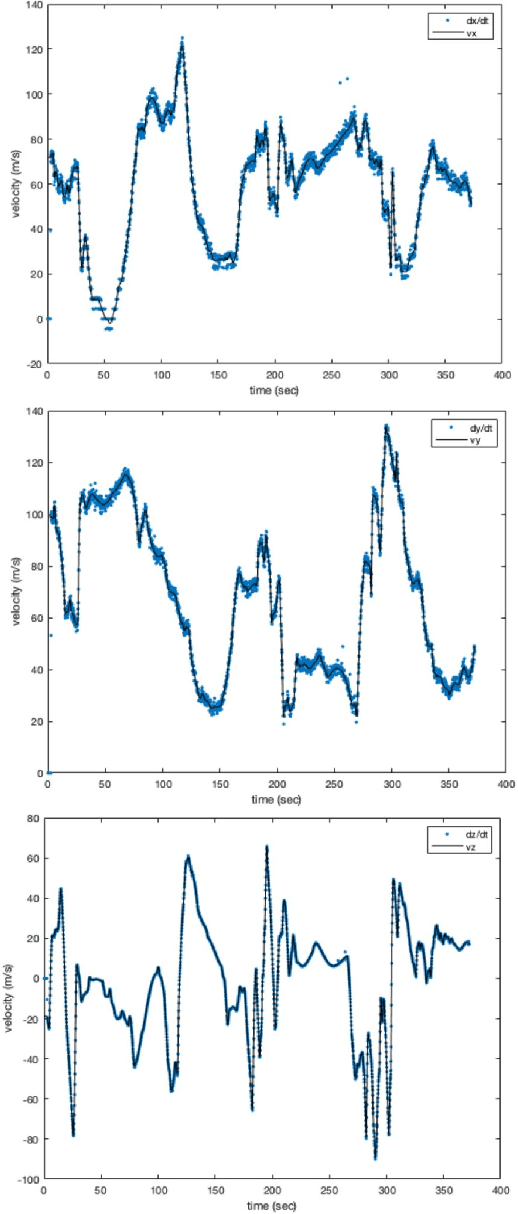

AI algorithms that identify maneuvers from trajectory data could play an important role in improving flight safety and pilot training. AI challenges allow diverse teams to work together to solve hard problems and are an effective tool for developing AI solutions. AI challenges are also a key driver of AI computational requirements. The Maneuver Identification Challenge hosted at maneuver-id.mit.edu provides thousands of trajectories collected from pilots practicing in flight simulators, descriptions of maneuvers, and examples of these maneuvers performed by experienced pilots. Each trajectory consists of positions, velocities, and aircraft orientations normalized to a common coordinate system. Construction of the data set required significant data architecture to transform flight simulator logs into AI ready data, which included using a supercomputer for deduplication and data conditioning. There are three proposed challenges. The first challenge is separating physically plausible (good) trajectories from unfeasible (bad) trajectories. Human labeled good and bad trajectories are provided to aid in this task. Subsequent challenges are to label trajectories with their intended maneuvers and to assess the quality of those maneuvers.
Evaluation of Human-AI Teams for Learned and Rule-Based Agents in Hanabi
Jul 20, 2021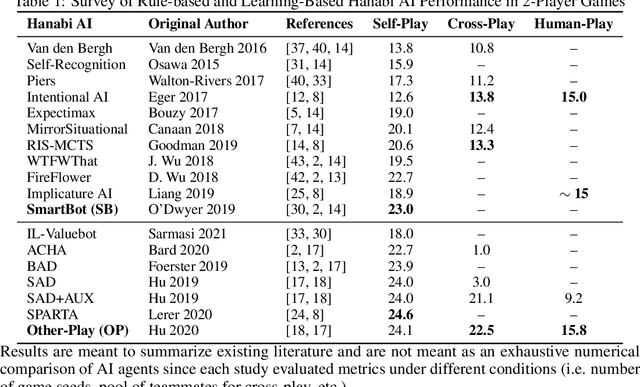
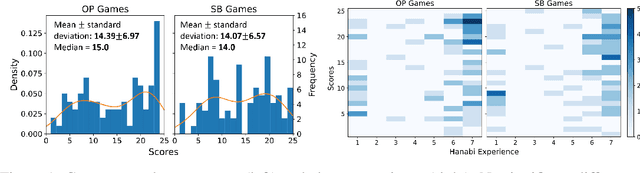
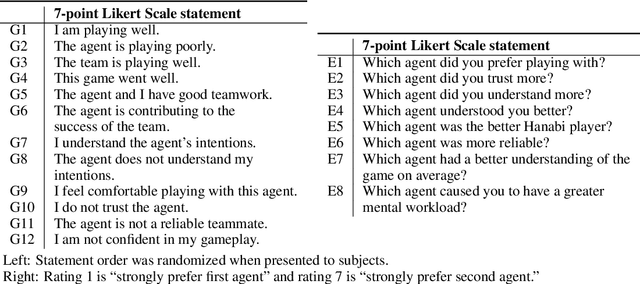
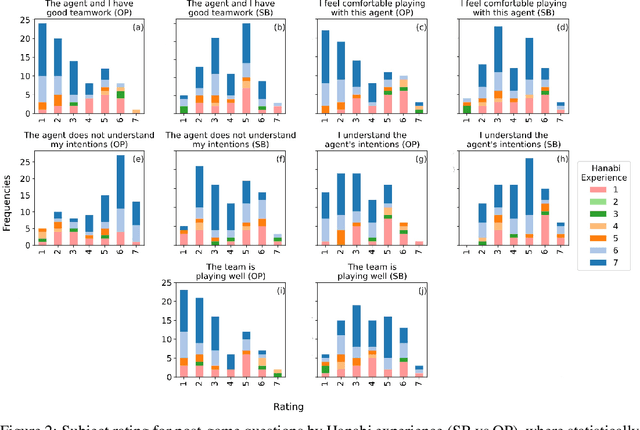
Deep reinforcement learning has generated superhuman AI in competitive games such as Go and StarCraft. Can similar learning techniques create a superior AI teammate for human-machine collaborative games? Will humans prefer AI teammates that improve objective team performance or those that improve subjective metrics of trust? In this study, we perform a single-blind evaluation of teams of humans and AI agents in the cooperative card game Hanabi, with both rule-based and learning-based agents. In addition to the game score, used as an objective metric of the human-AI team performance, we also quantify subjective measures of the human's perceived performance, teamwork, interpretability, trust, and overall preference of AI teammate. We find that humans have a clear preference toward a rule-based AI teammate (SmartBot) over a state-of-the-art learning-based AI teammate (Other-Play) across nearly all subjective metrics, and generally view the learning-based agent negatively, despite no statistical difference in the game score. This result has implications for future AI design and reinforcement learning benchmarking, highlighting the need to incorporate subjective metrics of human-AI teaming rather than a singular focus on objective task performance.
Genetic Algorithms for Starshade Retargeting in Space-Based Telescopes
Jul 23, 2019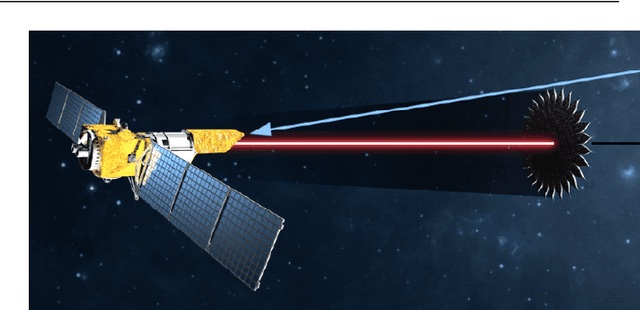
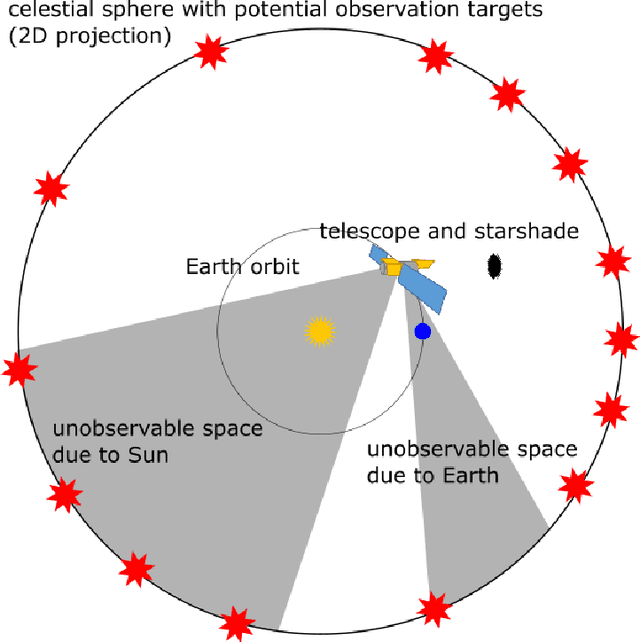
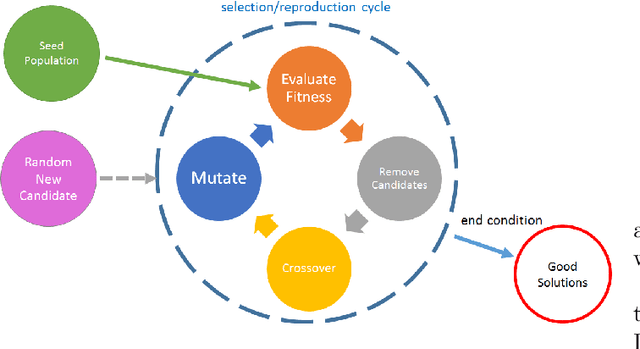
Future space-based telescopes will leverage starshades as components that can be independently positioned. Starshades will adjust the light coming in from exoplanet host stars and enhance the direct imaging of exoplanets and other phenomena. In this context, scheduling of space-based telescope observations is subject to a large number of dynamic constraints, including target observability, fuel, and target priorities. We present an application of genetic algorithm (GA) scheduling on this problem that not only takes physical constraints into account, but also considers direct human suggestions on schedules. By allowing direct suggestions on schedules, this type of heuristic can capture the scheduling preferences and expertise of stakeholders without the need to always formally codify such objectives. Additionally, this approach allows schedules to be constructed from existing ones when scenarios change; for example, this capability allows for optimization without the need to recompute schedules from scratch after changes such as new discoveries or new targets of opportunity. We developed a specific graph-traversal-based framework upon which to apply GA for telescope scheduling, and use it to demonstrate the convergence behavior of a particular implementation of GA. From this work, difficulties with regards to assigning values to observational targets are also noted, and recommendations are made for different scenarios.