 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Correspondence and Universal Approximation in Diagonal plus Low-Rank Neural Networks
May 07, 2026The massive computational costs of scaling modern deep learning architectures have driven the widespread use of parameter-efficient low-rank structures, such as LoRA and low-rank factorization. However, theoretical guarantees for their expressive power are less explored, often relying on restrictive priors like a pretrained base matrix, ReLU activations or non-verifiable singularity conditions. We first investigate the limits of neural networks constrained strictly to low-rank manifolds without pretrained dense priors. We demonstrate a theoretical paradox: while purely rank-1 layers can exactly interpolate arbitrary scalar datasets, they collapse for function approximations. To overcome this bottleneck without surrendering parameter efficiency, we introduce a unified \textit{Structural Correspondence} framework. We prove that augmenting low-rank layers with only a minimal sparse diagonal component, say a Diagonal plus Low-Rank (DLoR) structure, is sufficient to reach Universal Approximation. We show that any full-rank transformation can be exactly reconstructed using these DLoR components by trading off network width (additive decomposition) or depth (multiplicative decomposition). By tracking asymptotic Taylor remainders, we prove that DLoR neural networks fully restore the Universal Approximation Theorem for general activation functions. Finally, we establish that multiplicative depth provides superior parameter-to-expressivity scaling compared to additive width. Our results show that dense matrices and specific activation functions are not topological prerequisites for universal expressivity.
LLMs Should Express Uncertainty Explicitly
Apr 07, 2026Large language models are increasingly used in settings where uncertainty must drive decisions such as abstention, retrieval, and verification. Most existing methods treat uncertainty as a latent quantity to estimate after generation rather than a signal the model is trained to express. We instead study uncertainty as an interface for control. We compare two complementary interfaces: a global interface, where the model verbalizes a calibrated confidence score for its final answer, and a local interface, where the model emits an explicit <uncertain> marker during reasoning when it enters a high-risk state. These interfaces provide different but complementary benefits. Verbalized confidence substantially improves calibration, reduces overconfident errors, and yields the strongest overall Adaptive RAG controller while using retrieval more selectively. Reasoning-time uncertainty signaling makes previously silent failures visible during generation, improves wrong-answer coverage, and provides an effective high-recall retrieval trigger. Our findings further show that the two interfaces work differently internally: verbal confidence mainly refines how existing uncertainty is decoded, whereas reasoning-time signaling induces a broader late-layer reorganization. Together, these results suggest that effective uncertainty in LLMs should be trained as task-matched communication: global confidence for deciding whether to trust a final answer, and local signals for deciding when intervention is needed.
A Trust-Region Interior-Point Stochastic Sequential Quadratic Programming Method
Mar 10, 2026In this paper, we propose a trust-region interior-point stochastic sequential quadratic programming (TR-IP-SSQP) method for solving optimization problems with a stochastic objective and deterministic nonlinear equality and inequality constraints. In this setting, exact evaluations of the objective function and its gradient are unavailable, but their stochastic estimates can be constructed. In particular, at each iteration our method builds stochastic oracles, which estimate the objective value and gradient to satisfy proper adaptive accuracy conditions with a fixed probability. To handle inequality constraints, we adopt an interior-point method (IPM), in which the barrier parameter follows a prescribed decaying sequence. Under standard assumptions, we establish global almost-sure convergence of the proposed method to first-order stationary points. We implement the method on a subset of problems from the CUTEst test set, as well as on logistic regression problems, to demonstrate its practical performance.
Why is Normalization Preferred? A Worst-Case Complexity Theory for Stochastically Preconditioned SGD under Heavy-Tailed Noise
Feb 13, 2026We develop a worst-case complexity theory for stochastically preconditioned stochastic gradient descent (SPSGD) and its accelerated variants under heavy-tailed noise, a setting that encompasses widely used adaptive methods such as Adam, RMSProp, and Shampoo. We assume the stochastic gradient noise has a finite $p$-th moment for some $p \in (1,2]$, and measure convergence after $T$ iterations. While clipping and normalization are parallel tools for stabilizing training of SGD under heavy-tailed noise, there is a fundamental separation in their worst-case properties in stochastically preconditioned settings. We demonstrate that normalization guarantees convergence to a first-order stationary point at rate $\mathcal{O}(T^{-\frac{p-1}{3p-2}})$ when problem parameters are known, and $\mathcal{O}(T^{-\frac{p-1}{2p}})$ when problem parameters are unknown, matching the optimal rates for normalized SGD, respectively. In contrast, we prove that clipping may fail to converge in the worst case due to the statistical dependence between the stochastic preconditioner and the gradient estimates. To enable the analysis, we develop a novel vector-valued Burkholder-type inequality that may be of independent interest. These results provide a theoretical explanation for the empirical preference for normalization over clipping in large-scale model training.
3DGS$^2$-TR: Scalable Second-Order Trust-Region Method for 3D Gaussian Splatting
Jan 30, 2026We propose 3DGS$^2$-TR,a second-order optimizer for accelerating the scene training problem in 3D Gaussian Splatting (3DGS). Unlike existing second-order approaches that rely on explicit or dense curvature representations, such as 3DGS-LM (Höllein et al., 2025) or 3DGS2 (Lan et al., 2025), our method approximates curvature using only the diagonal of the Hessian matrix, efficiently via Hutchinson's method. Our approach is fully matrix-free and has the same complexity as ADAM (Kingma, 2024), $O(n)$ in both computation and memory costs. To ensure stable optimization in the presence of strong nonlinearity in the 3DGS rasterization process, we introduce a parameter-wise trust-region technique based on the squared Hellinger distance, regularizing updates to Gaussian parameters. Under identical parameter initialization and without densification, 3DGS$^2$-TR is able to achieve better reconstruction quality on standard datasets, using 50% fewer training iterations compared to ADAM, while incurring less than 1GB of peak GPU memory overhead (17% more than ADAM and 85% less than 3DGS-LM), enabling scalability to very large scenes and potentially to distributed training settings.
TRSVR: An Adaptive Stochastic Trust-Region Method with Variance Reduction
Jan 21, 2026We propose a stochastic trust-region method for unconstrained nonconvex optimization that incorporates stochastic variance-reduced gradients (SVRG) to accelerate convergence. Unlike classical trust-region methods, the proposed algorithm relies solely on stochastic gradient information and does not require function value evaluations. The trust-region radius is adaptively adjusted based on a radius-control parameter and the stochastic gradient estimate. Under mild assumptions, we establish that the algorithm converges in expectation to a first-order stationary point. Moreover, the method achieves iteration and sample complexity bounds that match those of SVRG-based first-order methods, while allowing stochastic and potentially gradient-dependent second-order information. Extensive numerical experiments demonstrate that incorporating SVRG accelerates convergence, and that the use of trust-region methods and Hessian information further improves performance. We also highlight the impact of batch size and inner-loop length on efficiency, and show that the proposed method outperforms SGD and Adam on several machine learning tasks.
Few-Shot Test-Time Optimization Without Retraining for Semiconductor Recipe Generation and Beyond
May 21, 2025


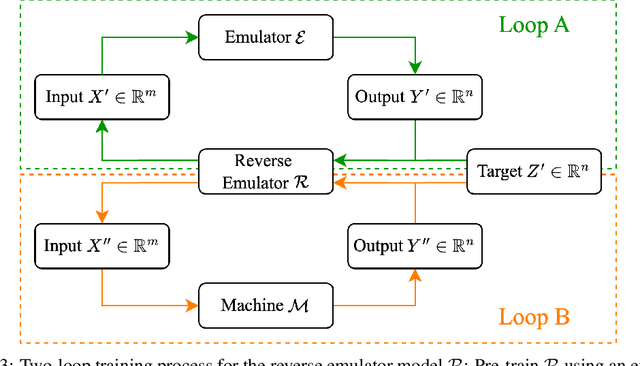
We introduce Model Feedback Learning (MFL), a novel test-time optimization framework for optimizing inputs to pre-trained AI models or deployed hardware systems without requiring any retraining of the models or modifications to the hardware. In contrast to existing methods that rely on adjusting model parameters, MFL leverages a lightweight reverse model to iteratively search for optimal inputs, enabling efficient adaptation to new objectives under deployment constraints. This framework is particularly advantageous in real-world settings, such as semiconductor manufacturing recipe generation, where modifying deployed systems is often infeasible or cost-prohibitive. We validate MFL on semiconductor plasma etching tasks, where it achieves target recipe generation in just five iterations, significantly outperforming both Bayesian optimization and human experts. Beyond semiconductor applications, MFL also demonstrates strong performance in chemical processes (e.g., chemical vapor deposition) and electronic systems (e.g., wire bonding), highlighting its broad applicability. Additionally, MFL incorporates stability-aware optimization, enhancing robustness to process variations and surpassing conventional supervised learning and random search methods in high-dimensional control settings. By enabling few-shot adaptation, MFL provides a scalable and efficient paradigm for deploying intelligent control in real-world environments.
High Probability Complexity Bounds of Trust-Region Stochastic Sequential Quadratic Programming with Heavy-Tailed Noise
Mar 24, 2025In this paper, we consider nonlinear optimization problems with a stochastic objective and deterministic equality constraints. We propose a Trust-Region Stochastic Sequential Quadratic Programming (TR-SSQP) method and establish its high-probability iteration complexity bounds for identifying first- and second-order $\epsilon$-stationary points. In our algorithm, we assume that exact objective values, gradients, and Hessians are not directly accessible but can be estimated via zeroth-, first-, and second-order probabilistic oracles. Compared to existing complexity studies of SSQP methods that rely on a zeroth-order oracle with sub-exponential tail noise (i.e., light-tailed) and focus mostly on first-order stationarity, our analysis accommodates irreducible and heavy-tailed noise in the zeroth-order oracle and significantly extends the analysis to second-order stationarity. We show that under weaker noise conditions, our method achieves the same high-probability first-order iteration complexity bounds, while also exhibiting promising second-order iteration complexity bounds. Specifically, the method identifies a first-order $\epsilon$-stationary point in $\mathcal{O}(\epsilon^{-2})$ iterations and a second-order $\epsilon$-stationary point in $\mathcal{O}(\epsilon^{-3})$ iterations with high probability, provided that $\epsilon$ is lower bounded by a constant determined by the irreducible noise level in estimation. We validate our theoretical findings and evaluate the practical performance of our method on CUTEst benchmark test set.
Subgradient Method for System Identification with Non-Smooth Objectives
Mar 20, 2025This paper investigates a subgradient-based algorithm to solve the system identification problem for linear time-invariant systems with non-smooth objectives. This is essential for robust system identification in safety-critical applications. While existing work provides theoretical exact recovery guarantees using optimization solvers, the design of fast learning algorithms with convergence guarantees for practical use remains unexplored. We analyze the subgradient method in this setting where the optimization problems to be solved change over time as new measurements are taken, and we establish linear convergence results for both the best and Polyak step sizes after a burn-in period. Additionally, we characterize the asymptotic convergence of the best average sub-optimality gap under diminishing and constant step sizes. Finally, we compare the time complexity of standard solvers with the subgradient algorithm and support our findings with experimental results. This is the first work to analyze subgradient algorithms for system identification with non-smooth objectives.
Reward-Safety Balance in Offline Safe RL via Diffusion Regularization
Feb 18, 2025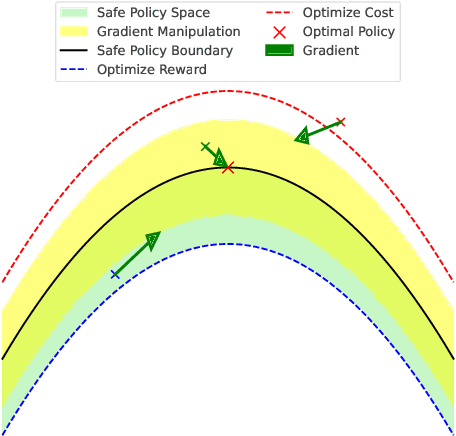

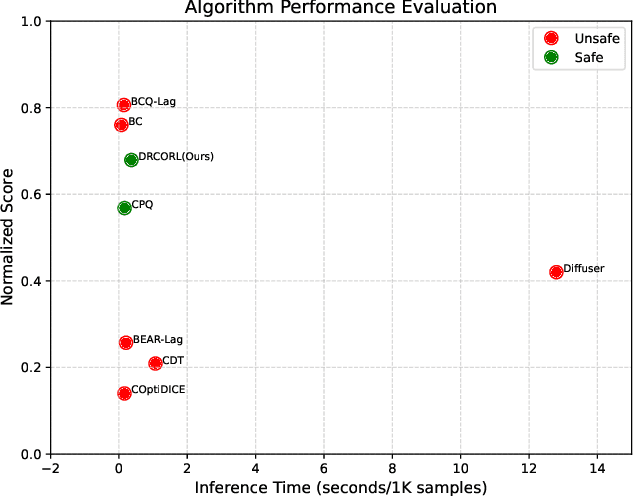
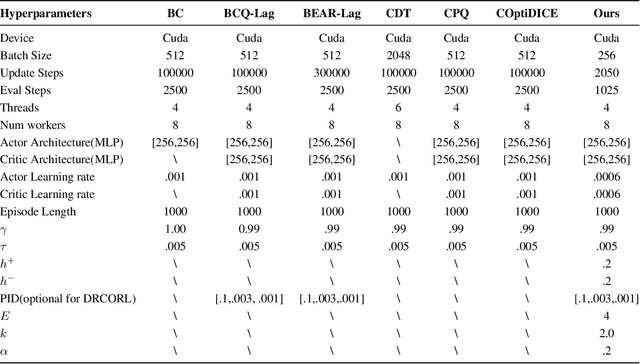
Constrained reinforcement learning (RL) seeks high-performance policies under safety constraints. We focus on an offline setting where the agent has only a fixed dataset -- common in realistic tasks to prevent unsafe exploration. To address this, we propose Diffusion-Regularized Constrained Offline Reinforcement Learning (DRCORL), which first uses a diffusion model to capture the behavioral policy from offline data and then extracts a simplified policy to enable efficient inference. We further apply gradient manipulation for safety adaptation, balancing the reward objective and constraint satisfaction. This approach leverages high-quality offline data while incorporating safety requirements. Empirical results show that DRCORL achieves reliable safety performance, fast inference, and strong reward outcomes across robot learning tasks. Compared to existing safe offline RL methods, it consistently meets cost limits and performs well with the same hyperparameters, indicating practical applicability in real-world scenarios.