 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Optimal Learning from Preferences via Weighted Temporal Logic with Applications in Robotics and Formula 1
Nov 11, 2025Autonomous systems increasingly rely on human feedback to align their behavior, expressed as pairwise comparisons, rankings, or demonstrations. While existing methods can adapt behaviors, they often fail to guarantee safety in safety-critical domains. We propose a safety-guaranteed, optimal, and efficient approach to solve the learning problem from preferences, rankings, or demonstrations using Weighted Signal Temporal Logic (WSTL). WSTL learning problems, when implemented naively, lead to multi-linear constraints in the weights to be learned. By introducing structural pruning and log-transform procedures, we reduce the problem size and recast the problem as a Mixed-Integer Linear Program while preserving safety guarantees. Experiments on robotic navigation and real-world Formula 1 data demonstrate that the method effectively captures nuanced preferences and models complex task objectives.
An Iterative Approach for Heterogeneous Multi-Agent Route Planning with Resource Transportation Uncertainty and Temporal Logic Goals
Aug 26, 2025This paper presents an iterative approach for heterogeneous multi-agent route planning in environments with unknown resource distributions. We focus on a team of robots with diverse capabilities tasked with executing missions specified using Capability Temporal Logic (CaTL), a formal framework built on Signal Temporal Logic to handle spatial, temporal, capability, and resource constraints. The key challenge arises from the uncertainty in the initial distribution and quantity of resources in the environment. To address this, we introduce an iterative algorithm that dynamically balances exploration and task fulfillment. Robots are guided to explore the environment, identifying resource locations and quantities while progressively refining their understanding of the resource landscape. At the same time, they aim to maximally satisfy the mission objectives based on the current information, adapting their strategies as new data is uncovered. This approach provides a robust solution for planning in dynamic, resource-constrained environments, enabling efficient coordination of heterogeneous teams even under conditions of uncertainty. Our method's effectiveness and performance are demonstrated through simulated case studies.
STLGame: Signal Temporal Logic Games in Adversarial Multi-Agent Systems
Dec 02, 2024We study how to synthesize a robust and safe policy for autonomous systems under signal temporal logic (STL) tasks in adversarial settings against unknown dynamic agents. To ensure the worst-case STL satisfaction, we propose STLGame, a framework that models the multi-agent system as a two-player zero-sum game, where the ego agents try to maximize the STL satisfaction and other agents minimize it. STLGame aims to find a Nash equilibrium policy profile, which is the best case in terms of robustness against unseen opponent policies, by using the fictitious self-play (FSP) framework. FSP iteratively converges to a Nash profile, even in games set in continuous state-action spaces. We propose a gradient-based method with differentiable STL formulas, which is crucial in continuous settings to approximate the best responses at each iteration of FSP. We show this key aspect experimentally by comparing with reinforcement learning-based methods to find the best response. Experiments on two standard dynamical system benchmarks, Ackermann steering vehicles and autonomous drones, demonstrate that our converged policy is almost unexploitable and robust to various unseen opponents' policies. All code and additional experimental results can be found on our project website: https://sites.google.com/view/stlgame
Accelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Games with Delayed Rewards
Nov 26, 2024
In this paper, we tackle the challenging problem of delayed rewards in reinforcement learning (RL). While Proximal Policy Optimization (PPO) has emerged as a leading Policy Gradient method, its performance can degrade under delayed rewards. We introduce two key enhancements to PPO: a hybrid policy architecture that combines an offline policy (trained on expert demonstrations) with an online PPO policy, and a reward shaping mechanism using Time Window Temporal Logic (TWTL). The hybrid architecture leverages offline data throughout training while maintaining PPO's theoretical guarantees. Building on the monotonic improvement framework of Trust Region Policy Optimization (TRPO), we prove that our approach ensures improvement over both the offline policy and previous iterations, with a bounded performance gap of $(2\varsigma\gamma\alpha^2)/(1-\gamma)^2$, where $\alpha$ is the mixing parameter, $\gamma$ is the discount factor, and $\varsigma$ bounds the expected advantage. Additionally, we prove that our TWTL-based reward shaping preserves the optimal policy of the original problem. TWTL enables formal translation of temporal objectives into immediate feedback signals that guide learning. We demonstrate the effectiveness of our approach through extensive experiments on an inverted pendulum and a lunar lander environments, showing improvements in both learning speed and final performance compared to standard PPO and offline-only approaches.
Learning Optimal Signal Temporal Logic Decision Trees for Classification: A Max-Flow MILP Formulation
Jul 30, 2024



This paper presents a novel framework for inferring timed temporal logic properties from data. The dataset comprises pairs of finite-time system traces and corresponding labels, denoting whether the traces demonstrate specific desired behaviors, e.g. whether the ship follows a safe route or not. Our proposed approach leverages decision-tree-based methods to infer Signal Temporal Logic classifiers using primitive formulae. We formulate the inference process as a mixed integer linear programming optimization problem, recursively generating constraints to determine both data classification and tree structure. Applying a max-flow algorithm on the resultant tree transforms the problem into a global optimization challenge, leading to improved classification rates compared to prior methodologies. Moreover, we introduce a technique to reduce the number of constraints by exploiting the symmetry inherent in STL primitives, which enhances the algorithm's time performance and interpretability. To assess our algorithm's effectiveness and classification performance, we conduct three case studies involving two-class, multi-class, and complex formula classification scenarios.
Optimal Control Synthesis with Relaxed Global Temporal Logic Specifications for Homogeneous Multi-robot Teams
Jun 03, 2024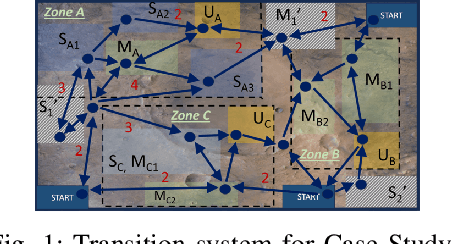
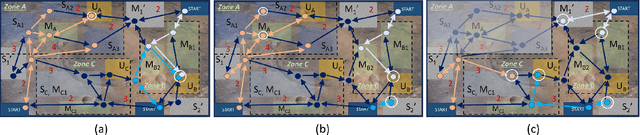
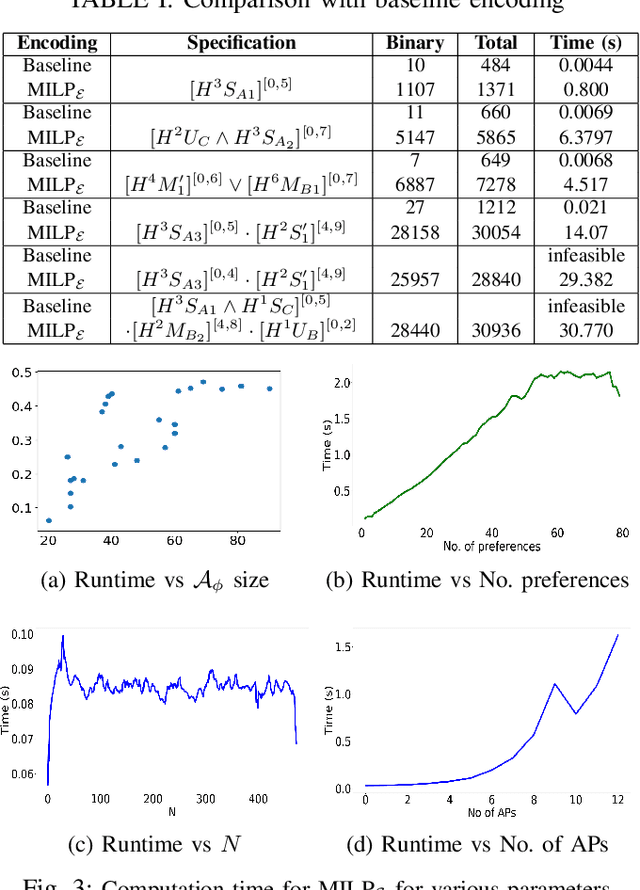
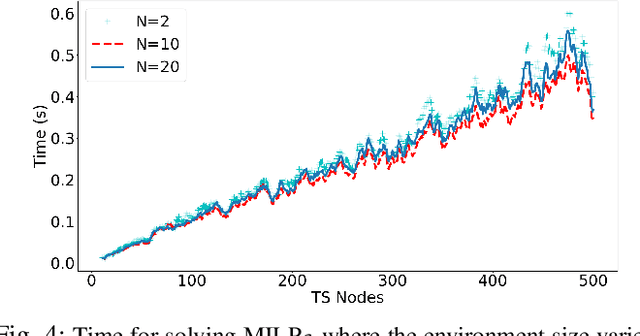
In this work, we address the problem of control synthesis for a homogeneous team of robots given a global temporal logic specification and formal user preferences for relaxation in case of infeasibility. The relaxation preferences are represented as a Weighted Finite-state Edit System and are used to compute a relaxed specification automaton that captures all allowable relaxations of the mission specification and their costs. For synthesis, we introduce a Mixed Integer Linear Programming (MILP) formulation that combines the motion of the team of robots with the relaxed specification automaton. Our approach combines automata-based and MILP-based methods and leverages the strengths of both approaches while avoiding their shortcomings. Specifically, the relaxed specification automaton explicitly accounts for the progress towards satisfaction, and the MILP-based optimization approach avoids the state-space explosion associated with explicit product-automata construction, thereby efficiently solving the problem. The case studies highlight the efficiency of the proposed approach.
TLINet: Differentiable Neural Network Temporal Logic Inference
May 14, 2024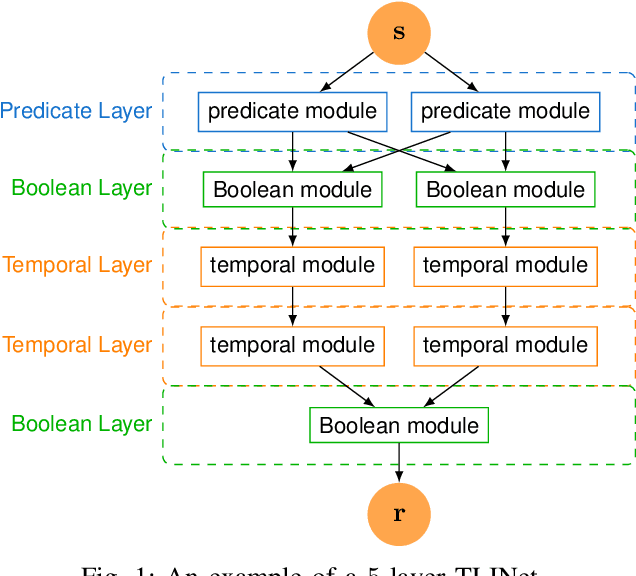
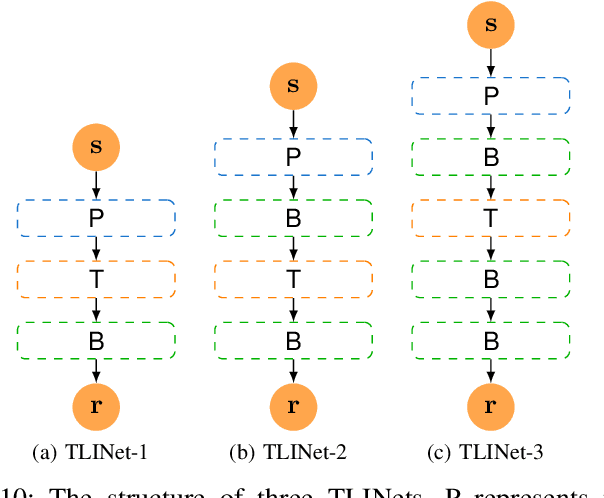
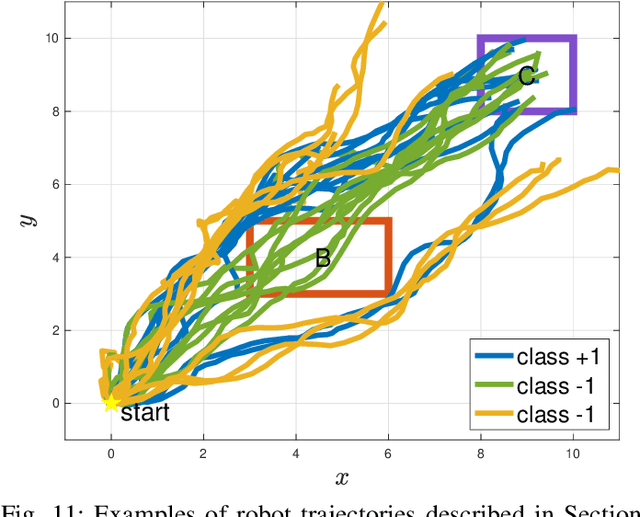
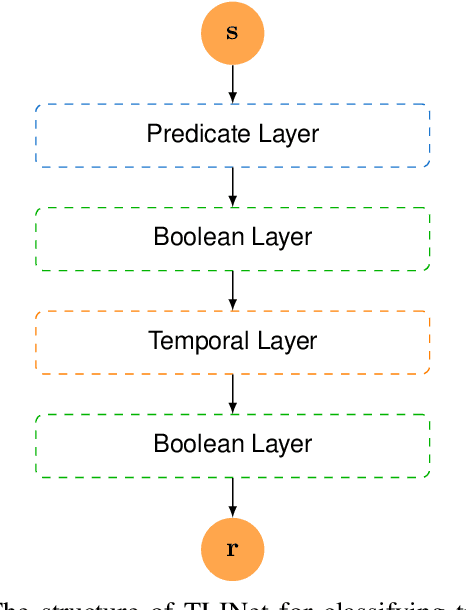
There has been a growing interest in extracting formal descriptions of the system behaviors from data. Signal Temporal Logic (STL) is an expressive formal language used to describe spatial-temporal properties with interpretability. This paper introduces TLINet, a neural-symbolic framework for learning STL formulas. The computation in TLINet is differentiable, enabling the usage of off-the-shelf gradient-based tools during the learning process. In contrast to existing approaches, we introduce approximation methods for max operator designed specifically for temporal logic-based gradient techniques, ensuring the correctness of STL satisfaction evaluation. Our framework not only learns the structure but also the parameters of STL formulas, allowing flexible combinations of operators and various logical structures. We validate TLINet against state-of-the-art baselines, demonstrating that our approach outperforms these baselines in terms of interpretability, compactness, rich expressibility, and computational efficiency.
A Flexible and Efficient Temporal Logic Tool for Python: PyTeLo
Oct 12, 2023



Temporal logic is an important tool for specifying complex behaviors of systems. It can be used to define properties for verification and monitoring, as well as goals for synthesis tools, allowing users to specify rich missions and tasks. Some of the most popular temporal logics include Metric Temporal Logic (MTL), Signal Temporal Logic (STL), and weighted STL (wSTL), which also allow the definition of timing constraints. In this work, we introduce PyTeLo, a modular and versatile Python-based software that facilitates working with temporal logic languages, specifically MTL, STL, and wSTL. Applying PyTeLo requires only a string representation of the temporal logic specification and, optionally, the dynamics of the system of interest. Next, PyTeLo reads the specification using an ANTLR-generated parser and generates an Abstract Syntax Tree (AST) that captures the structure of the formula. For synthesis, the AST serves to recursively encode the specification into a Mixed Integer Linear Program (MILP) that is solved using a commercial solver such as Gurobi. We describe the architecture and capabilities of PyTeLo and provide example applications highlighting its adaptability and extensibility for various research problems.
Energy-Constrained Active Exploration Under Incremental-Resolution Symbolic Perception
Sep 13, 2023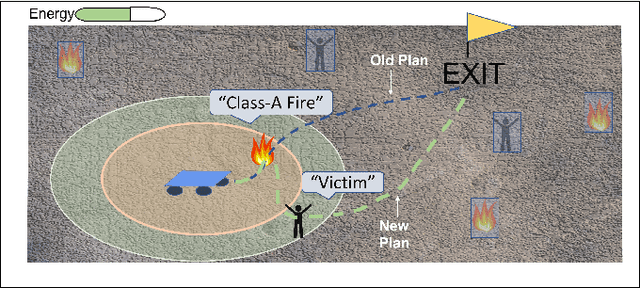
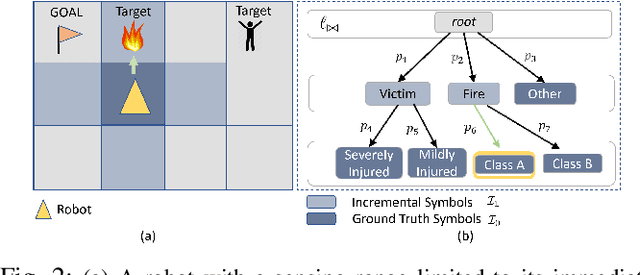
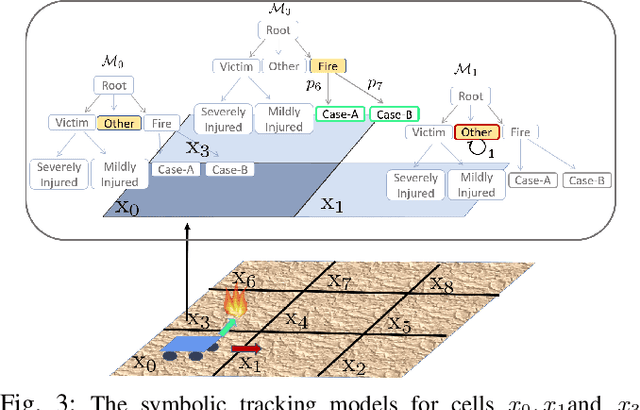
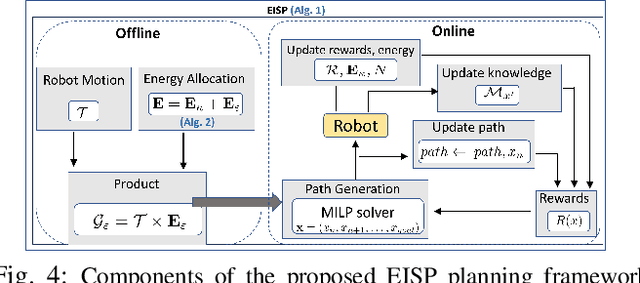
In this work, we consider the problem of autonomous exploration in search of targets while respecting a fixed energy budget. The robot is equipped with an incremental-resolution symbolic perception module wherein the perception of targets in the environment improves as the robot's distance from targets decreases. We assume no prior information about the total number of targets, their locations as well as their possible distribution within the environment. This work proposes a novel decision-making framework for the resulting constrained sequential decision-making problem by first converting it into a reward maximization problem on a product graph computed offline. It is then solved online as a Mixed-Integer Linear Program (MILP) where the knowledge about the environment is updated at each step, combining automata-based and MILP-based techniques. We demonstrate the efficacy of our approach with the help of a case study and present empirical evaluation in terms of expected regret. Furthermore, the runtime performance shows that online planning can be efficiently performed for moderately-sized grid environments.
Symbolic Perception Risk in Autonomous Driving
Mar 16, 2023



We develop a novel framework to assess the risk of misperception in a traffic sign classification task in the presence of exogenous noise. We consider the problem in an autonomous driving setting, where visual input quality gradually improves due to improved resolution, and less noise since the distance to traffic signs decreases. Using the estimated perception statistics obtained using the standard classification algorithms, we aim to quantify the risk of misperception to mitigate the effects of imperfect visual observation. By exploring perception outputs, their expected high-level actions, and potential costs, we show the closed-form representation of the conditional value-at-risk (CVaR) of misperception. Several case studies support the effectiveness of our proposed methodology.