 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCMBench: A Comprehensive Financial Credit Multimodal Benchmark for Real-world Applications
Jan 06, 2026As multimodal AI becomes widely used for credit risk assessment and document review, a domain-specific benchmark is urgently needed that (1) reflects documents and workflows specific to financial credit applications, (2) includes credit-specific understanding and real-world robustness, and (3) preserves privacy compliance without sacrificing practical utility. Here, we introduce FCMBench-V1.0 -- a large-scale financial credit multimodal benchmark for real-world applications, covering 18 core certificate types, with 4,043 privacy-compliant images and 8,446 QA samples. The FCMBench evaluation framework consists of three dimensions: Perception, Reasoning, and Robustness, including 3 foundational perception tasks, 4 credit-specific reasoning tasks that require decision-oriented understanding of visual evidence, and 10 real-world acquisition artifact types for robustness stress testing. To reconcile compliance with realism, we construct all samples via a closed synthesis-capture pipeline: we manually synthesize document templates with virtual content and capture scenario-aware images in-house. This design also mitigates pre-training data leakage by avoiding web-sourced or publicly released images. FCMBench can effectively discriminate performance disparities and robustness across modern vision-language models. Extensive experiments were conducted on 23 state-of-the-art vision-language models (VLMs) from 14 top AI companies and research institutes. Among them, Gemini 3 Pro achieves the best F1(\%) score as a commercial model (64.61), Qwen3-VL-235B achieves the best score as an open-source baseline (57.27), and our financial credit-specific model, Qfin-VL-Instruct, achieves the top overall score (64.92). Robustness evaluations show that even top-performing models suffer noticeable performance drops under acquisition artifacts.
L2Calib: $SE(3)$-Manifold Reinforcement Learning for Robust Extrinsic Calibration with Degenerate Motion Resilience
Aug 08, 2025Extrinsic calibration is essential for multi-sensor fusion, existing methods rely on structured targets or fully-excited data, limiting real-world applicability. Online calibration further suffers from weak excitation, leading to unreliable estimates. To address these limitations, we propose a reinforcement learning (RL)-based extrinsic calibration framework that formulates extrinsic calibration as a decision-making problem, directly optimizes $SE(3)$ extrinsics to enhance odometry accuracy. Our approach leverages a probabilistic Bingham distribution to model 3D rotations, ensuring stable optimization while inherently retaining quaternion symmetry. A trajectory alignment reward mechanism enables robust calibration without structured targets by quantitatively evaluating estimated tightly-coupled trajectory against a reference trajectory. Additionally, an automated data selection module filters uninformative samples, significantly improving efficiency and scalability for large-scale datasets. Extensive experiments on UAVs, UGVs, and handheld platforms demonstrate that our method outperforms traditional optimization-based approaches, achieving high-precision calibration even under weak excitation conditions. Our framework simplifies deployment on diverse robotic platforms by eliminating the need for high-quality initial extrinsics and enabling calibration from routine operating data. The code is available at https://github.com/APRIL-ZJU/learn-to-calibrate.
FlashDP: Private Training Large Language Models with Efficient DP-SGD
Jul 01, 2025As large language models (LLMs) increasingly underpin technological advancements, the privacy of their training data emerges as a critical concern. Differential Privacy (DP) serves as a rigorous mechanism to protect this data, yet its integration via Differentially Private Stochastic Gradient Descent (DP-SGD) introduces substantial challenges, primarily due to the complexities of per-sample gradient clipping. Current explicit methods, such as Opacus, necessitate extensive storage for per-sample gradients, significantly inflating memory requirements. Conversely, implicit methods like GhostClip reduce storage needs by recalculating gradients multiple times, which leads to inefficiencies due to redundant computations. This paper introduces FlashDP, an innovative cache-friendly per-layer DP-SGD that consolidates necessary operations into a single task, calculating gradients only once in a fused manner. This approach not only diminishes memory movement by up to \textbf{50\%} but also cuts down redundant computations by \textbf{20\%}, compared to previous methods. Consequently, FlashDP does not increase memory demands and achieves a \textbf{90\%} throughput compared to the Non-DP method on a four-A100 system during the pre-training of the Llama-13B model, while maintaining parity with standard per-layer clipped DP-SGD in terms of accuracy. These advancements establish FlashDP as a pivotal development for efficient and privacy-preserving training of LLMs. FlashDP's code has been open-sourced in https://github.com/kaustpradalab/flashdp.
SoK: Machine Unlearning for Large Language Models
Jun 10, 2025

Large language model (LLM) unlearning has become a critical topic in machine learning, aiming to eliminate the influence of specific training data or knowledge without retraining the model from scratch. A variety of techniques have been proposed, including Gradient Ascent, model editing, and re-steering hidden representations. While existing surveys often organize these methods by their technical characteristics, such classifications tend to overlook a more fundamental dimension: the underlying intention of unlearning--whether it seeks to truly remove internal knowledge or merely suppress its behavioral effects. In this SoK paper, we propose a new taxonomy based on this intention-oriented perspective. Building on this taxonomy, we make three key contributions. First, we revisit recent findings suggesting that many removal methods may functionally behave like suppression, and explore whether true removal is necessary or achievable. Second, we survey existing evaluation strategies, identify limitations in current metrics and benchmarks, and suggest directions for developing more reliable and intention-aligned evaluations. Third, we highlight practical challenges--such as scalability and support for sequential unlearning--that currently hinder the broader deployment of unlearning methods. In summary, this work offers a comprehensive framework for understanding and advancing unlearning in generative AI, aiming to support future research and guide policy decisions around data removal and privacy.
VITON-DRR: Details Retention Virtual Try-on via Non-rigid Registration
May 29, 2025Image-based virtual try-on aims to fit a target garment to a specific person image and has attracted extensive research attention because of its huge application potential in the e-commerce and fashion industries. To generate high-quality try-on results, accurately warping the clothing item to fit the human body plays a significant role, as slight misalignment may lead to unrealistic artifacts in the fitting image. Most existing methods warp the clothing by feature matching and thin-plate spline (TPS). However, it often fails to preserve clothing details due to self-occlusion, severe misalignment between poses, etc. To address these challenges, this paper proposes a detail retention virtual try-on method via accurate non-rigid registration (VITON-DRR) for diverse human poses. Specifically, we reconstruct a human semantic segmentation using a dual-pyramid-structured feature extractor. Then, a novel Deformation Module is designed for extracting the cloth key points and warping them through an accurate non-rigid registration algorithm. Finally, the Image Synthesis Module is designed to synthesize the deformed garment image and generate the human pose information adaptively. {Compared with} traditional methods, the proposed VITON-DRR can make the deformation of fitting images more accurate and retain more garment details. The experimental results demonstrate that the proposed method performs better than state-of-the-art methods.
Beyond Text: Unveiling Privacy Vulnerabilities in Multi-modal Retrieval-Augmented Generation
May 20, 2025Multimodal Retrieval-Augmented Generation (MRAG) systems enhance LMMs by integrating external multimodal databases, but introduce unexplored privacy vulnerabilities. While text-based RAG privacy risks have been studied, multimodal data presents unique challenges. We provide the first systematic analysis of MRAG privacy vulnerabilities across vision-language and speech-language modalities. Using a novel compositional structured prompt attack in a black-box setting, we demonstrate how attackers can extract private information by manipulating queries. Our experiments reveal that LMMs can both directly generate outputs resembling retrieved content and produce descriptions that indirectly expose sensitive information, highlighting the urgent need for robust privacy-preserving MRAG techniques.
On the Cone Effect in the Learning Dynamics
Mar 20, 2025Understanding the learning dynamics of neural networks is a central topic in the deep learning community. In this paper, we take an empirical perspective to study the learning dynamics of neural networks in real-world settings. Specifically, we investigate the evolution process of the empirical Neural Tangent Kernel (eNTK) during training. Our key findings reveal a two-phase learning process: i) in Phase I, the eNTK evolves significantly, signaling the rich regime, and ii) in Phase II, the eNTK keeps evolving but is constrained in a narrow space, a phenomenon we term the cone effect. This two-phase framework builds on the hypothesis proposed by Fort et al. (2020), but we uniquely identify the cone effect in Phase II, demonstrating its significant performance advantages over fully linearized training.
ZO2: Scalable Zeroth-Order Fine-Tuning for Extremely Large Language Models with Limited GPU Memory
Mar 16, 2025Fine-tuning large pre-trained LLMs generally demands extensive GPU memory. Traditional first-order optimizers like SGD encounter substantial difficulties due to increased memory requirements from storing activations and gradients during both the forward and backward phases as the model size expands. Alternatively, zeroth-order (ZO) techniques can compute gradients using just forward operations, eliminating the need to store activations. Furthermore, by leveraging CPU capabilities, it's feasible to enhance both the memory and processing power available to a single GPU. We propose a novel framework, ZO2 (Zeroth-Order Offloading), for efficient zeroth-order fine-tuning of LLMs with only limited GPU memory. Our framework dynamically shifts model parameters between the CPU and GPU as required, optimizing computation flow and maximizing GPU usage by minimizing downtime. This integration of parameter adjustments with ZO's double forward operations reduces unnecessary data movement, enhancing the fine-tuning efficacy. Additionally, our framework supports an innovative low-bit precision approach in AMP mode to streamline data exchanges between the CPU and GPU. Employing this approach allows us to fine-tune extraordinarily large models, such as the OPT-175B with more than 175 billion parameters, on a mere 18GB GPU--achievements beyond the reach of traditional methods. Moreover, our framework achieves these results with almost no additional time overhead and absolutely no accuracy loss compared to standard zeroth-order methods. ZO2's code has been open-sourced in https://github.com/liangyuwang/zo2.
A General Framework to Enhance Fine-tuning-based LLM Unlearning
Feb 25, 2025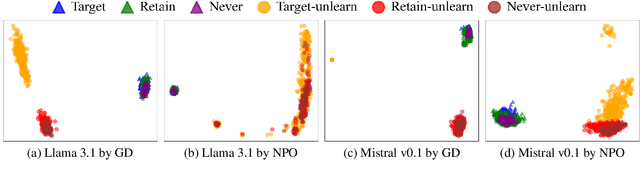
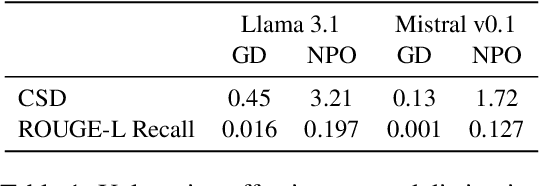
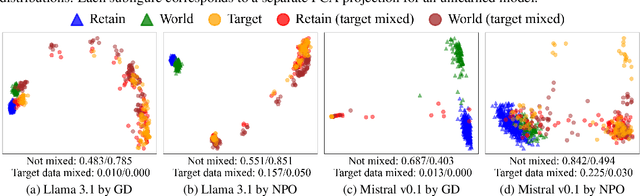
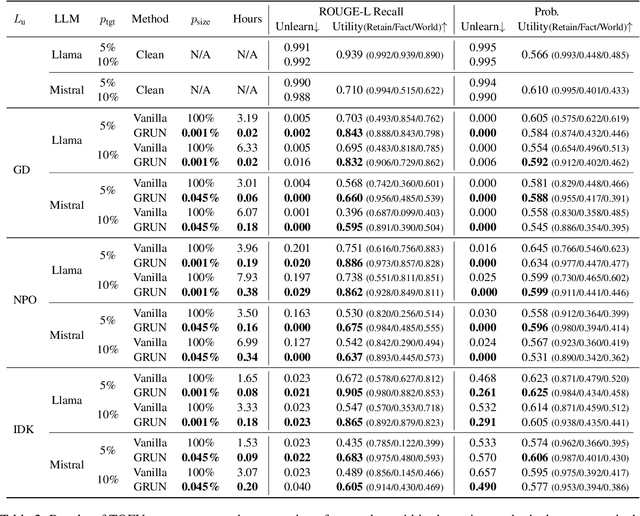
Unlearning has been proposed to remove copyrighted and privacy-sensitive data from Large Language Models (LLMs). Existing approaches primarily rely on fine-tuning-based methods, which can be categorized into gradient ascent-based (GA-based) and suppression-based methods. However, they often degrade model utility (the ability to respond to normal prompts). In this work, we aim to develop a general framework that enhances the utility of fine-tuning-based unlearning methods. To achieve this goal, we first investigate the common property between GA-based and suppression-based methods. We unveil that GA-based methods unlearn by distinguishing the target data (i.e., the data to be removed) and suppressing related generations, which is essentially the same strategy employed by suppression-based methods. Inspired by this finding, we introduce Gated Representation UNlearning (GRUN) which has two components: a soft gate function for distinguishing target data and a suppression module using Representation Fine-tuning (ReFT) to adjust representations rather than model parameters. Experiments show that GRUN significantly improves the unlearning and utility. Meanwhile, it is general for fine-tuning-based methods, efficient and promising for sequential unlearning.
SETS: Leveraging Self-Verification and Self-Correction for Improved Test-Time Scaling
Jan 31, 2025



Recent advancements in Large Language Models (LLMs) have created new opportunities to enhance performance on complex reasoning tasks by leveraging test-time computation. However, conventional approaches such as repeated sampling with majority voting or reward model scoring, often face diminishing returns as test-time compute scales, in addition to requiring costly task-specific reward model training. In this paper, we present Self-Enhanced Test-Time Scaling (SETS), a novel method that leverages the self-verification and self-correction capabilities of recent advanced LLMs to overcome these limitations. SETS integrates sampling, self-verification, and self-correction into a unified framework, enabling efficient and scalable test-time computation for improved capabilities at complex tasks. Through extensive experiments on challenging planning and reasoning benchmarks, compared to the alternatives, we demonstrate that SETS achieves significant performance improvements and more favorable test-time scaling laws.