 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Linear N-Point Solver for Structure and Motion from Asynchronous Tracks
Jul 30, 2025Structure and continuous motion estimation from point correspondences is a fundamental problem in computer vision that has been powered by well-known algorithms such as the familiar 5-point or 8-point algorithm. However, despite their acclaim, these algorithms are limited to processing point correspondences originating from a pair of views each one representing an instantaneous capture of the scene. Yet, in the case of rolling shutter cameras, or more recently, event cameras, this synchronization breaks down. In this work, we present a unified approach for structure and linear motion estimation from 2D point correspondences with arbitrary timestamps, from an arbitrary set of views. By formulating the problem in terms of first-order dynamics and leveraging a constant velocity motion model, we derive a novel, linear point incidence relation allowing for the efficient recovery of both linear velocity and 3D points with predictable degeneracies and solution multiplicities. Owing to its general formulation, it can handle correspondences from a wide range of sensing modalities such as global shutter, rolling shutter, and event cameras, and can even combine correspondences from different collocated sensors. We validate the effectiveness of our solver on both simulated and real-world data, where we show consistent improvement across all modalities when compared to recent approaches. We believe our work opens the door to efficient structure and motion estimation from asynchronous data. Code can be found at https://github.com/suhang99/AsyncTrack-Motion-Solver.
InfoGNN: End-to-end deep learning on mesh via graph neural networks
Mar 04, 2025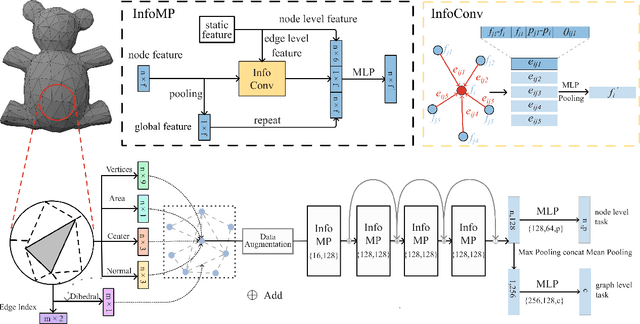


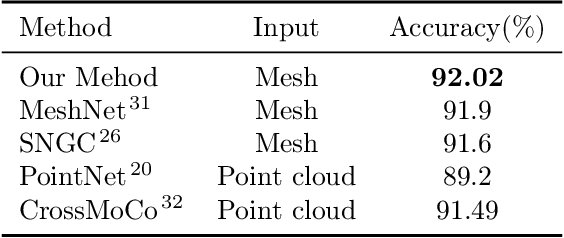
3D models are widely used in various industries, and mesh data has become an indispensable part of 3D modeling because of its unique advantages. Mesh data can provide an intuitive and practical expression of rich 3D information. However, its disordered, irregular data structure and complex surface information make it challenging to apply with deep learning models directly. Traditional mesh data processing methods often rely on mesh models with many limitations, such as manifold, which restrict their application scopes in reality and do not fully utilize the advantages of mesh models. This paper proposes a novel end-to-end framework for addressing the challenges associated with deep learning in mesh models centered around graph neural networks (GNN) and is titled InfoGNN. InfoGNN treats the mesh model as a graph, which enables it to handle irregular mesh data efficiently. Moreover, we propose InfoConv and InfoMP modules, which utilize the position information of the points and fully use the static information such as face normals, dihedral angles, and dynamic global feature information to fully use all kinds of data. In addition, InfoGNN is an end-to-end framework, and we simplify the network design to make it more efficient, paving the way for efficient deep learning of complex 3D models. We conducted experiments on several publicly available datasets, and the results show that InfoGNN achieves excellent performance in mesh classification and segmentation tasks.
Optimizing Personalized Federated Learning through Adaptive Layer-Wise Learning
Dec 10, 2024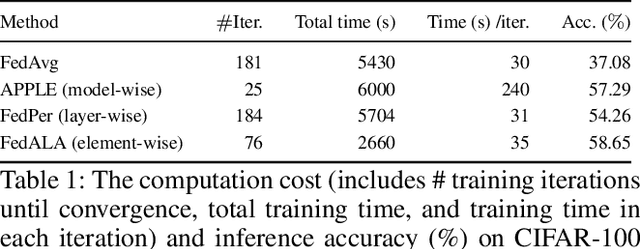
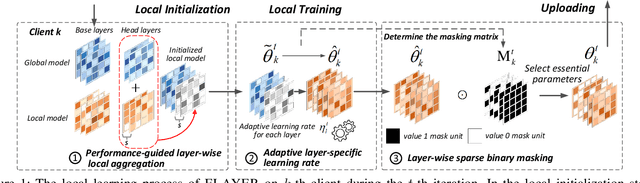
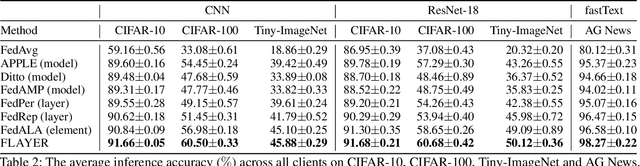
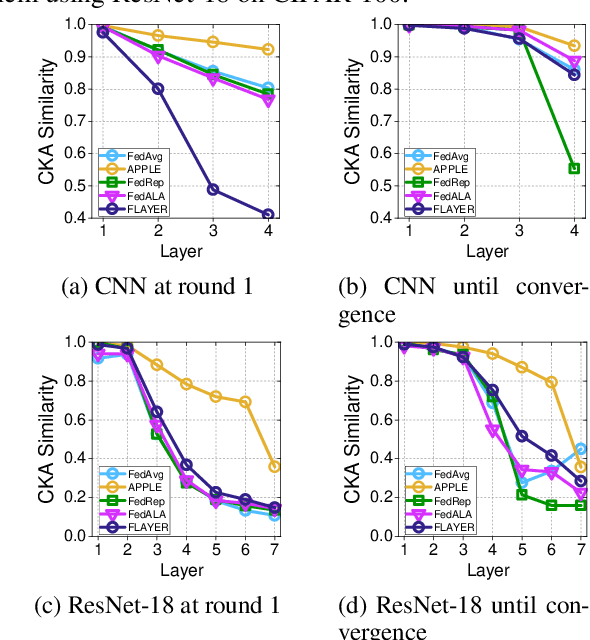
Real-life deployment of federated Learning (FL) often faces non-IID data, which leads to poor accuracy and slow convergence. Personalized FL (pFL) tackles these issues by tailoring local models to individual data sources and using weighted aggregation methods for client-specific learning. However, existing pFL methods often fail to provide each local model with global knowledge on demand while maintaining low computational overhead. Additionally, local models tend to over-personalize their data during the training process, potentially dropping previously acquired global information. We propose FLAYER, a novel layer-wise learning method for pFL that optimizes local model personalization performance. FLAYER considers the different roles and learning abilities of neural network layers of individual local models. It incorporates global information for each local model as needed to initialize the local model cost-effectively. It then dynamically adjusts learning rates for each layer during local training, optimizing the personalized learning process for each local model while preserving global knowledge. Additionally, to enhance global representation in pFL, FLAYER selectively uploads parameters for global aggregation in a layer-wise manner. We evaluate FLAYER on four representative datasets in computer vision and natural language processing domains. Compared to six state-of-the-art pFL methods, FLAYER improves the inference accuracy, on average, by 5.42% (up to 14.29%).
Motion-Aware Optical Camera Communication with Event Cameras
Dec 01, 2024As the ubiquity of smart mobile devices continues to rise, Optical Camera Communication systems have gained more attention as a solution for efficient and private data streaming. This system utilizes optical cameras to receive data from digital screens via visible light. Despite their promise, most of them are hindered by dynamic factors such as screen refreshing and rapid camera motion. CMOS cameras, often serving as the receivers, suffer from limited frame rates and motion-induced image blur, which degrade overall performance. To address these challenges, this paper unveils a novel system that utilizes event cameras. We introduce a dynamic visual marker and design event-based tracking algorithms to achieve fast localization and data streaming. Remarkably, the event camera's unique capabilities mitigate issues related to screen refresh rates and camera motion, enabling a high throughput of up to 114 Kbps in static conditions, and a 1 cm localization accuracy with 1% bit error rate under various camera motions.
An N-Point Linear Solver for Line and Motion Estimation with Event Cameras
Apr 01, 2024



Event cameras respond primarily to edges--formed by strong gradients--and are thus particularly well-suited for line-based motion estimation. Recent work has shown that events generated by a single line each satisfy a polynomial constraint which describes a manifold in the space-time volume. Multiple such constraints can be solved simultaneously to recover the partial linear velocity and line parameters. In this work, we show that, with a suitable line parametrization, this system of constraints is actually linear in the unknowns, which allows us to design a novel linear solver. Unlike existing solvers, our linear solver (i) is fast and numerically stable since it does not rely on expensive root finding, (ii) can solve both minimal and overdetermined systems with more than 5 events, and (iii) admits the characterization of all degenerate cases and multiple solutions. The found line parameters are singularity-free and have a fixed scale, which eliminates the need for auxiliary constraints typically encountered in previous work. To recover the full linear camera velocity we fuse observations from multiple lines with a novel velocity averaging scheme that relies on a geometrically-motivated residual, and thus solves the problem more efficiently than previous schemes which minimize an algebraic residual. Extensive experiments in synthetic and real-world settings demonstrate that our method surpasses the previous work in numerical stability, and operates over 600 times faster.
A 5-Point Minimal Solver for Event Camera Relative Motion Estimation
Sep 29, 2023Event-based cameras are ideal for line-based motion estimation, since they predominantly respond to edges in the scene. However, accurately determining the camera displacement based on events continues to be an open problem. This is because line feature extraction and dynamics estimation are tightly coupled when using event cameras, and no precise model is currently available for describing the complex structures generated by lines in the space-time volume of events. We solve this problem by deriving the correct non-linear parametrization of such manifolds, which we term eventails, and demonstrate its application to event-based linear motion estimation, with known rotation from an Inertial Measurement Unit. Using this parametrization, we introduce a novel minimal 5-point solver that jointly estimates line parameters and linear camera velocity projections, which can be fused into a single, averaged linear velocity when considering multiple lines. We demonstrate on both synthetic and real data that our solver generates more stable relative motion estimates than other methods while capturing more inliers than clustering based on spatio-temporal planes. In particular, our method consistently achieves a 100% success rate in estimating linear velocity where existing closed-form solvers only achieve between 23% and 70%. The proposed eventails contribute to a better understanding of spatio-temporal event-generated geometries and we thus believe it will become a core building block of future event-based motion estimation algorithms.
VECtor: A Versatile Event-Centric Benchmark for Multi-Sensor SLAM
Jul 04, 2022



Event cameras have recently gained in popularity as they hold strong potential to complement regular cameras in situations of high dynamics or challenging illumination. An important problem that may benefit from the addition of an event camera is given by Simultaneous Localization And Mapping (SLAM). However, in order to ensure progress on event-inclusive multi-sensor SLAM, novel benchmark sequences are needed. Our contribution is the first complete set of benchmark datasets captured with a multi-sensor setup containing an event-based stereo camera, a regular stereo camera, multiple depth sensors, and an inertial measurement unit. The setup is fully hardware-synchronized and underwent accurate extrinsic calibration. All sequences come with ground truth data captured by highly accurate external reference devices such as a motion capture system. Individual sequences include both small and large-scale environments, and cover the specific challenges targeted by dynamic vision sensors.
Globally-Optimal Contrast Maximisation for Event Cameras
Jun 10, 2022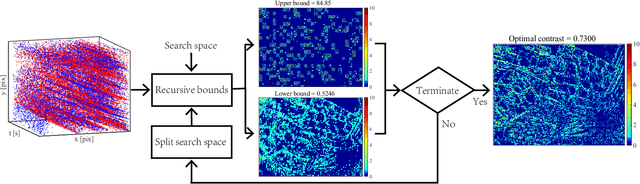

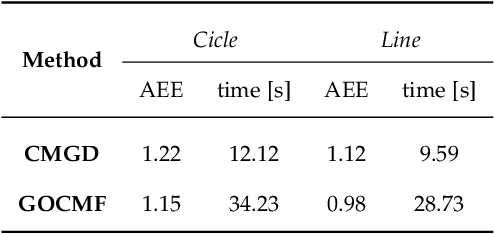
Event cameras are bio-inspired sensors that perform well in challenging illumination conditions and have high temporal resolution. However, their concept is fundamentally different from traditional frame-based cameras. The pixels of an event camera operate independently and asynchronously. They measure changes of the logarithmic brightness and return them in the highly discretised form of time-stamped events indicating a relative change of a certain quantity since the last event. New models and algorithms are needed to process this kind of measurements. The present work looks at several motion estimation problems with event cameras. The flow of the events is modelled by a general homographic warping in a space-time volume, and the objective is formulated as a maximisation of contrast within the image of warped events. Our core contribution consists of deriving globally optimal solutions to these generally non-convex problems, which removes the dependency on a good initial guess plaguing existing methods. Our methods rely on branch-and-bound optimisation and employ novel and efficient, recursive upper and lower bounds derived for six different contrast estimation functions. The practical validity of our approach is demonstrated by a successful application to three different event camera motion estimation problems.
* arXiv admin note: substantial text overlap with arXiv:2203.03914
Exploring the Impact of Negative Samples of Contrastive Learning: A Case Study of Sentence Embedding
Mar 16, 2022

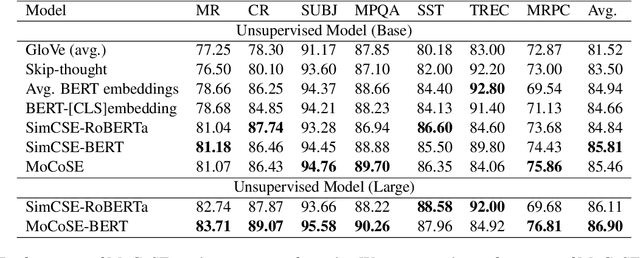
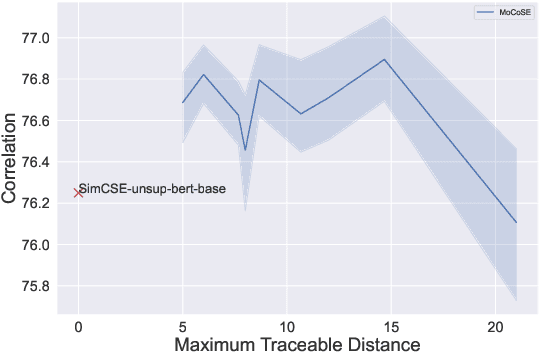
Contrastive learning is emerging as a powerful technique for extracting knowledge from unlabeled data. This technique requires a balanced mixture of two ingredients: positive (similar) and negative (dissimilar) samples. This is typically achieved by maintaining a queue of negative samples during training. Prior works in the area typically uses a fixed-length negative sample queue, but how the negative sample size affects the model performance remains unclear. The opaque impact of the number of negative samples on performance when employing contrastive learning aroused our in-depth exploration. This paper presents a momentum contrastive learning model with negative sample queue for sentence embedding, namely MoCoSE. We add the prediction layer to the online branch to make the model asymmetric and together with EMA update mechanism of the target branch to prevent the model from collapsing. We define a maximum traceable distance metric, through which we learn to what extent the text contrastive learning benefits from the historical information of negative samples. Our experiments find that the best results are obtained when the maximum traceable distance is at a certain range, demonstrating that there is an optimal range of historical information for a negative sample queue. We evaluate the proposed unsupervised MoCoSE on the semantic text similarity (STS) task and obtain an average Spearman's correlation of $77.27\%$. Source code is available at https://github.com/xbdxwyh/mocose.
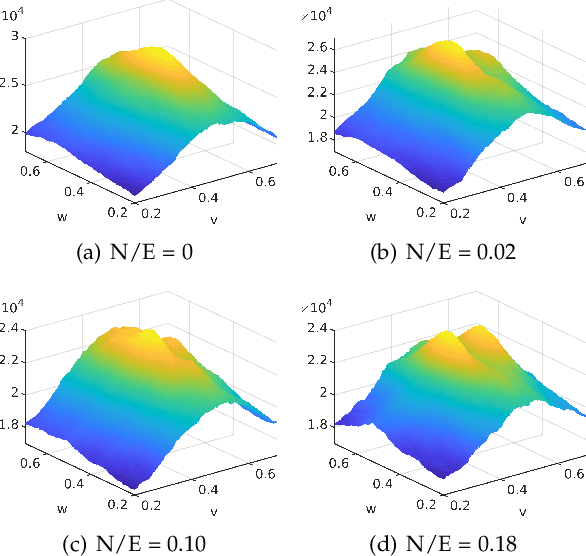
Globally-Optimal Event Camera Motion Estimation
Mar 08, 2022

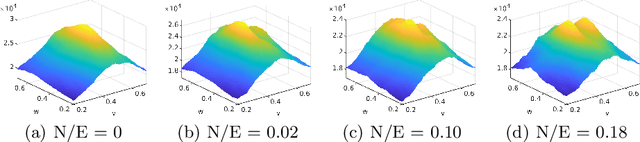

Event cameras are bio-inspired sensors that perform well in HDR conditions and have high temporal resolution. However, different from traditional frame-based cameras, event cameras measure asynchronous pixel-level brightness changes and return them in a highly discretised format, hence new algorithms are needed. The present paper looks at fronto-parallel motion estimation of an event camera. The flow of the events is modeled by a general homographic warping in a space-time volume, and the objective is formulated as a maximisation of contrast within the image of unwarped events. However, in stark contrast to prior art, we derive a globally optimal solution to this generally non-convex problem, and thus remove the dependency on a good initial guess. Our algorithm relies on branch-and-bound optimisation for which we derive novel, recursive upper and lower bounds for six different contrast estimation functions. The practical validity of our approach is supported by a highly successful application to AGV motion estimation with a downward facing event camera, a challenging scenario in which the sensor experiences fronto-parallel motion in front of noisy, fast moving textures.