 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Keye-VL-2.0 Technical Report
Jun 09, 2026We introduce Kwai Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts (MoE) multimodal foundation model designed to advance long-video understanding and agentic intelligence. To address the challenges of ultra-long contexts, information redundancy, and prohibitive computational costs inherent in hour-level videos, Keye-VL-2.0 is the first to adapt DeepSeek Sparse Attention (DSA) to GQA-based multimodal architectures, enabling lossless 256K context processing while capturing critical frames and long-range temporal dependencies. This architecture is underpinned by a highly optimized training and inference infrastructure, including scalable video I/O, heterogeneous ViT-LM parallelism, and custom DSA kernels that significantly maximize throughput and minimize computational overhead. Furthermore, to overcome the algorithmic dilemma of catastrophic forgetting during multi-task alignment, we introduce Cross-Modal Multi-Teacher On-Policy Distillation (MOPD) paired with Context-RL and Video-RL. By distilling dense token-level teacher feedback from on-policy rollouts back into the MoE backbone, which activates only 3B parameters, Keye-VL-2.0 natively empowers advanced agent collaboration across Code, Tool, and Search scenarios with multimodal self-correction. Extensive evaluations across video understanding, temporal grounding, reasoning, STEM, and agent benchmarks demonstrate that Keye-VL-2.0-30B-A3B achieves state-of-the-art performance among models of similar scale, particularly excelling in fine-grained temporal localization on TimeLens and long-video comprehension on Video-MME-v2 and LongVideoBench. We release our model checkpoints to accelerate community progress toward scalable and robust multimodal agentic applications.
Inference of Online Newton Methods with Nesterov's Accelerated Sketching
Apr 25, 2026Reliable decision-making with streaming data requires principled uncertainty quantification of online methods. While first-order methods enable efficient iterate updates, their inference procedures still require updating proper (covariance) matrices, incurring $O(d^2)$ time and memory complexity, and are sensitive to ill-conditioning and noise heterogeneity of the problem. This costly inference task offers an opportunity for more robust second-order methods, which are, however, bottlenecked by solving Newton systems with $O(d^3)$ complexity. In this paper, we address this gap by studying an online Newton method with Hessian averaging, where the Newton direction at each step is approximately computed using a sketch-and-project solver with Nesterov's acceleration, matching $O(d^2)$ complexity of first-order methods. For the proposed method, we quantify its uncertainty arising from both random data and randomized computation. Under standard smoothness and moment conditions, we establish global almost-sure convergence, prove asymptotic normality of the last iterate with a limiting covariance characterized by a Lyapunov equation, and develop a fully online covariance estimator with non-asymptotic convergence guarantees. We also connect the resulting uncertainty quantification to that of exact and sketched Newton methods without Nesterov's acceleration. Extensive experiments on regression models demonstrate the superiority of the proposed method for online inference.
A Trust-Region Interior-Point Stochastic Sequential Quadratic Programming Method
Mar 10, 2026In this paper, we propose a trust-region interior-point stochastic sequential quadratic programming (TR-IP-SSQP) method for solving optimization problems with a stochastic objective and deterministic nonlinear equality and inequality constraints. In this setting, exact evaluations of the objective function and its gradient are unavailable, but their stochastic estimates can be constructed. In particular, at each iteration our method builds stochastic oracles, which estimate the objective value and gradient to satisfy proper adaptive accuracy conditions with a fixed probability. To handle inequality constraints, we adopt an interior-point method (IPM), in which the barrier parameter follows a prescribed decaying sequence. Under standard assumptions, we establish global almost-sure convergence of the proposed method to first-order stationary points. We implement the method on a subset of problems from the CUTEst test set, as well as on logistic regression problems, to demonstrate its practical performance.
Derivative-Free Sequential Quadratic Programming for Equality-Constrained Stochastic Optimization
Oct 25, 2025We consider solving nonlinear optimization problems with a stochastic objective and deterministic equality constraints, assuming that only zero-order information is available for both the objective and constraints, and that the objective is also subject to random sampling noise. Under this setting, we propose a Derivative-Free Stochastic Sequential Quadratic Programming (DF-SSQP) method. Due to the lack of derivative information, we adopt a simultaneous perturbation stochastic approximation (SPSA) technique to randomly estimate the gradients and Hessians of both the objective and constraints. This approach requires only a dimension-independent number of zero-order evaluations -- as few as eight -- at each iteration step. A key distinction between our derivative-free and existing derivative-based SSQP methods lies in the intricate random bias introduced into the gradient and Hessian estimates of the objective and constraints, brought by stochastic zero-order approximations. To address this issue, we introduce an online debiasing technique based on momentum-style estimators that properly aggregate past gradient and Hessian estimates to reduce stochastic noise, while avoiding excessive memory costs via a moving averaging scheme. Under standard assumptions, we establish the global almost-sure convergence of the proposed DF-SSQP method. Notably, we further complement the global analysis with local convergence guarantees by demonstrating that the rescaled iterates exhibit asymptotic normality, with a limiting covariance matrix resembling the minimax optimal covariance achieved by derivative-based methods, albeit larger due to the absence of derivative information. Our local analysis enables online statistical inference of model parameters leveraging DF-SSQP. Numerical experiments on benchmark nonlinear problems demonstrate both the global and local behavior of DF-SSQP.
Online Statistical Inference of Constrained Stochastic Optimization via Random Scaling
May 23, 2025Constrained stochastic nonlinear optimization problems have attracted significant attention for their ability to model complex real-world scenarios in physics, economics, and biology. As datasets continue to grow, online inference methods have become crucial for enabling real-time decision-making without the need to store historical data. In this work, we develop an online inference procedure for constrained stochastic optimization by leveraging a method called Sketched Stochastic Sequential Quadratic Programming (SSQP). As a direct generalization of sketched Newton methods, SSQP approximates the objective with a quadratic model and the constraints with a linear model at each step, then applies a sketching solver to inexactly solve the resulting subproblem. Building on this design, we propose a new online inference procedure called random scaling. In particular, we construct a test statistic based on SSQP iterates whose limiting distribution is free of any unknown parameters. Compared to existing online inference procedures, our approach offers two key advantages: (i) it enables the construction of asymptotically valid confidence intervals; and (ii) it is matrix-free, i.e. the computation involves only primal-dual SSQP iterates $(\boldsymbol{x}_t, \boldsymbol{\lambda}_t)$ without requiring any matrix inversions. We validate our theory through numerical experiments on nonlinearly constrained regression problems and demonstrate the superior performance of our random scaling method over existing inference procedures.
High Probability Complexity Bounds of Trust-Region Stochastic Sequential Quadratic Programming with Heavy-Tailed Noise
Mar 24, 2025In this paper, we consider nonlinear optimization problems with a stochastic objective and deterministic equality constraints. We propose a Trust-Region Stochastic Sequential Quadratic Programming (TR-SSQP) method and establish its high-probability iteration complexity bounds for identifying first- and second-order $\epsilon$-stationary points. In our algorithm, we assume that exact objective values, gradients, and Hessians are not directly accessible but can be estimated via zeroth-, first-, and second-order probabilistic oracles. Compared to existing complexity studies of SSQP methods that rely on a zeroth-order oracle with sub-exponential tail noise (i.e., light-tailed) and focus mostly on first-order stationarity, our analysis accommodates irreducible and heavy-tailed noise in the zeroth-order oracle and significantly extends the analysis to second-order stationarity. We show that under weaker noise conditions, our method achieves the same high-probability first-order iteration complexity bounds, while also exhibiting promising second-order iteration complexity bounds. Specifically, the method identifies a first-order $\epsilon$-stationary point in $\mathcal{O}(\epsilon^{-2})$ iterations and a second-order $\epsilon$-stationary point in $\mathcal{O}(\epsilon^{-3})$ iterations with high probability, provided that $\epsilon$ is lower bounded by a constant determined by the irreducible noise level in estimation. We validate our theoretical findings and evaluate the practical performance of our method on CUTEst benchmark test set.
Online Covariance Matrix Estimation in Sketched Newton Methods
Feb 10, 2025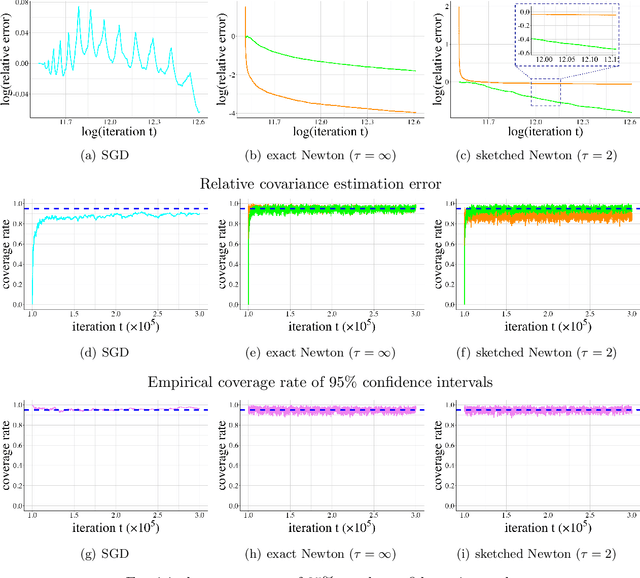
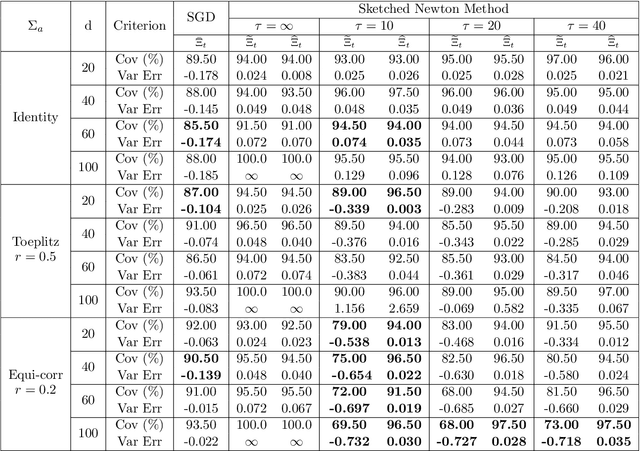
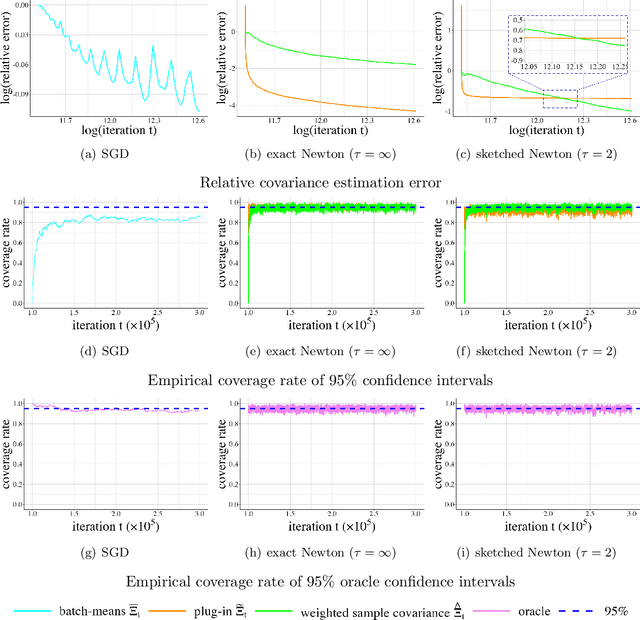
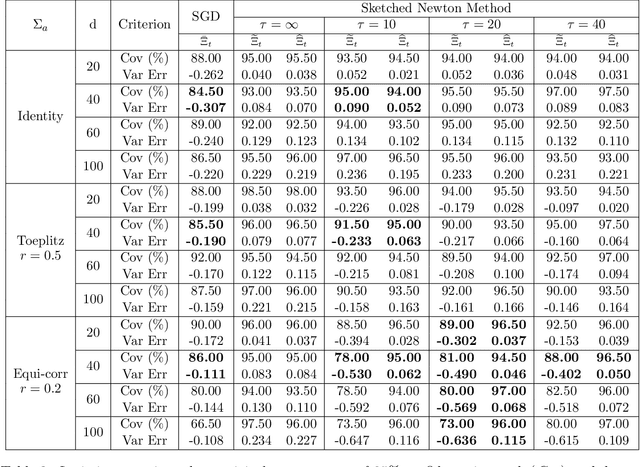
Given the ubiquity of streaming data, online algorithms have been widely used for parameter estimation, with second-order methods particularly standing out for their efficiency and robustness. In this paper, we study an online sketched Newton method that leverages a randomized sketching technique to perform an approximate Newton step in each iteration, thereby eliminating the computational bottleneck of second-order methods. While existing studies have established the asymptotic normality of sketched Newton methods, a consistent estimator of the limiting covariance matrix remains an open problem. We propose a fully online covariance matrix estimator that is constructed entirely from the Newton iterates and requires no matrix factorization. Compared to covariance estimators for first-order online methods, our estimator for second-order methods is batch-free. We establish the consistency and convergence rate of our estimator, and coupled with asymptotic normality results, we can then perform online statistical inference for the model parameters based on sketched Newton methods. We also discuss the extension of our estimator to constrained problems, and demonstrate its superior performance on regression problems as well as benchmark problems in the CUTEst set.
Online Covariance Estimation in Nonsmooth Stochastic Approximation
Feb 07, 2025
We consider applying stochastic approximation (SA) methods to solve nonsmooth variational inclusion problems. Existing studies have shown that the averaged iterates of SA methods exhibit asymptotic normality, with an optimal limiting covariance matrix in the local minimax sense of H\'ajek and Le Cam. However, no methods have been proposed to estimate this covariance matrix in a nonsmooth and potentially non-monotone (nonconvex) setting. In this paper, we study an online batch-means covariance matrix estimator introduced in Zhu et al.(2023). The estimator groups the SA iterates appropriately and computes the sample covariance among batches as an estimate of the limiting covariance. Its construction does not require prior knowledge of the total sample size, and updates can be performed recursively as new data arrives. We establish that, as long as the batch size sequence is properly specified (depending on the stepsize sequence), the estimator achieves a convergence rate of order $O(\sqrt{d}n^{-1/8+\varepsilon})$ for any $\varepsilon>0$, where $d$ and $n$ denote the problem dimensionality and the number of iterations (or samples) used. Although the problem is nonsmooth and potentially non-monotone (nonconvex), our convergence rate matches the best-known rate for covariance estimation methods using only first-order information in smooth and strongly-convex settings. The consistency of this covariance estimator enables asymptotically valid statistical inference, including constructing confidence intervals and performing hypothesis testing.
Physics-Informed Neural Networks with Trust-Region Sequential Quadratic Programming
Sep 16, 2024Physics-Informed Neural Networks (PINNs) represent a significant advancement in Scientific Machine Learning (SciML), which integrate physical domain knowledge into an empirical loss function as soft constraints and apply existing machine learning methods to train the model. However, recent research has noted that PINNs may fail to learn relatively complex Partial Differential Equations (PDEs). This paper addresses the failure modes of PINNs by introducing a novel, hard-constrained deep learning method -- trust-region Sequential Quadratic Programming (trSQP-PINN). In contrast to directly training the penalized soft-constrained loss as in PINNs, our method performs a linear-quadratic approximation of the hard-constrained loss, while leveraging the soft-constrained loss to adaptively adjust the trust-region radius. We only trust our model approximations and make updates within the trust region, and such an updating manner can overcome the ill-conditioning issue of PINNs. We also address the computational bottleneck of second-order SQP methods by employing quasi-Newton updates for second-order information, and importantly, we introduce a simple pretraining step to further enhance training efficiency of our method. We demonstrate the effectiveness of trSQP-PINN through extensive experiments. Compared to existing hard-constrained methods for PINNs, such as penalty methods and augmented Lagrangian methods, trSQP-PINN significantly improves the accuracy of the learned PDE solutions, achieving up to 1-3 orders of magnitude lower errors. Additionally, our pretraining step is generally effective for other hard-constrained methods, and experiments have shown the robustness of our method against both problem-specific parameters and algorithm tuning parameters.
Constrained Optimization via Exact Augmented Lagrangian and Randomized Iterative Sketching
May 28, 2023



We consider solving equality-constrained nonlinear, nonconvex optimization problems. This class of problems appears widely in a variety of applications in machine learning and engineering, ranging from constrained deep neural networks, to optimal control, to PDE-constrained optimization. We develop an adaptive inexact Newton method for this problem class. In each iteration, we solve the Lagrangian Newton system inexactly via a randomized iterative sketching solver, and select a suitable stepsize by performing line search on an exact augmented Lagrangian merit function. The randomized solvers have advantages over deterministic linear system solvers by significantly reducing per-iteration flops complexity and storage cost, when equipped with suitable sketching matrices. Our method adaptively controls the accuracy of the randomized solver and the penalty parameters of the exact augmented Lagrangian, to ensure that the inexact Newton direction is a descent direction of the exact augmented Lagrangian. This allows us to establish a global almost sure convergence. We also show that a unit stepsize is admissible locally, so that our method exhibits a local linear convergence. Furthermore, we prove that the linear convergence can be strengthened to superlinear convergence if we gradually sharpen the adaptive accuracy condition on the randomized solver. We demonstrate the superior performance of our method on benchmark nonlinear problems in CUTEst test set, constrained logistic regression with data from LIBSVM, and a PDE-constrained problem.
* 25 pages, 4 figures