 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoSHI: A Versatile Robot-oriented Suit for Human Data In-the-Wild
Apr 08, 2026Scaling up robot learning will likely require human data containing rich and long-horizon interactions in the wild. Existing approaches for collecting such data trade off portability, robustness to occlusion, and global consistency. We introduce RoSHI, a hybrid wearable that fuses low-cost sparse IMUs with the Project Aria glasses to estimate the full 3D pose and body shape of the wearer in a metric global coordinate frame from egocentric perception. This system is motivated by the complementarity of the two sensors: IMUs provide robustness to occlusions and high-speed motions, while egocentric SLAM anchors long-horizon motion and stabilizes upper body pose. We collect a dataset of agile activities to evaluate RoSHI. On this dataset, we generally outperform other egocentric baselines and perform comparably to a state-of-the-art exocentric baseline (SAM3D). Finally, we demonstrate that the motion data recorded from our system are suitable for real-world humanoid policy learning. For videos, data and more, visit the project webpage: https://roshi-mocap.github.io/
A Linear N-Point Solver for Structure and Motion from Asynchronous Tracks
Jul 30, 2025Structure and continuous motion estimation from point correspondences is a fundamental problem in computer vision that has been powered by well-known algorithms such as the familiar 5-point or 8-point algorithm. However, despite their acclaim, these algorithms are limited to processing point correspondences originating from a pair of views each one representing an instantaneous capture of the scene. Yet, in the case of rolling shutter cameras, or more recently, event cameras, this synchronization breaks down. In this work, we present a unified approach for structure and linear motion estimation from 2D point correspondences with arbitrary timestamps, from an arbitrary set of views. By formulating the problem in terms of first-order dynamics and leveraging a constant velocity motion model, we derive a novel, linear point incidence relation allowing for the efficient recovery of both linear velocity and 3D points with predictable degeneracies and solution multiplicities. Owing to its general formulation, it can handle correspondences from a wide range of sensing modalities such as global shutter, rolling shutter, and event cameras, and can even combine correspondences from different collocated sensors. We validate the effectiveness of our solver on both simulated and real-world data, where we show consistent improvement across all modalities when compared to recent approaches. We believe our work opens the door to efficient structure and motion estimation from asynchronous data. Code can be found at https://github.com/suhang99/AsyncTrack-Motion-Solver.
Neural Inertial Odometry from Lie Events
May 14, 2025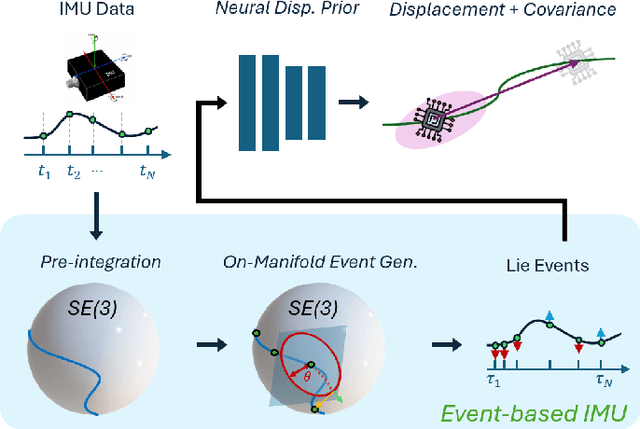
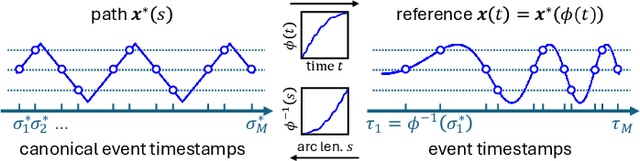
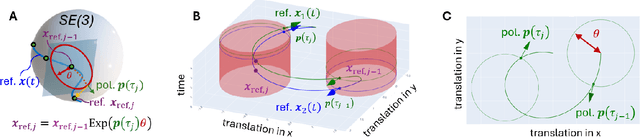

Neural displacement priors (NDP) can reduce the drift in inertial odometry and provide uncertainty estimates that can be readily fused with off-the-shelf filters. However, they fail to generalize to different IMU sampling rates and trajectory profiles, which limits their robustness in diverse settings. To address this challenge, we replace the traditional NDP inputs comprising raw IMU data with Lie events that are robust to input rate changes and have favorable invariances when observed under different trajectory profiles. Unlike raw IMU data sampled at fixed rates, Lie events are sampled whenever the norm of the IMU pre-integration change, mapped to the Lie algebra of the SE(3) group, exceeds a threshold. Inspired by event-based vision, we generalize the notion of level-crossing on 1D signals to level-crossings on the Lie algebra and generalize binary polarities to normalized Lie polarities within this algebra. We show that training NDPs on Lie events incorporating these polarities reduces the trajectory error of off-the-shelf downstream inertial odometry methods by up to 21% with only minimal preprocessing. We conjecture that many more sensors than IMUs or cameras can benefit from an event-based sampling paradigm and that this work makes an important first step in this direction.
Event-based Tracking of Any Point with Motion-Robust Correlation Features
Nov 28, 2024



Tracking any point (TAP) recently shifted the motion estimation paradigm from focusing on individual salient points with local templates to tracking arbitrary points with global image contexts. However, while research has mostly focused on driving the accuracy of models in nominal settings, addressing scenarios with difficult lighting conditions and high-speed motions remains out of reach due to the limitations of the sensor. This work addresses this challenge with the first event camera-based TAP method. It leverages the high temporal resolution and high dynamic range of event cameras for robust high-speed tracking, and the global contexts in TAP methods to handle asynchronous and sparse event measurements. We further extend the TAP framework to handle event feature variations induced by motion - thereby addressing an open challenge in purely event-based tracking - with a novel feature alignment loss which ensures the learning of motion-robust features. Our method is trained with data from a new data generation pipeline and systematically ablated across all design decisions. Our method shows strong cross-dataset generalization and performs 135% better on the average Jaccard metric than the baselines. Moreover, on an established feature tracking benchmark, it achieves a 19% improvement over the previous best event-only method and even surpasses the previous best events-and-frames method by 3.7%.
EqNIO: Subequivariant Neural Inertial Odometry
Aug 12, 2024


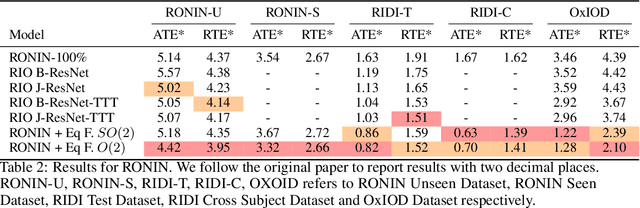
Presently, neural networks are widely employed to accurately estimate 2D displacements and associated uncertainties from Inertial Measurement Unit (IMU) data that can be integrated into stochastic filter networks like the Extended Kalman Filter (EKF) as measurements and uncertainties for the update step in the filter. However, such neural approaches overlook symmetry which is a crucial inductive bias for model generalization. This oversight is notable because (i) physical laws adhere to symmetry principles when considering the gravity axis, meaning there exists the same transformation for both the physical entity and the resulting trajectory, and (ii) displacements should remain equivariant to frame transformations when the inertial frame changes. To address this, we propose a subequivariant framework by: (i) deriving fundamental layers such as linear and nonlinear layers for a subequivariant network, designed to handle sequences of vectors and scalars, (ii) employing the subequivariant network to predict an equivariant frame for the sequence of inertial measurements. This predicted frame can then be utilized for extracting invariant features through projection, which are integrated with arbitrary network architectures, (iii) transforming the invariant output by frame transformation to obtain equivariant displacements and covariances. We demonstrate the effectiveness and generalization of our Equivariant Framework on a filter-based approach with TLIO architecture for TLIO and Aria datasets, and an end-to-end deep learning approach with RONIN architecture for RONIN, RIDI and OxIOD datasets.
An N-Point Linear Solver for Line and Motion Estimation with Event Cameras
Apr 01, 2024



Event cameras respond primarily to edges--formed by strong gradients--and are thus particularly well-suited for line-based motion estimation. Recent work has shown that events generated by a single line each satisfy a polynomial constraint which describes a manifold in the space-time volume. Multiple such constraints can be solved simultaneously to recover the partial linear velocity and line parameters. In this work, we show that, with a suitable line parametrization, this system of constraints is actually linear in the unknowns, which allows us to design a novel linear solver. Unlike existing solvers, our linear solver (i) is fast and numerically stable since it does not rely on expensive root finding, (ii) can solve both minimal and overdetermined systems with more than 5 events, and (iii) admits the characterization of all degenerate cases and multiple solutions. The found line parameters are singularity-free and have a fixed scale, which eliminates the need for auxiliary constraints typically encountered in previous work. To recover the full linear camera velocity we fuse observations from multiple lines with a novel velocity averaging scheme that relies on a geometrically-motivated residual, and thus solves the problem more efficiently than previous schemes which minimize an algebraic residual. Extensive experiments in synthetic and real-world settings demonstrate that our method surpasses the previous work in numerical stability, and operates over 600 times faster.
A 5-Point Minimal Solver for Event Camera Relative Motion Estimation
Sep 29, 2023Event-based cameras are ideal for line-based motion estimation, since they predominantly respond to edges in the scene. However, accurately determining the camera displacement based on events continues to be an open problem. This is because line feature extraction and dynamics estimation are tightly coupled when using event cameras, and no precise model is currently available for describing the complex structures generated by lines in the space-time volume of events. We solve this problem by deriving the correct non-linear parametrization of such manifolds, which we term eventails, and demonstrate its application to event-based linear motion estimation, with known rotation from an Inertial Measurement Unit. Using this parametrization, we introduce a novel minimal 5-point solver that jointly estimates line parameters and linear camera velocity projections, which can be fused into a single, averaged linear velocity when considering multiple lines. We demonstrate on both synthetic and real data that our solver generates more stable relative motion estimates than other methods while capturing more inliers than clustering based on spatio-temporal planes. In particular, our method consistently achieves a 100% success rate in estimating linear velocity where existing closed-form solvers only achieve between 23% and 70%. The proposed eventails contribute to a better understanding of spatio-temporal event-generated geometries and we thus believe it will become a core building block of future event-based motion estimation algorithms.
End-to-End Learned Event- and Image-based Visual Odometry
Sep 18, 2023Visual Odometry (VO) is crucial for autonomous robotic navigation, especially in GPS-denied environments like planetary terrains. While standard RGB cameras struggle in low-light or high-speed motion, event-based cameras offer high dynamic range and low latency. However, seamlessly integrating asynchronous event data with synchronous frames remains challenging. We introduce RAMP-VO, the first end-to-end learned event- and image-based VO system. It leverages novel Recurrent, Asynchronous, and Massively Parallel (RAMP) encoders that are 8x faster and 20% more accurate than existing asynchronous encoders. RAMP-VO further employs a novel pose forecasting technique to predict future poses for initialization. Despite being trained only in simulation, RAMP-VO outperforms image- and event-based methods by 52% and 20%, respectively, on traditional, real-world benchmarks as well as newly introduced Apollo and Malapert landing sequences, paving the way for robust and asynchronous VO in space.
E-Calib: A Fast, Robust and Accurate Calibration Toolbox for Event Cameras
Jun 15, 2023Event cameras triggered a paradigm shift in the computer vision community delineated by their asynchronous nature, low latency, and high dynamic range. Calibration of event cameras is always essential to account for the sensor intrinsic parameters and for 3D perception. However, conventional image-based calibration techniques are not applicable due to the asynchronous, binary output of the sensor. The current standard for calibrating event cameras relies on either blinking patterns or event-based image reconstruction algorithms. These approaches are difficult to deploy in factory settings and are affected by noise and artifacts degrading the calibration performance. To bridge these limitations, we present E-Calib, a novel, fast, robust, and accurate calibration toolbox for event cameras utilizing the asymmetric circle grid, for its robustness to out-of-focus scenes. The proposed method is tested in a variety of rigorous experiments for different event camera models, on circle grids with different geometric properties, and under challenging illumination conditions. The results show that our approach outperforms the state-of-the-art in detection success rate, reprojection error, and estimation accuracy of extrinsic parameters.
From Chaos Comes Order: Ordering Event Representations for Object Detection
Apr 27, 2023

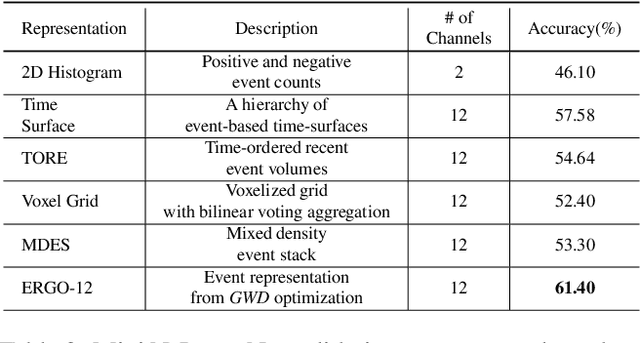

Today, state-of-the-art deep neural networks that process events first convert them into dense, grid-like input representations before using an off-the-shelf network. However, selecting the appropriate representation for the task traditionally requires training a neural network for each representation and selecting the best one based on the validation score, which is very time-consuming. In this work, we eliminate this bottleneck by selecting the best representation based on the Gromov-Wasserstein Discrepancy (GWD) between the raw events and their representation. It is approximately 200 times faster to compute than training a neural network and preserves the task performance ranking of event representations across multiple representations, network backbones, and datasets. This means that finding a representation with a high task score is equivalent to finding a representation with a low GWD. We use this insight to, for the first time, perform a hyperparameter search on a large family of event representations, revealing new and powerful representations that exceed the state-of-the-art. On object detection, our optimized representation outperforms existing representations by 1.9% mAP on the 1 Mpx dataset and 8.6% mAP on the Gen1 dataset and even outperforms the state-of-the-art by 1.8% mAP on Gen1 and state-of-the-art feed-forward methods by 6.0% mAP on the 1 Mpx dataset. This work opens a new unexplored field of explicit representation optimization for event-based learning methods.