 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Success: Sample-Efficient and Statistically Rigorous Robot Policy Comparison
Mar 13, 2026Generalist robot manipulation policies are becoming increasingly capable, but are limited in evaluation to a small number of hardware rollouts. This strong resource constraint in real-world testing necessitates both more informative performance measures and reliable and efficient evaluation procedures to properly assess model capabilities and benchmark progress in the field. This work presents a novel framework for robot policy comparison that is sample-efficient, statistically rigorous, and applicable to a broad set of evaluation metrics used in practice. Based on safe, anytime-valid inference (SAVI), our test procedure is sequential, allowing the evaluator to stop early when sufficient statistical evidence has accumulated to reach a decision at a pre-specified level of confidence. Unlike previous work developed for binary success, our unified approach addresses a wide range of informative metrics: from discrete partial credit task progress to continuous measures of episodic reward or trajectory smoothness, spanning both parametric and nonparametric comparison problems. Through extensive validation on simulated and real-world evaluation data, we demonstrate up to 70% reduction in evaluation burden compared to standard batch methods and up to 50% reduction compared to state-of-the-art sequential procedures designed for binary outcomes, with no loss of statistical rigor. Notably, our empirical results show that competing policies can be separated more quickly when using fine-grained task progress than binary success metrics.
Multi-Round Human-AI Collaboration with User-Specified Requirements
Feb 19, 2026As humans increasingly rely on multiround conversational AI for high stakes decisions, principled frameworks are needed to ensure such interactions reliably improve decision quality. We adopt a human centric view governed by two principles: counterfactual harm, ensuring the AI does not undermine human strengths, and complementarity, ensuring it adds value where the human is prone to err. We formalize these concepts via user defined rules, allowing users to specify exactly what harm and complementarity mean for their specific task. We then introduce an online, distribution free algorithm with finite sample guarantees that enforces the user-specified constraints over the collaboration dynamics. We evaluate our framework across two interactive settings: LLM simulated collaboration on a medical diagnostic task and a human crowdsourcing study on a pictorial reasoning task. We show that our online procedure maintains prescribed counterfactual harm and complementarity violation rates even under nonstationary interaction dynamics. Moreover, tightening or loosening these constraints produces predictable shifts in downstream human accuracy, confirming that the two principles serve as practical levers for steering multi-round collaboration toward better decision quality without the need to model or constrain human behavior.
When to Trust the Cheap Check: Weak and Strong Verification for Reasoning
Feb 19, 2026Reasoning with LLMs increasingly unfolds inside a broader verification loop. Internally, systems use cheap checks, such as self-consistency or proxy rewards, which we call weak verification. Externally, users inspect outputs and steer the model through feedback until results are trustworthy, which we call strong verification. These signals differ sharply in cost and reliability: strong verification can establish trust but is resource-intensive, while weak verification is fast and scalable but noisy and imperfect. We formalize this tension through weak--strong verification policies, which decide when to accept or reject based on weak verification and when to defer to strong verification. We introduce metrics capturing incorrect acceptance, incorrect rejection, and strong-verification frequency. Over population, we show that optimal policies admit a two-threshold structure and that calibration and sharpness govern the value of weak verifiers. Building on this, we develop an online algorithm that provably controls acceptance and rejection errors without assumptions on the query stream, the language model, or the weak verifier.
Robust Policy Optimization to Prevent Catastrophic Forgetting
Feb 09, 2026Large language models are commonly trained through multi-stage post-training: first via RLHF, then fine-tuned for other downstream objectives. Yet even small downstream updates can compromise earlier learned behaviors (e.g., safety), exposing a brittleness known as catastrophic forgetting. This suggests standard RLHF objectives do not guarantee robustness to future adaptation. To address it, most prior work designs downstream-time methods to preserve previously learned behaviors. We argue that preventing this requires pre-finetuning robustness: the base policy should avoid brittle high-reward solutions whose reward drops sharply under standard fine-tuning. We propose Fine-tuning Robust Policy Optimization (FRPO), a robust RLHF framework that optimizes reward not only at the current policy, but across a KL-bounded neighborhood of policies reachable by downstream adaptation. The key idea is to ensure reward stability under policy shifts via a max-min formulation. By modifying GRPO, we develop an algorithm with no extra computation, and empirically show it substantially reduces safety degradation across multiple base models and downstream fine-tuning regimes (SFT and RL) while preserving downstream task performance. We further study a math-focused RL setting, demonstrating that FRPO preserves accuracy under subsequent fine-tuning.
eCP: Informative uncertainty quantification via Equivariantized Conformal Prediction with pre-trained models
Feb 03, 2026We study the effect of group symmetrization of pre-trained models on conformal prediction (CP), a post-hoc, distribution-free, finite-sample method of uncertainty quantification that offers formal coverage guarantees under the assumption of data exchangeability. Unfortunately, CP uncertainty regions can grow significantly in long horizon missions, rendering the statistical guarantees uninformative. To that end, we propose infusing CP with geometric information via group-averaging of the pretrained predictor to distribute the non-conformity mass across the orbits. Each sample now is treated as a representative of an orbit, thus uncertainty can be mitigated by other samples entangled to it via the orbit inducing elements of the symmetry group. Our approach provably yields contracted non-conformity scores in increasing convex order, implying improved exponential-tail bounds and sharper conformal prediction sets in expectation, especially at high confidence levels. We then propose an experimental design to test these theoretical claims in pedestrian trajectory prediction.
Towards X-embodiment safety: A control theory perspective on transferring safety certificates across dynamical systems
Feb 03, 2026Control barrier functions (CBFs) provide a powerful tool for enforcing safety constraints in control systems, but their direct application to complex, high-dimensional dynamics is often challenging. In many settings, safety certificates are more naturally designed for simplified or alternative system models that do not exactly match the dynamics of interest. This paper addresses the problem of transferring safety guarantees between dynamical systems with mismatched dynamics. We propose a transferred control barrier function (tCBF) framework that enables safety constraints defined on one system to be systematically enforced on another system using a simulation function and an explicit margin term. The resulting transferred barrier accounts for model mismatch and induces a safety condition that can be enforced on the target system via a quadratic-program-based safety filter. The proposed approach is general and does not require the two systems to share the same state dimension or dynamics. We demonstrate the effectiveness of the framework on a quadrotor navigation task with the transferred barrier ensuring collision avoidance for the target system, while remaining minimally invasive to a nominal controller. These results highlight the potential of transferred control barrier functions as a general mechanism for enforcing safety across heterogeneous dynamical systems.
Deep Equivariant Multi-Agent Control Barrier Functions
Jun 09, 2025With multi-agent systems increasingly deployed autonomously at scale in complex environments, ensuring safety of the data-driven policies is critical. Control Barrier Functions have emerged as an effective tool for enforcing safety constraints, yet existing learning-based methods often lack in scalability, generalization and sampling efficiency as they overlook inherent geometric structures of the system. To address this gap, we introduce symmetries-infused distributed Control Barrier Functions, enforcing the satisfaction of intrinsic symmetries on learnable graph-based safety certificates. We theoretically motivate the need for equivariant parametrization of CBFs and policies, and propose a simple, yet efficient and adaptable methodology for constructing such equivariant group-modular networks via the compatible group actions. This approach encodes safety constraints in a distributed data-efficient manner, enabling zero-shot generalization to larger and denser swarms. Through extensive simulations on multi-robot navigation tasks, we demonstrate that our method outperforms state-of-the-art baselines in terms of safety, scalability, and task success rates, highlighting the importance of embedding symmetries in safe distributed neural policies.
Conformal Prediction Beyond the Seen: A Missing Mass Perspective for Uncertainty Quantification in Generative Models
Jun 05, 2025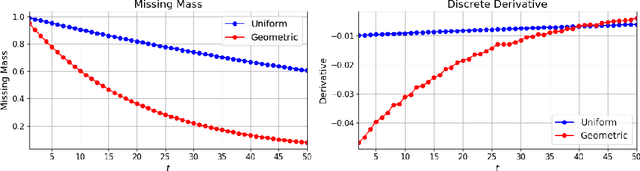
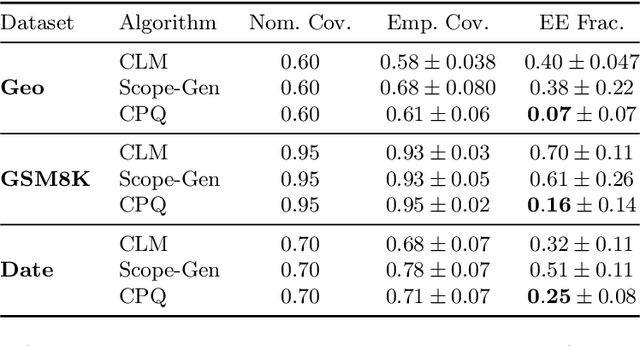
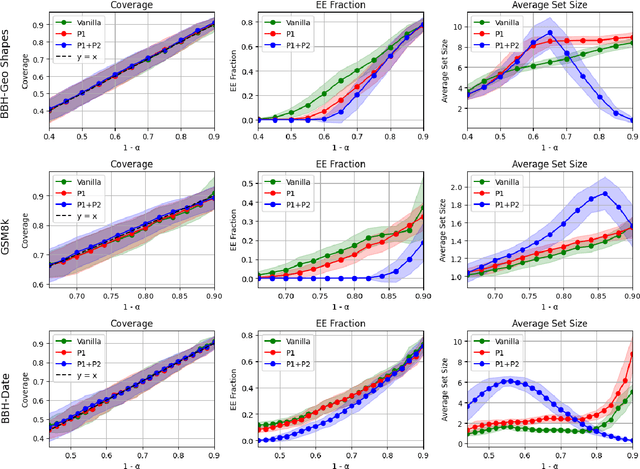
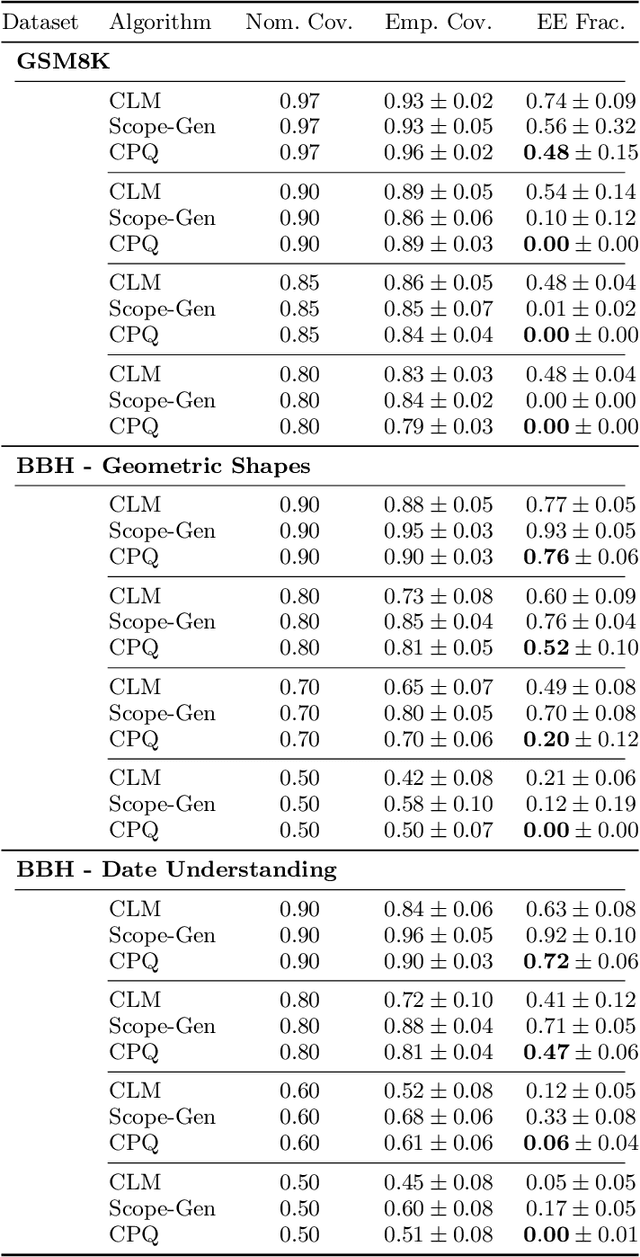
Uncertainty quantification (UQ) is essential for safe deployment of generative AI models such as large language models (LLMs), especially in high stakes applications. Conformal prediction (CP) offers a principled uncertainty quantification framework, but classical methods focus on regression and classification, relying on geometric distances or softmax scores: tools that presuppose structured outputs. We depart from this paradigm by studying CP in a query only setting, where prediction sets must be constructed solely from finite queries to a black box generative model, introducing a new trade off between coverage, test time query budget, and informativeness. We introduce Conformal Prediction with Query Oracle (CPQ), a framework characterizing the optimal interplay between these objectives. Our finite sample algorithm is built on two core principles: one governs the optimal query policy, and the other defines the optimal mapping from queried samples to prediction sets. Remarkably, both are rooted in the classical missing mass problem in statistics. Specifically, the optimal query policy depends on the rate of decay, or the derivative, of the missing mass, for which we develop a novel estimator. Meanwhile, the optimal mapping hinges on the missing mass itself, which we estimate using Good Turing estimators. We then turn our focus to implementing our method for language models, where outputs are vast, variable, and often under specified. Fine grained experiments on three real world open ended tasks and two LLMs, show CPQ applicability to any black box LLM and highlight: (1) individual contribution of each principle to CPQ performance, and (2) CPQ ability to yield significantly more informative prediction sets than existing conformal methods for language uncertainty quantification.
Likelihood-Ratio Regularized Quantile Regression: Adapting Conformal Prediction to High-Dimensional Covariate Shifts
Feb 18, 2025We consider the problem of conformal prediction under covariate shift. Given labeled data from a source domain and unlabeled data from a covariate shifted target domain, we seek to construct prediction sets with valid marginal coverage in the target domain. Most existing methods require estimating the unknown likelihood ratio function, which can be prohibitive for high-dimensional data such as images. To address this challenge, we introduce the likelihood ratio regularized quantile regression (LR-QR) algorithm, which combines the pinball loss with a novel choice of regularization in order to construct a threshold function without directly estimating the unknown likelihood ratio. We show that the LR-QR method has coverage at the desired level in the target domain, up to a small error term that we can control. Our proofs draw on a novel analysis of coverage via stability bounds from learning theory. Our experiments demonstrate that the LR-QR algorithm outperforms existing methods on high-dimensional prediction tasks, including a regression task for the Communities and Crime dataset, and an image classification task from the WILDS repository.
Decision Theoretic Foundations for Conformal Prediction: Optimal Uncertainty Quantification for Risk-Averse Agents
Feb 04, 2025



A fundamental question in data-driven decision making is how to quantify the uncertainty of predictions in ways that can usefully inform downstream action. This interface between prediction uncertainty and decision-making is especially important in risk-sensitive domains, such as medicine. In this paper, we develop decision-theoretic foundations that connect uncertainty quantification using prediction sets with risk-averse decision-making. Specifically, we answer three fundamental questions: (1) What is the correct notion of uncertainty quantification for risk-averse decision makers? We prove that prediction sets are optimal for decision makers who wish to optimize their value at risk. (2) What is the optimal policy that a risk averse decision maker should use to map prediction sets to actions? We show that a simple max-min decision policy is optimal for risk-averse decision makers. Finally, (3) How can we derive prediction sets that are optimal for such decision makers? We provide an exact characterization in the population regime and a distribution free finite-sample construction. Answering these questions naturally leads to an algorithm, Risk-Averse Calibration (RAC), which follows a provably optimal design for deriving action policies from predictions. RAC is designed to be both practical-capable of leveraging the quality of predictions in a black-box manner to enhance downstream utility-and safe-adhering to a user-defined risk threshold and optimizing the corresponding risk quantile of the user's downstream utility. Finally, we experimentally demonstrate the significant advantages of RAC in applications such as medical diagnosis and recommendation systems. Specifically, we show that RAC achieves a substantially improved trade-off between safety and utility, offering higher utility compared to existing methods while maintaining the safety guarantee.