 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEDformer: Event-Synchronous Spiking Transformers for Irregular Telemetry Time Series Forecasting
Feb 03, 2026Telemetry streams from large-scale Internet-connected systems (e.g., IoT deployments and online platforms) naturally form an irregular multivariate time series (IMTS) whose accurate forecasting is operationally vital. A closer examination reveals a defining Sparsity-Event Duality (SED) property of IMTS, i.e., long stretches with sparse or no observations are punctuated by short, dense bursts where most semantic events (observations) occur. However, existing Graph- and Transformer-based forecasters ignore SED: pre-alignment to uniform grids with heavy padding violates sparsity by inflating sequences and forcing computation at non-informative steps, while relational recasting weakens event semantics by disrupting local temporal continuity. These limitations motivate a more faithful and natural modeling paradigm for IMTS that aligns with its SED property. We find that Spiking Neural Networks meet this requirement, as they communicate via sparse binary spikes and update in an event-driven manner, aligning naturally with the SED nature of IMTS. Therefore, we present SEDformer, an SED-enhanced Spiking Transformer for telemetry IMTS forecasting that couples: (1) a SED-based Spike Encoder converts raw observations into event synchronous spikes using an Event-Aligned LIF neuron, (2) an Event-Preserving Temporal Downsampling module compresses long gaps while retaining salient firings and (3) a stack of SED-based Spike Transformer blocks enable intra-series dependency modeling with a membrane-based linear attention driven by EA-LIF spiking features. Experiments on public telemetry IMTS datasets show that SEDformer attains state-of-the-art forecasting accuracy while reducing energy and memory usage, providing a natural and efficient path for modeling IMTS.
3DGS$^2$-TR: Scalable Second-Order Trust-Region Method for 3D Gaussian Splatting
Jan 30, 2026We propose 3DGS$^2$-TR,a second-order optimizer for accelerating the scene training problem in 3D Gaussian Splatting (3DGS). Unlike existing second-order approaches that rely on explicit or dense curvature representations, such as 3DGS-LM (Höllein et al., 2025) or 3DGS2 (Lan et al., 2025), our method approximates curvature using only the diagonal of the Hessian matrix, efficiently via Hutchinson's method. Our approach is fully matrix-free and has the same complexity as ADAM (Kingma, 2024), $O(n)$ in both computation and memory costs. To ensure stable optimization in the presence of strong nonlinearity in the 3DGS rasterization process, we introduce a parameter-wise trust-region technique based on the squared Hellinger distance, regularizing updates to Gaussian parameters. Under identical parameter initialization and without densification, 3DGS$^2$-TR is able to achieve better reconstruction quality on standard datasets, using 50% fewer training iterations compared to ADAM, while incurring less than 1GB of peak GPU memory overhead (17% more than ADAM and 85% less than 3DGS-LM), enabling scalability to very large scenes and potentially to distributed training settings.
TRSVR: An Adaptive Stochastic Trust-Region Method with Variance Reduction
Jan 21, 2026We propose a stochastic trust-region method for unconstrained nonconvex optimization that incorporates stochastic variance-reduced gradients (SVRG) to accelerate convergence. Unlike classical trust-region methods, the proposed algorithm relies solely on stochastic gradient information and does not require function value evaluations. The trust-region radius is adaptively adjusted based on a radius-control parameter and the stochastic gradient estimate. Under mild assumptions, we establish that the algorithm converges in expectation to a first-order stationary point. Moreover, the method achieves iteration and sample complexity bounds that match those of SVRG-based first-order methods, while allowing stochastic and potentially gradient-dependent second-order information. Extensive numerical experiments demonstrate that incorporating SVRG accelerates convergence, and that the use of trust-region methods and Hessian information further improves performance. We also highlight the impact of batch size and inner-loop length on efficiency, and show that the proposed method outperforms SGD and Adam on several machine learning tasks.
Task-Aware Retrieval Augmentation for Dynamic Recommendation
Nov 16, 2025Dynamic recommendation systems aim to provide personalized suggestions by modeling temporal user-item interactions across time-series behavioral data. Recent studies have leveraged pre-trained dynamic graph neural networks (GNNs) to learn user-item representations over temporal snapshot graphs. However, fine-tuning GNNs on these graphs often results in generalization issues due to temporal discrepancies between pre-training and fine-tuning stages, limiting the model's ability to capture evolving user preferences. To address this, we propose TarDGR, a task-aware retrieval-augmented framework designed to enhance generalization capability by incorporating task-aware model and retrieval-augmentation. Specifically, TarDGR introduces a Task-Aware Evaluation Mechanism to identify semantically relevant historical subgraphs, enabling the construction of task-specific datasets without manual labeling. It also presents a Graph Transformer-based Task-Aware Model that integrates semantic and structural encodings to assess subgraph relevance. During inference, TarDGR retrieves and fuses task-aware subgraphs with the query subgraph, enriching its representation and mitigating temporal generalization issues. Experiments on multiple large-scale dynamic graph datasets demonstrate that TarDGR consistently outperforms state-of-the-art methods, with extensive empirical evidence underscoring its superior accuracy and generalization capabilities.
STRAP: Spatio-Temporal Pattern Retrieval for Out-of-Distribution Generalization
May 26, 2025Spatio-Temporal Graph Neural Networks (STGNNs) have emerged as a powerful tool for modeling dynamic graph-structured data across diverse domains. However, they often fail to generalize in Spatio-Temporal Out-of-Distribution (STOOD) scenarios, where both temporal dynamics and spatial structures evolve beyond the training distribution. To address this problem, we propose an innovative Spatio-Temporal Retrieval-Augmented Pattern Learning framework,STRAP, which enhances model generalization by integrating retrieval-augmented learning into the STGNN continue learning pipeline. The core of STRAP is a compact and expressive pattern library that stores representative spatio-temporal patterns enriched with historical, structural, and semantic information, which is obtained and optimized during the training phase. During inference, STRAP retrieves relevant patterns from this library based on similarity to the current input and injects them into the model via a plug-and-play prompting mechanism. This not only strengthens spatio-temporal representations but also mitigates catastrophic forgetting. Moreover, STRAP introduces a knowledge-balancing objective to harmonize new information with retrieved knowledge. Extensive experiments across multiple real-world streaming graph datasets show that STRAP consistently outperforms state-of-the-art STGNN baselines on STOOD tasks, demonstrating its robustness, adaptability, and strong generalization capability without task-specific fine-tuning.
High Probability Complexity Bounds of Trust-Region Stochastic Sequential Quadratic Programming with Heavy-Tailed Noise
Mar 24, 2025In this paper, we consider nonlinear optimization problems with a stochastic objective and deterministic equality constraints. We propose a Trust-Region Stochastic Sequential Quadratic Programming (TR-SSQP) method and establish its high-probability iteration complexity bounds for identifying first- and second-order $\epsilon$-stationary points. In our algorithm, we assume that exact objective values, gradients, and Hessians are not directly accessible but can be estimated via zeroth-, first-, and second-order probabilistic oracles. Compared to existing complexity studies of SSQP methods that rely on a zeroth-order oracle with sub-exponential tail noise (i.e., light-tailed) and focus mostly on first-order stationarity, our analysis accommodates irreducible and heavy-tailed noise in the zeroth-order oracle and significantly extends the analysis to second-order stationarity. We show that under weaker noise conditions, our method achieves the same high-probability first-order iteration complexity bounds, while also exhibiting promising second-order iteration complexity bounds. Specifically, the method identifies a first-order $\epsilon$-stationary point in $\mathcal{O}(\epsilon^{-2})$ iterations and a second-order $\epsilon$-stationary point in $\mathcal{O}(\epsilon^{-3})$ iterations with high probability, provided that $\epsilon$ is lower bounded by a constant determined by the irreducible noise level in estimation. We validate our theoretical findings and evaluate the practical performance of our method on CUTEst benchmark test set.
Efficient Large-Scale Traffic Forecasting with Transformers: A Spatial Data Management Perspective
Dec 13, 2024Road traffic forecasting is crucial in real-world intelligent transportation scenarios like traffic dispatching and path planning in city management and personal traveling. Spatio-temporal graph neural networks (STGNNs) stand out as the mainstream solution in this task. Nevertheless, the quadratic complexity of remarkable dynamic spatial modeling-based STGNNs has become the bottleneck over large-scale traffic data. From the spatial data management perspective, we present a novel Transformer framework called PatchSTG to efficiently and dynamically model spatial dependencies for large-scale traffic forecasting with interpretability and fidelity. Specifically, we design a novel irregular spatial patching to reduce the number of points involved in the dynamic calculation of Transformer. The irregular spatial patching first utilizes the leaf K-dimensional tree (KDTree) to recursively partition irregularly distributed traffic points into leaf nodes with a small capacity, and then merges leaf nodes belonging to the same subtree into occupancy-equaled and non-overlapped patches through padding and backtracking. Based on the patched data, depth and breadth attention are used interchangeably in the encoder to dynamically learn local and global spatial knowledge from points in a patch and points with the same index of patches. Experimental results on four real world large-scale traffic datasets show that our PatchSTG achieves train speed and memory utilization improvements up to $10\times$ and $4\times$ with the state-of-the-art performance.
RAGraph: A General Retrieval-Augmented Graph Learning Framework
Oct 31, 2024



Graph Neural Networks (GNNs) have become essential in interpreting relational data across various domains, yet, they often struggle to generalize to unseen graph data that differs markedly from training instances. In this paper, we introduce a novel framework called General Retrieval-Augmented Graph Learning (RAGraph), which brings external graph data into the general graph foundation model to improve model generalization on unseen scenarios. On the top of our framework is a toy graph vector library that we established, which captures key attributes, such as features and task-specific label information. During inference, the RAGraph adeptly retrieves similar toy graphs based on key similarities in downstream tasks, integrating the retrieved data to enrich the learning context via the message-passing prompting mechanism. Our extensive experimental evaluations demonstrate that RAGraph significantly outperforms state-of-the-art graph learning methods in multiple tasks such as node classification, link prediction, and graph classification across both dynamic and static datasets. Furthermore, extensive testing confirms that RAGraph consistently maintains high performance without the need for task-specific fine-tuning, highlighting its adaptability, robustness, and broad applicability.
TC-RAG:Turing-Complete RAG's Case study on Medical LLM Systems
Aug 17, 2024



In the pursuit of enhancing domain-specific Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) emerges as a promising solution to mitigate issues such as hallucinations, outdated knowledge, and limited expertise in highly specialized queries. However, existing approaches to RAG fall short by neglecting system state variables, which are crucial for ensuring adaptive control, retrieval halting, and system convergence. In this paper, we introduce the TC-RAG through rigorous proof, a novel framework that addresses these challenges by incorporating a Turing Complete System to manage state variables, thereby enabling more efficient and accurate knowledge retrieval. By leveraging a memory stack system with adaptive retrieval, reasoning, and planning capabilities, TC-RAG not only ensures the controlled halting of retrieval processes but also mitigates the accumulation of erroneous knowledge via Push and Pop actions. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of TC-RAG over existing methods in accuracy by over 7.20\%. Our dataset and code have been available at https://https://github.com/Artessay/SAMA.git.
ContiFormer: Continuous-Time Transformer for Irregular Time Series Modeling
Feb 16, 2024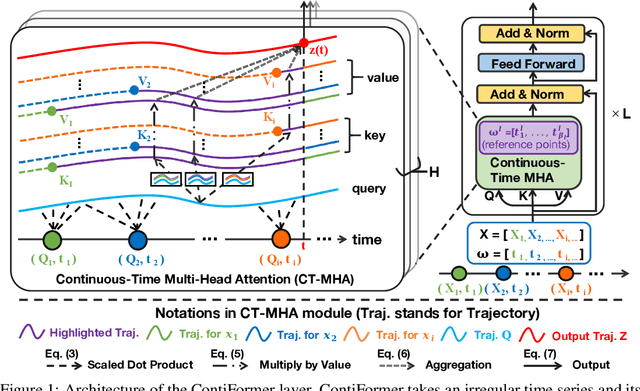
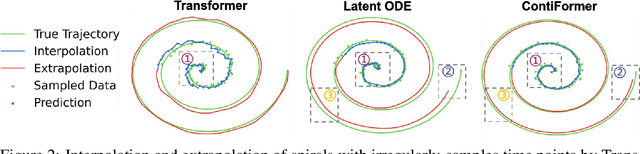
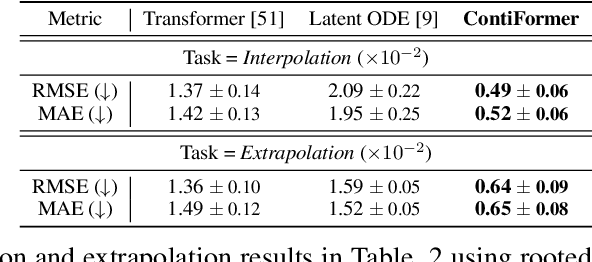
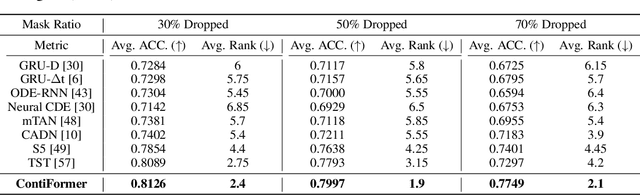
Modeling continuous-time dynamics on irregular time series is critical to account for data evolution and correlations that occur continuously. Traditional methods including recurrent neural networks or Transformer models leverage inductive bias via powerful neural architectures to capture complex patterns. However, due to their discrete characteristic, they have limitations in generalizing to continuous-time data paradigms. Though neural ordinary differential equations (Neural ODEs) and their variants have shown promising results in dealing with irregular time series, they often fail to capture the intricate correlations within these sequences. It is challenging yet demanding to concurrently model the relationship between input data points and capture the dynamic changes of the continuous-time system. To tackle this problem, we propose ContiFormer that extends the relation modeling of vanilla Transformer to the continuous-time domain, which explicitly incorporates the modeling abilities of continuous dynamics of Neural ODEs with the attention mechanism of Transformers. We mathematically characterize the expressive power of ContiFormer and illustrate that, by curated designs of function hypothesis, many Transformer variants specialized in irregular time series modeling can be covered as a special case of ContiFormer. A wide range of experiments on both synthetic and real-world datasets have illustrated the superior modeling capacities and prediction performance of ContiFormer on irregular time series data. The project link is https://seqml.github.io/contiformer/.