 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOctoSense: Self-Supervised Learning for Multimodal Robot Perception
Jun 25, 2026We present OctoSense, an open-source sensor platform with stereo RGB and event cameras, LiDAR, a thermal camera, an inertial measurement unit, RTK-corrected global positioning system, and proprioception (CAN bus data from a car, and joint angles for a quadruped robot). The eponymous OctoSense dataset contains 59 hours of time-synchronized driving data across different types of environments at different times of the day, including situations with highly degraded sensors. We demonstrate multi-modal self-supervised learning using such real-world robotics data, where sensors have different representations, frequencies, latencies and noise. Our approach, a "late-fusion" masked autoencoder, (i) uses modality-specific tokenizers to account for different spatiotemporal characteristics of these sensors, and (ii) caches modality-specific tokens at inference time to process new measurements as they come. This architecture (i) is fast (6.68 ms and 112 ms on NVIDIA 5090 and Orin NX respectively, to compute the representation), (ii) performs better than existing image-only foundation models on tasks such as estimation of optical flow, depth, semantic segmentation, and ego-motion (translation, rotation, and steering angle), and (iii) predicts robustly at nighttime or in situations where sensory data is degraded. See our project page for links to the dataset, code, and supplementary videos: https://abisulco.com/octosense/.
Reinforcement Learning for Flow-Matching Policies with Density Transport
Jun 07, 2026We present an online reinforcement learning (RL) algorithm for fine-tuning flow-matching policies in continuous-control problems. Our key insight is to view RL-based policy improvement as a transport of action densities towards regions of high reward, which naturally aligns with the transport formulation of flow matching models. Prior methods either approximate the current or optimal policy distribution or resort to distillation, which introduces biased gradients or sacrifices multimodal modeling capacity. In contrast, our approach for RL with Density Transport, which we name \emph{RLDT}, constructs a transport field from a maximum-entropy RL objective using Stein Variational Gradient Descent (SVGD). Then, it finetunes a pretrained flow matching policy to align with this field. Training with this alignment objective is nontrivial because flow-matching policies generate actions via a multi-step process, making direct gradient-based optimization challenging. To overcome this challenge and stabilize training, we approximate policy actions from intermediate denoising steps via expected-target estimation. This allows the transport-field update to propagate into the network parameters without unstable backpropagation through time. Experimental results demonstrate that RLDT outperforms competitive baselines in reward quality and convergence speed. This performance holds across diverse continuous-control tasks, encompassing both dense and sparse rewards, as well as state- and vision-based long-horizon robot manipulation. The project webpage is \href{https://rpfey.github.io/rldt/}{https://rpfey.github.io/rldt/}.
Match-Any-Events: Zero-Shot Motion-Robust Feature Matching Across Wide Baselines for Event Cameras
Apr 20, 2026Event cameras have recently shown promising capabilities in instantaneous motion estimation due to their robustness to low light and fast motions. However, computing wide-baseline correspondence between two arbitrary views remains a significant challenge, since event appearance changes substantially with motion, and learning-based approaches are constrained by both scalability and limited wide-baseline supervision. We therefore introduce the first event matching model that achieves cross-dataset wide-baseline correspondence in a zero-shot manner: a single model trained once is deployed on unseen datasets without any target-domain fine-tuning or adaptation. To enable this capability, we introduce a motion-robust and computationally efficient attention backbone that learns multi-timescale features from event streams, augmented with sparsity-aware event token selection, making large-scale training on diverse wide-baseline supervision computationally feasible. To provide the supervision needed for wide-baseline generalization, we develop a robust event motion synthesis framework to generate large-scale event-matching datasets with augmented viewpoints, modalities, and motions. Extensive experiments across multiple benchmarks show that our framework achieves a 37.7% improvement over the previous best event feature matching methods. Code and data are available at: https://github.com/spikelab-jhu/Match-Any-Events.
VGGT-HPE: Reframing Head Pose Estimation as Relative Pose Prediction
Apr 11, 2026Monocular head pose estimation is traditionally formulated as direct regression from a single image to an absolute pose. This paradigm forces the network to implicitly internalize a dataset-specific canonical reference frame. In this work, we argue that predicting the relative rigid transformation between two observed head configurations is a fundamentally easier and more robust formulation. We introduce VGGT-HPE, a relative head pose estimator built upon a general-purpose geometry foundation model. Finetuned exclusively on synthetic facial renderings, our method sidesteps the need for an implicit anchor by reducing the problem to estimating a geometric displacement from an explicitly provided anchor with a known pose. As a practical benefit, the relative formulation also allows the anchor to be chosen at test time - for instance, a near-neutral frame or a temporally adjacent one - so that the prediction difficulty can be controlled by the application. Despite zero real-world training data, VGGT-HPE achieves state-of-the-art results on the BIWI benchmark, outperforming established absolute regression methods trained on mixed and real datasets. Through controlled easy- and hard-pair benchmarks, we also systematically validate our core hypothesis: relative prediction is intrinsically more accurate than absolute regression, with the advantage scaling alongside the difficulty of the target pose. Project page and code: https://vasilikivas.github.io/VGGT-HPE
OmniGuide: Universal Guidance Fields for Enhancing Generalist Robot Policies
Mar 09, 2026Vision-language-action(VLA) models have shown great promise as generalist policies for a large range of relatively simple tasks. However, they demonstrate limited performance on more complex tasks, such as those requiring complex spatial or semantic understanding, manipulation in clutter, or precise manipulation. We propose OMNIGUIDE, a flexible framework that improves VLA performance on such tasks by leveraging arbitrary sources of guidance, such as 3D foundation models, semantic-reasoning VLMs, and human pose models. We show how many kinds of guidance can be naturally expressed as differentiable energy functions with task-specific attractors and repellers located in 3D space, that influence the sampling of VLA actions. In this way, OMNIGUIDE enables guidance sources with complementary task-relevant strengths to improve a VLA model's performance on challenging tasks. Extensive experiments in both simulation and real-world environments, across diverse sources of guidance, demonstrate that OMNIGUIDE enhances the performance of state-of-the-art generalist policies (e.g., $π_{0.5}$, GR00T N1.6) significantly across success and safety rates. Critically, our unified framework matches or surpasses the performance of prior methods designed to incorporate specific sources of guidance into VLA policies. Project Page: $\href{https://omniguide.github.io/}{this \; url}$
Electrostatics-Inspired Surface Reconstruction (EISR): Recovering 3D Shapes as a Superposition of Poisson's PDE Solutions
Feb 12, 2026Implicit shape representation, such as SDFs, is a popular approach to recover the surface of a 3D shape as the level sets of a scalar field. Several methods approximate SDFs using machine learning strategies that exploit the knowledge that SDFs are solutions of the Eikonal partial differential equation (PDEs). In this work, we present a novel approach to surface reconstruction by encoding it as a solution to a proxy PDE, namely Poisson's equation. Then, we explore the connection between Poisson's equation and physics, e.g., the electrostatic potential due to a positive charge density. We employ Green's functions to obtain a closed-form parametric expression for the PDE's solution, and leverage the linearity of our proxy PDE to find the target shape's implicit field as a superposition of solutions. Our method shows improved results in approximating high-frequency details, even with a small number of shape priors.
Recurrent Equivariant Constraint Modulation: Learning Per-Layer Symmetry Relaxation from Data
Feb 02, 2026Equivariant neural networks exploit underlying task symmetries to improve generalization, but strict equivariance constraints can induce more complex optimization dynamics that can hinder learning. Prior work addresses these limitations by relaxing strict equivariance during training, but typically relies on prespecified, explicit, or implicit target levels of relaxation for each network layer, which are task-dependent and costly to tune. We propose Recurrent Equivariant Constraint Modulation (RECM), a layer-wise constraint modulation mechanism that learns appropriate relaxation levels solely from the training signal and the symmetry properties of each layer's input-target distribution, without requiring any prior knowledge about the task-dependent target relaxation level. We demonstrate that under the proposed RECM update, the relaxation level of each layer provably converges to a value upper-bounded by its symmetry gap, namely the degree to which its input-target distribution deviates from exact symmetry. Consequently, layers processing symmetric distributions recover full equivariance, while those with approximate symmetries retain sufficient flexibility to learn non-symmetric solutions when warranted by the data. Empirically, RECM outperforms prior methods across diverse exact and approximate equivariant tasks, including the challenging molecular conformer generation on the GEOM-Drugs dataset.
Next Best View Selections for Semantic and Dynamic 3D Gaussian Splatting
Dec 28, 2025Understanding semantics and dynamics has been crucial for embodied agents in various tasks. Both tasks have much more data redundancy than the static scene understanding task. We formulate the view selection problem as an active learning problem, where the goal is to prioritize frames that provide the greatest information gain for model training. To this end, we propose an active learning algorithm with Fisher Information that quantifies the informativeness of candidate views with respect to both semantic Gaussian parameters and deformation networks. This formulation allows our method to jointly handle semantic reasoning and dynamic scene modeling, providing a principled alternative to heuristic or random strategies. We evaluate our method on large-scale static images and dynamic video datasets by selecting informative frames from multi-camera setups. Experimental results demonstrate that our approach consistently improves rendering quality and semantic segmentation performance, outperforming baseline methods based on random selection and uncertainty-based heuristics.
Zero-shot Reconstruction of In-Scene Object Manipulation from Video
Dec 22, 2025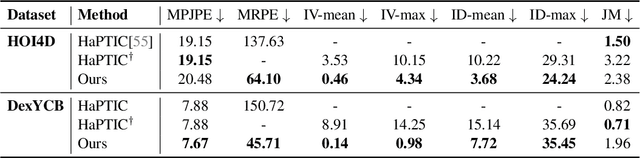
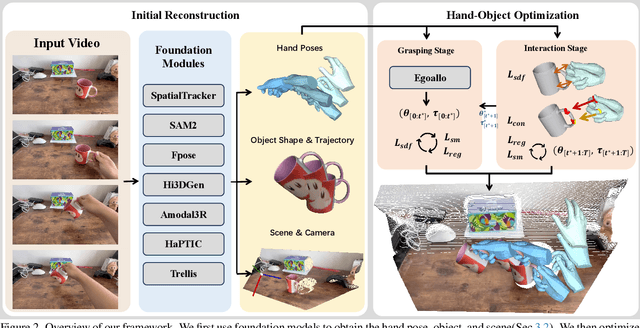
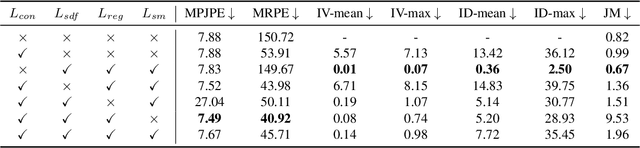
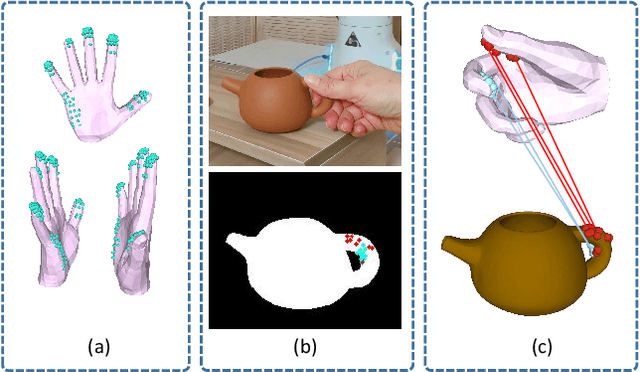
We build the first system to address the problem of reconstructing in-scene object manipulation from a monocular RGB video. It is challenging due to ill-posed scene reconstruction, ambiguous hand-object depth, and the need for physically plausible interactions. Existing methods operate in hand centric coordinates and ignore the scene, hindering metric accuracy and practical use. In our method, we first use data-driven foundation models to initialize the core components, including the object mesh and poses, the scene point cloud, and the hand poses. We then apply a two-stage optimization that recovers a complete hand-object motion from grasping to interaction, which remains consistent with the scene information observed in the input video.
A Multi-Robot Platform for Robotic Triage Combining Onboard Sensing and Foundation Models
Dec 09, 2025
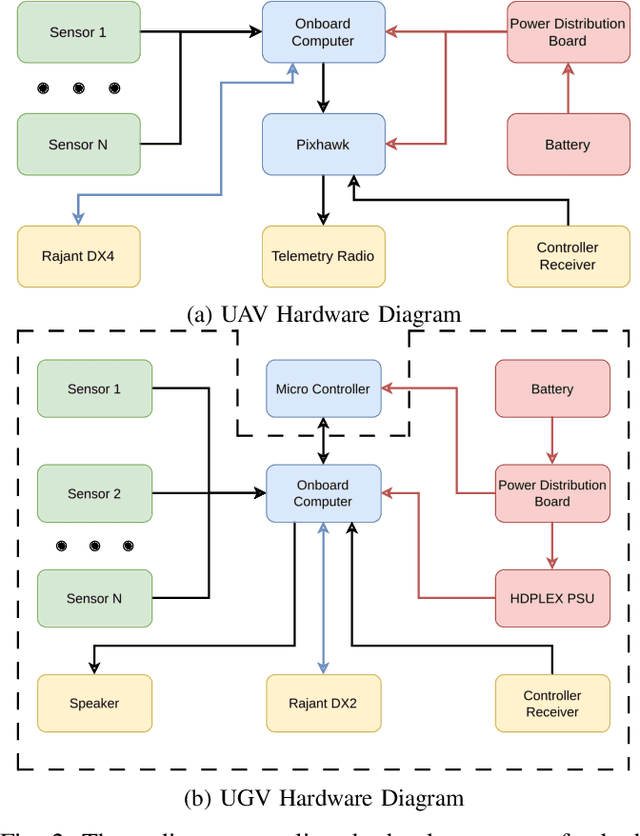
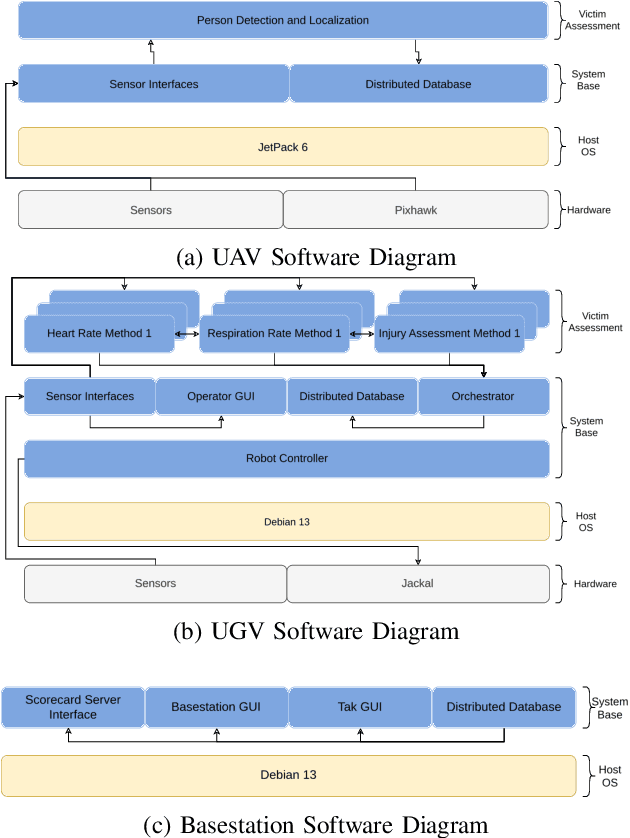
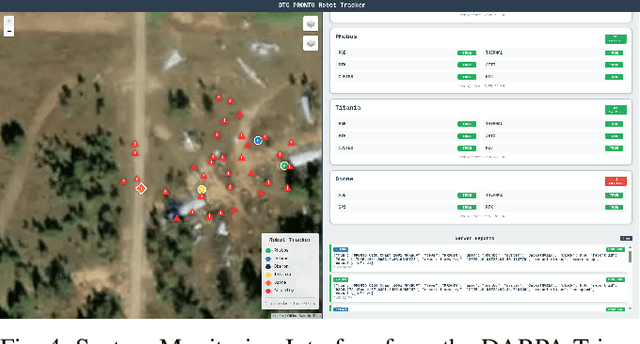
This report presents a heterogeneous robotic system designed for remote primary triage in mass-casualty incidents (MCIs). The system employs a coordinated air-ground team of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) to locate victims, assess their injuries, and prioritize medical assistance without risking the lives of first responders. The UAV identify and provide overhead views of casualties, while UGVs equipped with specialized sensors measure vital signs and detect and localize physical injuries. Unlike previous work that focused on exploration or limited medical evaluation, this system addresses the complete triage process: victim localization, vital sign measurement, injury severity classification, mental status assessment, and data consolidation for first responders. Developed as part of the DARPA Triage Challenge, this approach demonstrates how multi-robot systems can augment human capabilities in disaster response scenarios to maximize lives saved.