 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multi-Agent Target Tracking in Intermittent Communication Environments via Analytical Belief Merging
Apr 08, 2026Autonomous multi-agent target tracking in GPS-denied and communication-restricted environments (e.g., underwater exploration, subterranean search and rescue, and adversarial domains) forces agents to operate independently and only exchange information during brief reconnection windows. Because transmitting complete observation and trajectory histories is bandwidth-exhaustive, exchanging probabilistic belief maps serves as a highly efficient proxy that preserves the topology of agent knowledge. While minimizing divergence metrics to merge these decentralized beliefs is conceptually sound, traditional approaches often rely on numerical solvers that introduce critical quantization errors and artificial noise floors. In this paper, we formulate the decentralized belief merging problem as Forward and Reverse Kullback-Leibler (KL) divergence optimizations and derive their exact closed-form analytical solutions. By deploying these derivations, we mathematically eliminate optimization artifacts, achieving perfect mathematical fidelity while reducing the computational complexity of the belief merge to $\mathcal{O}(N|S|)$ scalar operations. Furthermore, we propose a novel spatially-aware visit-weighted KL merging strategy that dynamically weighs agent beliefs based on their physical visitation history. Validated across tens of thousands of distributed simulations, extensive sensitivity analysis demonstrates that our proposed method significantly suppresses sensor noise and outperforms standard analytical means in environments characterized by highly degraded sensors and prolonged communication intervals.
Complex-Valued GNNs for Distributed Basis-Invariant Control of Planar Systems
Apr 03, 2026Graph neural networks (GNNs) are a well-regarded tool for learned control of networked dynamical systems due to their ability to be deployed in a distributed manner. However, current distributed GNN architectures assume that all nodes in the network collect geometric observations in compatible bases, which limits the usefulness of such controllers in GPS-denied and compass-denied environments. This paper presents a GNN parametrization that is globally invariant to choice of local basis. 2D geometric features and transformations between bases are expressed in the complex domain. Inside each GNN layer, complex-valued linear layers with phase-equivariant activation functions are used. When viewed from a fixed global frame, all policies learned by this architecture are strictly invariant to choice of local frames. This architecture is shown to increase the data efficiency, tracking performance, and generalization of learned control when compared to a real-valued baseline on an imitation learning flocking task.
Real-Time Optical Communication Using Event-Based Vision with Moving Transmitters
Mar 19, 2026In multi-robot systems, traditional radio frequency (RF) communication struggles with contention and jamming. Optical communication offers a strong alternative. However, conventional frame-based cameras suffer from limited frame rates, motion blur, and reduced robustness under high dynamic range lighting. Event cameras support microsecond temporal resolution and high dynamic range, making them extremely sensitive to scene changes under fast relative motion with an optical transmitter. Leveraging these strengths, we develop a complete optical communication system capable of tracking moving transmitters and decoding messages in real time. Our system achieves over $95\%$ decoding accuracy for text transmission during motion by implementing a Geometry-Aware Unscented Kalman Filter (GA-UKF), achieving 7x faster processing speed compared to the previous state-of-the-art method, while maintaining equivalent tracking accuracy at transmitting frequencies $\geq$ 1 kHz.
Multi-layer Motion Planning with Kinodynamic and Spatio-Temporal Constraints
Mar 10, 2025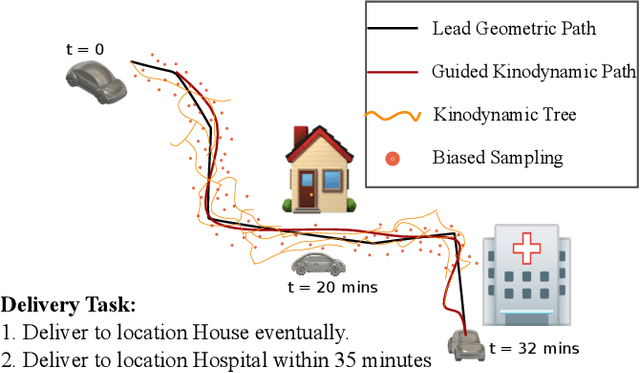
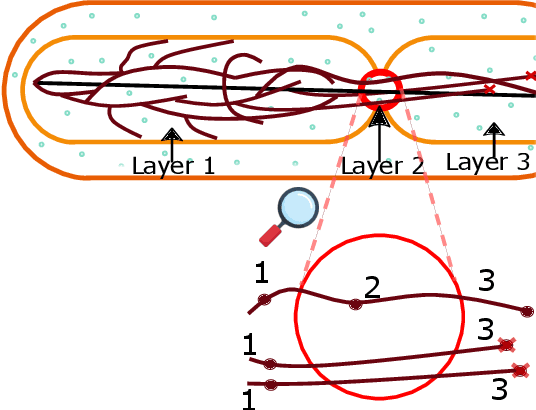
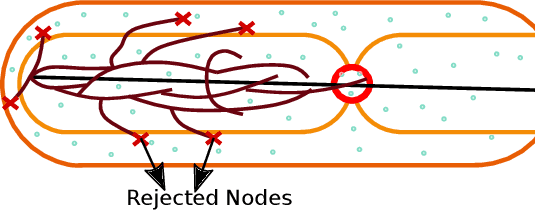
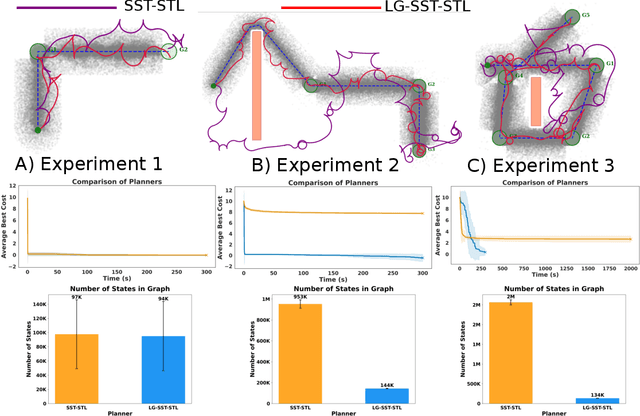
We propose a novel, multi-layered planning approach for computing paths that satisfy both kinodynamic and spatiotemporal constraints. Our three-part framework first establishes potential sequences to meet spatial constraints, using them to calculate a geometric lead path. This path then guides an asymptotically optimal sampling-based kinodynamic planner, which minimizes an STL-robustness cost to jointly satisfy spatiotemporal and kinodynamic constraints. In our experiments, we test our method with a velocity-controlled Ackerman-car model and demonstrate significant efficiency gains compared to prior art. Additionally, our method is able to generate complex path maneuvers, such as crossovers, something that previous methods had not demonstrated.
Accelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Games with Delayed Rewards
Nov 26, 2024
In this paper, we tackle the challenging problem of delayed rewards in reinforcement learning (RL). While Proximal Policy Optimization (PPO) has emerged as a leading Policy Gradient method, its performance can degrade under delayed rewards. We introduce two key enhancements to PPO: a hybrid policy architecture that combines an offline policy (trained on expert demonstrations) with an online PPO policy, and a reward shaping mechanism using Time Window Temporal Logic (TWTL). The hybrid architecture leverages offline data throughout training while maintaining PPO's theoretical guarantees. Building on the monotonic improvement framework of Trust Region Policy Optimization (TRPO), we prove that our approach ensures improvement over both the offline policy and previous iterations, with a bounded performance gap of $(2\varsigma\gamma\alpha^2)/(1-\gamma)^2$, where $\alpha$ is the mixing parameter, $\gamma$ is the discount factor, and $\varsigma$ bounds the expected advantage. Additionally, we prove that our TWTL-based reward shaping preserves the optimal policy of the original problem. TWTL enables formal translation of temporal objectives into immediate feedback signals that guide learning. We demonstrate the effectiveness of our approach through extensive experiments on an inverted pendulum and a lunar lander environments, showing improvements in both learning speed and final performance compared to standard PPO and offline-only approaches.
Grand Challenges in the Verification of Autonomous Systems
Nov 21, 2024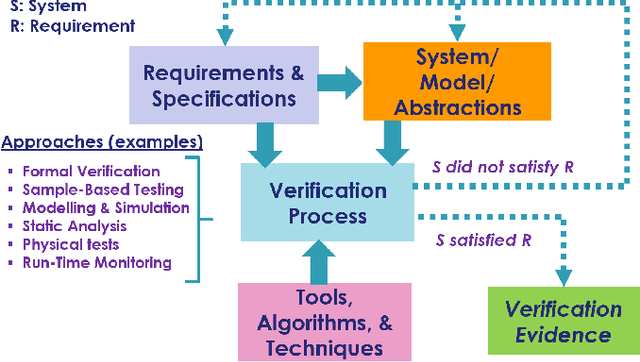
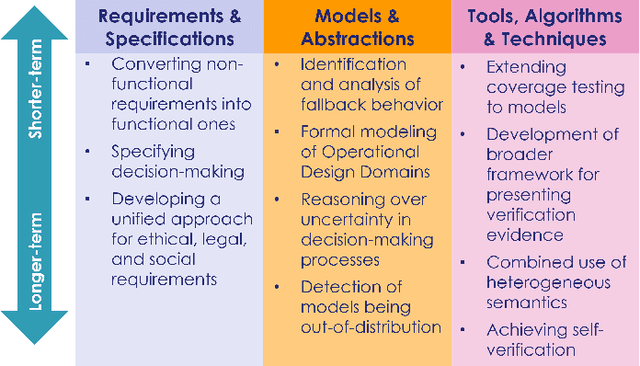
Autonomous systems use independent decision-making with only limited human intervention to accomplish goals in complex and unpredictable environments. As the autonomy technologies that underpin them continue to advance, these systems will find their way into an increasing number of applications in an ever wider range of settings. If we are to deploy them to perform safety-critical or mission-critical roles, it is imperative that we have justified confidence in their safe and correct operation. Verification is the process by which such confidence is established. However, autonomous systems pose challenges to existing verification practices. This paper highlights viewpoints of the Roadmap Working Group of the IEEE Robotics and Automation Society Technical Committee for Verification of Autonomous Systems, identifying these grand challenges, and providing a vision for future research efforts that will be needed to address them.
Temporal Logic Planning via Zero-Shot Policy Composition
Aug 08, 2024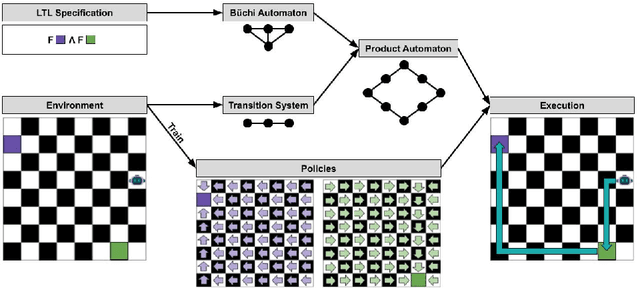
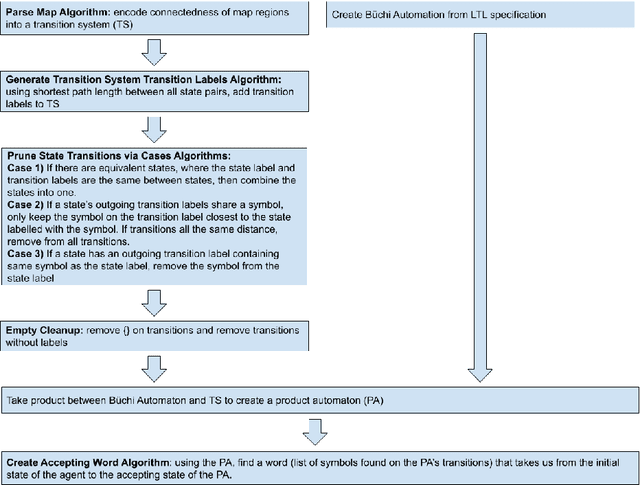
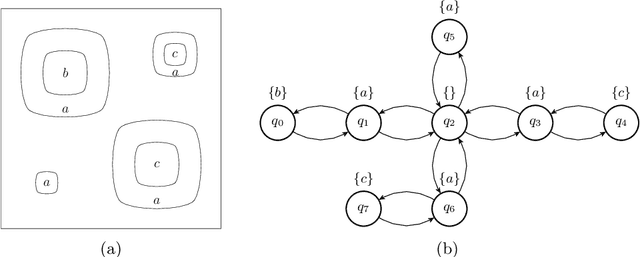
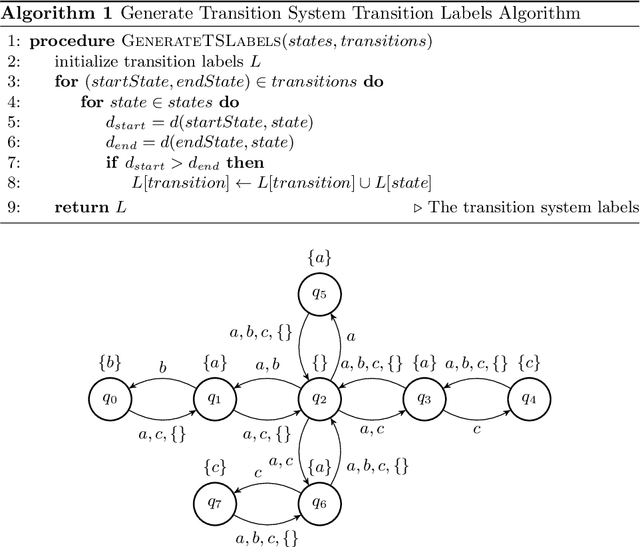
This work develops a zero-shot mechanism for an agent to satisfy a Linear Temporal Logic (LTL) specification given existing task primitives. Oftentimes, autonomous robots need to satisfy spatial and temporal goals that are unknown until run time. Prior research addresses the problem by learning policies that are capable of executing a high-level task specified using LTL, but they incorporate the specification into the learning process; therefore, any change to the specification requires retraining the policy. Other related research addresses the problem by creating skill-machines which, given a specification change, do not require full policy retraining but require fine-tuning on the skill-machine to guarantee satisfaction. We present a more a flexible approach -- to learn a set of minimum-violation (MV) task primitive policies that can be used to satisfy arbitrary LTL specifications without retraining or fine-tuning. Task primitives can be learned offline using reinforcement learning (RL) methods and combined using Boolean composition at deployment. This work focuses on creating and pruning a transition system (TS) representation of the environment in order to solve for deterministic, non-ambiguous, and feasible solutions to LTL specifications given an environment and a set of MV task primitive policies. We show that our pruned TS is deterministic, contains no unrealizable transitions, and is sound. Through simulation, we show that our approach is executable and we verify our MV policies produce the expected symbols.
Tell Me What You Want : Addressing the Expectation Gap for Goal Conveyance from Humans to Robots
Mar 21, 2024

Conveying human goals to autonomous systems (AS) occurs both when the system is being designed and when it is being operated. The design-step conveyance is typically mediated by robotics and AI engineers, who must appropriately capture end-user requirements and concepts of operations, while the operation-step conveyance is mediated by the design, interfaces, and behavior of the AI. However, communication can be difficult during both these periods because of mismatches in the expectations and expertise of the end-user and the roboticist, necessitating more design cycles to resolve. We examine some of the barriers in communicating system design requirements, and develop an augmentation for applied cognitive task analysis (ACTA) methods, that we call robot task analysis (RTA), pertaining specifically to the development of autonomous systems. Further, we introduce a top-down view of an underexplored area of friction between requirements communication -- implied human expectations -- utilizing a collection of work primarily from experimental psychology and social sciences. We show how such expectations can be used in conjunction with task-specific expectations and the system design process for AS to improve design team communication, alleviate barriers to user rejection, and reduce the number of design cycles.
Graph Q-Learning for Combinatorial Optimization
Jan 11, 2024Graph-structured data is ubiquitous throughout natural and social sciences, and Graph Neural Networks (GNNs) have recently been shown to be effective at solving prediction and inference problems on graph data. In this paper, we propose and demonstrate that GNNs can be applied to solve Combinatorial Optimization (CO) problems. CO concerns optimizing a function over a discrete solution space that is often intractably large. To learn to solve CO problems, we formulate the optimization process as a sequential decision making problem, where the return is related to how close the candidate solution is to optimality. We use a GNN to learn a policy to iteratively build increasingly promising candidate solutions. We present preliminary evidence that GNNs trained through Q-Learning can solve CO problems with performance approaching state-of-the-art heuristic-based solvers, using only a fraction of the parameters and training time.
A Flexible and Efficient Temporal Logic Tool for Python: PyTeLo
Oct 12, 2023



Temporal logic is an important tool for specifying complex behaviors of systems. It can be used to define properties for verification and monitoring, as well as goals for synthesis tools, allowing users to specify rich missions and tasks. Some of the most popular temporal logics include Metric Temporal Logic (MTL), Signal Temporal Logic (STL), and weighted STL (wSTL), which also allow the definition of timing constraints. In this work, we introduce PyTeLo, a modular and versatile Python-based software that facilitates working with temporal logic languages, specifically MTL, STL, and wSTL. Applying PyTeLo requires only a string representation of the temporal logic specification and, optionally, the dynamics of the system of interest. Next, PyTeLo reads the specification using an ANTLR-generated parser and generates an Abstract Syntax Tree (AST) that captures the structure of the formula. For synthesis, the AST serves to recursively encode the specification into a Mixed Integer Linear Program (MILP) that is solved using a commercial solver such as Gurobi. We describe the architecture and capabilities of PyTeLo and provide example applications highlighting its adaptability and extensibility for various research problems.