 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Should Express Uncertainty Explicitly
Apr 07, 2026Large language models are increasingly used in settings where uncertainty must drive decisions such as abstention, retrieval, and verification. Most existing methods treat uncertainty as a latent quantity to estimate after generation rather than a signal the model is trained to express. We instead study uncertainty as an interface for control. We compare two complementary interfaces: a global interface, where the model verbalizes a calibrated confidence score for its final answer, and a local interface, where the model emits an explicit <uncertain> marker during reasoning when it enters a high-risk state. These interfaces provide different but complementary benefits. Verbalized confidence substantially improves calibration, reduces overconfident errors, and yields the strongest overall Adaptive RAG controller while using retrieval more selectively. Reasoning-time uncertainty signaling makes previously silent failures visible during generation, improves wrong-answer coverage, and provides an effective high-recall retrieval trigger. Our findings further show that the two interfaces work differently internally: verbal confidence mainly refines how existing uncertainty is decoded, whereas reasoning-time signaling induces a broader late-layer reorganization. Together, these results suggest that effective uncertainty in LLMs should be trained as task-matched communication: global confidence for deciding whether to trust a final answer, and local signals for deciding when intervention is needed.
Reward-Safety Balance in Offline Safe RL via Diffusion Regularization
Feb 18, 2025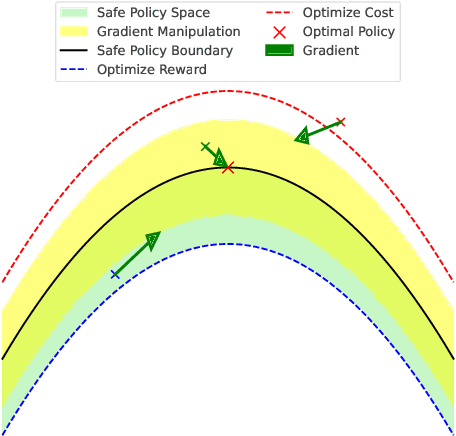

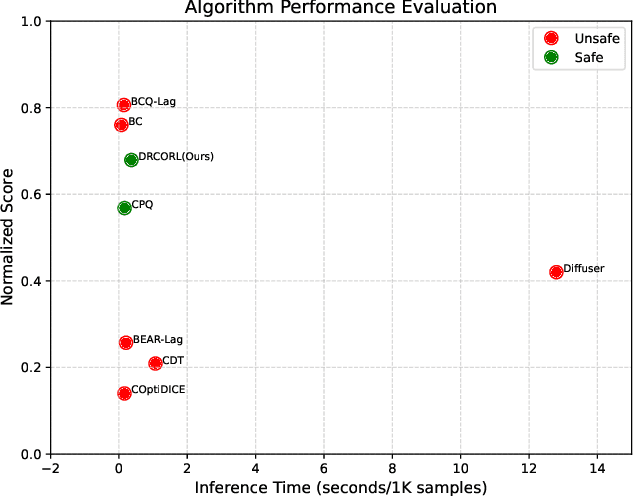
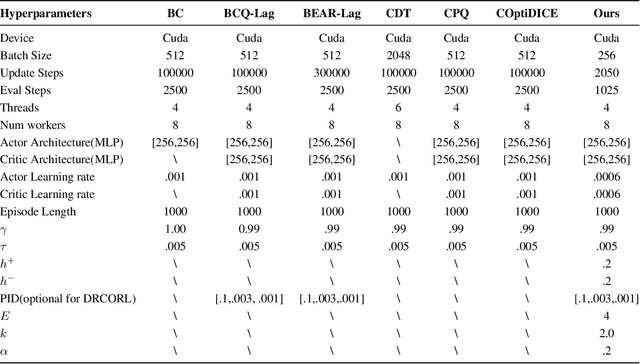
Constrained reinforcement learning (RL) seeks high-performance policies under safety constraints. We focus on an offline setting where the agent has only a fixed dataset -- common in realistic tasks to prevent unsafe exploration. To address this, we propose Diffusion-Regularized Constrained Offline Reinforcement Learning (DRCORL), which first uses a diffusion model to capture the behavioral policy from offline data and then extracts a simplified policy to enable efficient inference. We further apply gradient manipulation for safety adaptation, balancing the reward objective and constraint satisfaction. This approach leverages high-quality offline data while incorporating safety requirements. Empirical results show that DRCORL achieves reliable safety performance, fast inference, and strong reward outcomes across robot learning tasks. Compared to existing safe offline RL methods, it consistently meets cost limits and performs well with the same hyperparameters, indicating practical applicability in real-world scenarios.
HS-FPN: High Frequency and Spatial Perception FPN for Tiny Object Detection
Dec 13, 2024



The introduction of Feature Pyramid Network (FPN) has significantly improved object detection performance. However, substantial challenges remain in detecting tiny objects, as their features occupy only a very small proportion of the feature maps. Although FPN integrates multi-scale features, it does not directly enhance or enrich the features of tiny objects. Furthermore, FPN lacks spatial perception ability. To address these issues, we propose a novel High Frequency and Spatial Perception Feature Pyramid Network (HS-FPN) with two innovative modules. First, we designed a high frequency perception module (HFP) that generates high frequency responses through high pass filters. These high frequency responses are used as mask weights from both spatial and channel perspectives to enrich and highlight the features of tiny objects in the original feature maps. Second, we developed a spatial dependency perception module (SDP) to capture the spatial dependencies that FPN lacks. Our experiments demonstrate that detectors based on HS-FPN exhibit competitive advantages over state-of-the-art models on the AI-TOD dataset for tiny object detection.
Reinforcement Learning for SBM Graphon Games with Re-Sampling
Oct 25, 2023The Mean-Field approximation is a tractable approach for studying large population dynamics. However, its assumption on homogeneity and universal connections among all agents limits its applicability in many real-world scenarios. Multi-Population Mean-Field Game (MP-MFG) models have been introduced in the literature to address these limitations. When the underlying Stochastic Block Model is known, we show that a Policy Mirror Ascent algorithm finds the MP-MFG Nash Equilibrium. In more realistic scenarios where the block model is unknown, we propose a re-sampling scheme from a graphon integrated with the finite N-player MP-MFG model. We develop a novel learning framework based on a Graphon Game with Re-Sampling (GGR-S) model, which captures the complex network structures of agents' connections. We analyze GGR-S dynamics and establish the convergence to dynamics of MP-MFG. Leveraging this result, we propose an efficient sample-based N-player Reinforcement Learning algorithm for GGR-S without population manipulation, and provide a rigorous convergence analysis with finite sample guarantee.
Automated Kidney Segmentation by Mask R-CNN in T2-weighted Magnetic Resonance Imaging
Aug 27, 2021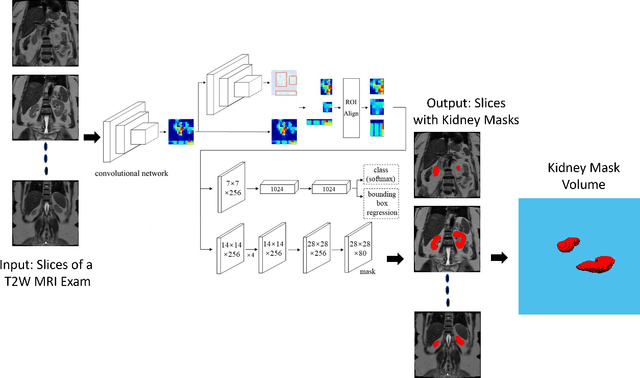


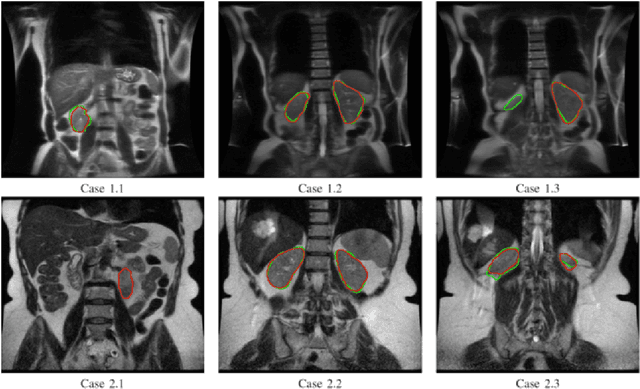
Despite the recent advances of deep learning algorithms in medical imaging, the automatic segmentation algorithms for kidneys in MRI exams are still scarce. Automated segmentation of kidneys in Magnetic Resonance Imaging (MRI) exams are important for enabling radiomics and machine learning analysis of renal disease. In this work, we propose to use the popular Mask R-CNN for the automatic segmentation of kidneys in coronal T2-weighted Fast Spin Eco slices of 100 MRI exams. We propose the morphological operations as post-processing to further improve the performance of Mask R-CNN for this task. With 5-fold cross-validation data, the proposed Mask R-CNN is trained and validated on 70 and 10 MRI exams and then evaluated on the remaining 20 exams in each fold. Our proposed method achieved a dice score of 0.904 and IoU of 0.822.
RLCard: A Toolkit for Reinforcement Learning in Card Games
Oct 10, 2019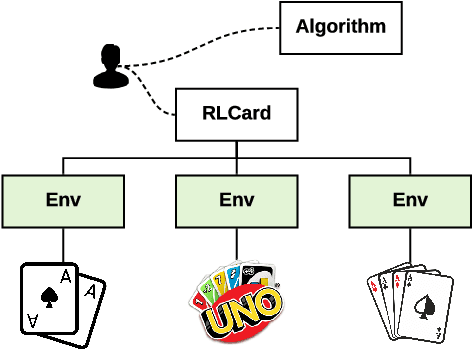

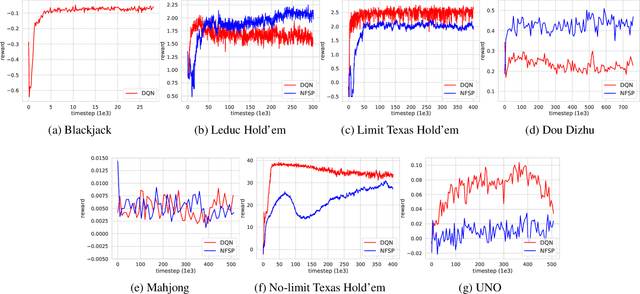
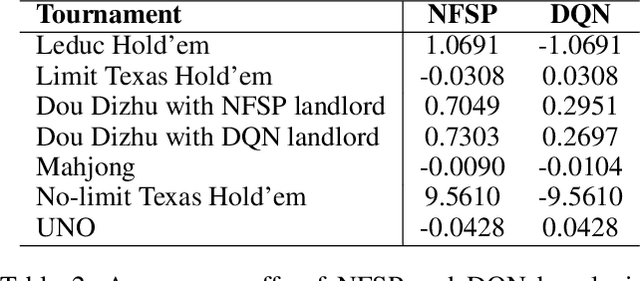
RLCard is an open-source toolkit for reinforcement learning research in card games. It supports various card environments with easy-to-use interfaces, including Blackjack, Leduc Hold'em, Texas Hold'em, UNO, Dou Dizhu and Mahjong. The goal of RLCard is to bridge reinforcement learning and imperfect information games, and push forward the research of reinforcement learning in domains with multiple agents, large state and action space, and sparse reward. In this paper, we provide an overview of the key components in RLCard, a discussion of the design principles, a brief introduction of the interfaces, and comprehensive evaluations of the environments. The codes and documents are available at https://github.com/datamllab/rlcard