 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Equivariant Constraint Modulation: Learning Per-Layer Symmetry Relaxation from Data
Feb 02, 2026Equivariant neural networks exploit underlying task symmetries to improve generalization, but strict equivariance constraints can induce more complex optimization dynamics that can hinder learning. Prior work addresses these limitations by relaxing strict equivariance during training, but typically relies on prespecified, explicit, or implicit target levels of relaxation for each network layer, which are task-dependent and costly to tune. We propose Recurrent Equivariant Constraint Modulation (RECM), a layer-wise constraint modulation mechanism that learns appropriate relaxation levels solely from the training signal and the symmetry properties of each layer's input-target distribution, without requiring any prior knowledge about the task-dependent target relaxation level. We demonstrate that under the proposed RECM update, the relaxation level of each layer provably converges to a value upper-bounded by its symmetry gap, namely the degree to which its input-target distribution deviates from exact symmetry. Consequently, layers processing symmetric distributions recover full equivariance, while those with approximate symmetries retain sufficient flexibility to learn non-symmetric solutions when warranted by the data. Empirically, RECM outperforms prior methods across diverse exact and approximate equivariant tasks, including the challenging molecular conformer generation on the GEOM-Drugs dataset.
Symmetries-enhanced Multi-Agent Reinforcement Learning
Jan 02, 2025



Multi-agent reinforcement learning has emerged as a powerful framework for enabling agents to learn complex, coordinated behaviors but faces persistent challenges regarding its generalization, scalability and sample efficiency. Recent advancements have sought to alleviate those issues by embedding intrinsic symmetries of the systems in the policy. Yet, most dynamical systems exhibit little to no symmetries to exploit. This paper presents a novel framework for embedding extrinsic symmetries in multi-agent system dynamics that enables the use of symmetry-enhanced methods to address systems with insufficient intrinsic symmetries, expanding the scope of equivariant learning to a wide variety of MARL problems. Central to our framework is the Group Equivariant Graphormer, a group-modular architecture specifically designed for distributed swarming tasks. Extensive experiments on a swarm of symmetry-breaking quadrotors validate the effectiveness of our approach, showcasing its potential for improved generalization and zero-shot scalability. Our method achieves significant reductions in collision rates and enhances task success rates across a diverse range of scenarios and varying swarm sizes.
Improving Equivariant Model Training via Constraint Relaxation
Aug 23, 2024



Equivariant neural networks have been widely used in a variety of applications due to their ability to generalize well in tasks where the underlying data symmetries are known. Despite their successes, such networks can be difficult to optimize and require careful hyperparameter tuning to train successfully. In this work, we propose a novel framework for improving the optimization of such models by relaxing the hard equivariance constraint during training: We relax the equivariance constraint of the network's intermediate layers by introducing an additional non-equivariance term that we progressively constrain until we arrive at an equivariant solution. By controlling the magnitude of the activation of the additional relaxation term, we allow the model to optimize over a larger hypothesis space containing approximate equivariant networks and converge back to an equivariant solution at the end of training. We provide experimental results on different state-of-the-art network architectures, demonstrating how this training framework can result in equivariant models with improved generalization performance.
BiEquiFormer: Bi-Equivariant Representations for Global Point Cloud Registration
Jul 11, 2024



The goal of this paper is to address the problem of \textit{global} point cloud registration (PCR) i.e., finding the optimal alignment between point clouds irrespective of the initial poses of the scans. This problem is notoriously challenging for classical optimization methods due to computational constraints. First, we show that state-of-the-art deep learning methods suffer from huge performance degradation when the point clouds are arbitrarily placed in space. We propose that \textit{equivariant deep learning} should be utilized for solving this task and we characterize the specific type of bi-equivariance of PCR. Then, we design BiEquiformer a novel and scalable \textit{bi-equivariant} pipeline i.e. equivariant to the independent transformations of the input point clouds. While a naive approach would process the point clouds independently we design expressive bi-equivariant layers that fuse the information from both point clouds. This allows us to extract high-quality superpoint correspondences and in turn, robust point-cloud registration. Extensive comparisons against state-of-the-art methods show that our method achieves comparable performance in the canonical setting and superior performance in the robust setting in both the 3DMatch and the challenging low-overlap 3DLoMatch dataset.
SE(3)-Equivariant Attention Networks for Shape Reconstruction in Function Space
Apr 05, 2022
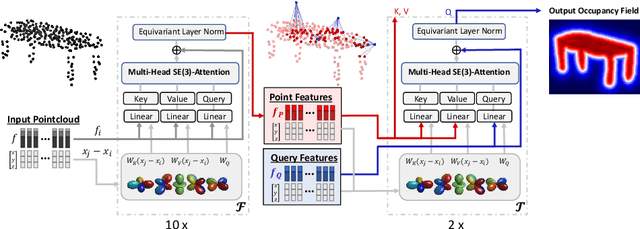
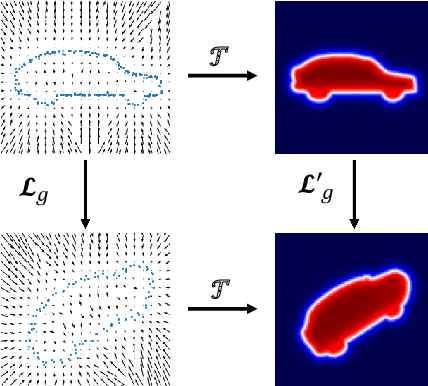
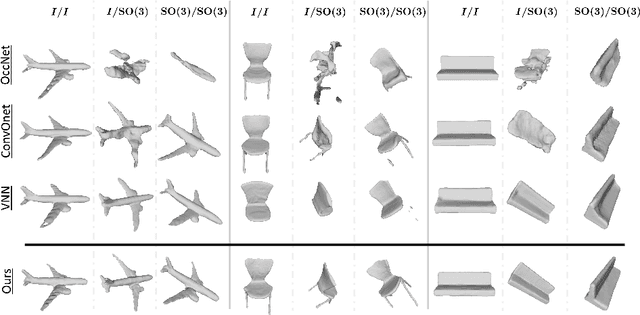
We propose the first SE(3)-equivariant coordinate-based network for learning occupancy fields from point clouds. In contrast to previous shape reconstruction methods that align the input to a regular grid, we operate directly on the irregular, unoriented point cloud. We leverage attention mechanisms in order to preserve the set structure (permutation equivariance and variable length) of the input. At the same time, attention layers enable local shape modelling, a crucial property for scalability to large scenes. In contrast to architectures that create a global signature for the shape, we operate on local tokens. Given an unoriented, sparse, noisy point cloud as input, we produce equivariant features for each point. These serve as keys and values for the subsequent equivariant cross-attention blocks that parametrize the occupancy field. By querying an arbitrary point in space, we predict its occupancy score. We show that our method outperforms previous SO(3)-equivariant methods, as well as non-equivariant methods trained on SO(3)-augmented datasets. More importantly, local modelling together with SE(3)-equivariance create an ideal setting for SE(3) scene reconstruction. We show that by training only on single objects and without any pre-segmentation, we can reconstruct a novel scene with single-object performance.
Learning Augmentation Distributions using Transformed Risk Minimization
Nov 16, 2021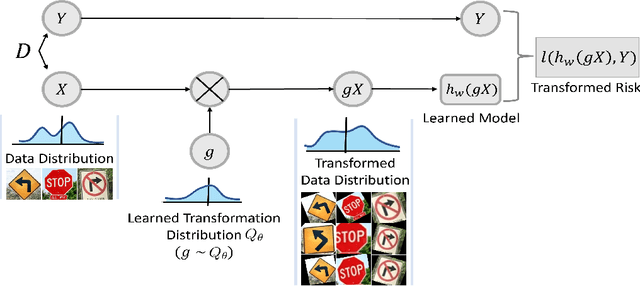

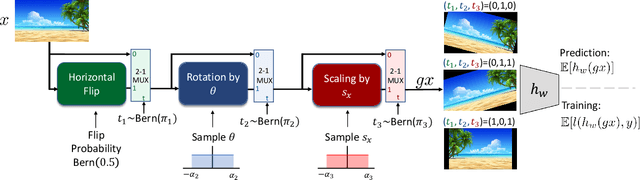

Adapting to the structure of data distributions (such as symmetry and transformation invariances) is an important challenge in machine learning. Invariances can be built into the learning process by architecture design, or by augmenting the dataset. Both require a priori knowledge about the exact nature of the symmetries. Absent this knowledge, practitioners resort to expensive and time-consuming tuning. To address this problem, we propose a new approach to learn distributions of augmentation transforms, in a new \emph{Transformed Risk Minimization} (TRM) framework. In addition to predictive models, we also optimize over transformations chosen from a hypothesis space. As an algorithmic framework, our TRM method is (1) efficient (jointly learns augmentations and models in a \emph{single training loop}), (2) modular (works with \emph{any} training algorithm), and (3) general (handles \emph{both discrete and continuous} augmentations). We theoretically compare TRM with standard risk minimization, and give a PAC-Bayes upper bound on its generalization error. We propose to optimize this bound over a rich augmentation space via a new parametrization over compositions of blocks, leading to the new \emph{Stochastic Compositional Augmentation Learning} (SCALE) algorithm. We compare SCALE experimentally with prior methods (Fast AutoAugment and Augerino) on CIFAR10/100, SVHN . Additionally, we show that SCALE can correctly learn certain symmetries in the data distribution (recovering rotations on rotated MNIST) and can also improve calibration of the learned model.
Detecting Adversarial Examples in Convolutional Neural Networks
Dec 08, 2018
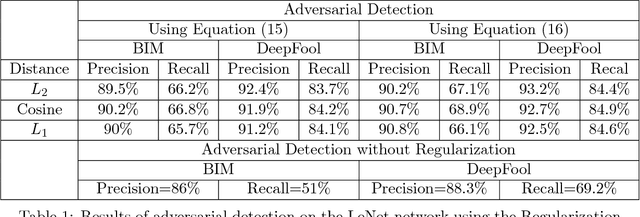
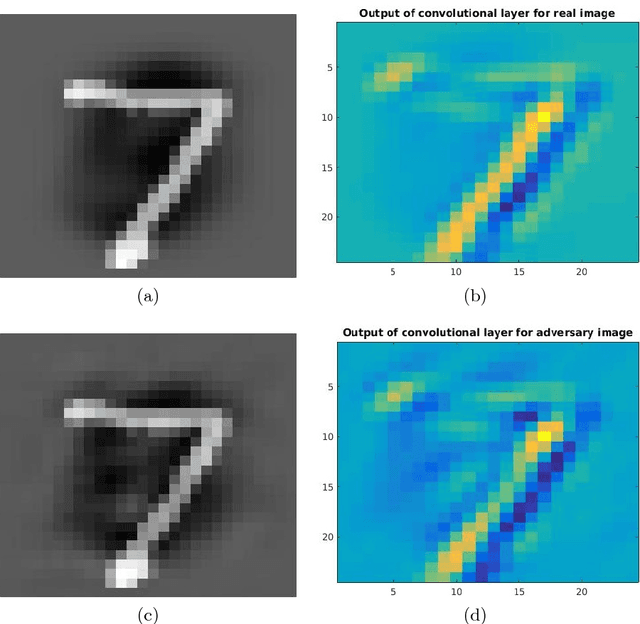
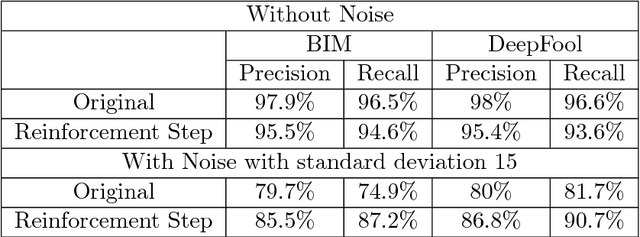
The great success of convolutional neural networks has caused a massive spread of the use of such models in a large variety of Computer Vision applications. However, these models are vulnerable to certain inputs, the adversarial examples, which although are not easily perceived by humans, they can lead a neural network to produce faulty results. This paper focuses on the detection of adversarial examples, which are created for convolutional neural networks that perform image classification. We propose three methods for detecting possible adversarial examples and after we analyze and compare their performance, we combine their best aspects to develop an even more robust approach. The first proposed method is based on the regularization of the feature vector that the neural network produces as output. The second method detects adversarial examples by using histograms, which are created from the outputs of the hidden layers of the neural network. These histograms create a feature vector which is used as the input of an SVM classifier, which classifies the original input either as an adversarial or as a real input. Finally, for the third method we introduce the concept of the residual image, which contains information about the parts of the input pattern that are ignored by the neural network. This method aims at the detection of possible adversarial examples, by using the residual image and reinforcing the parts of the input pattern that are ignored by the neural network. Each one of these methods has some novelties and by combining them we can further improve the detection results. For the proposed methods and their combination, we present the results of detecting adversarial examples on the MNIST dataset. The combination of the proposed methods offers some improvements over similar state of the art approaches.