 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopTool: Closing the Data-Training Loop for Robust LLM Tool Calls
Nov 18, 2025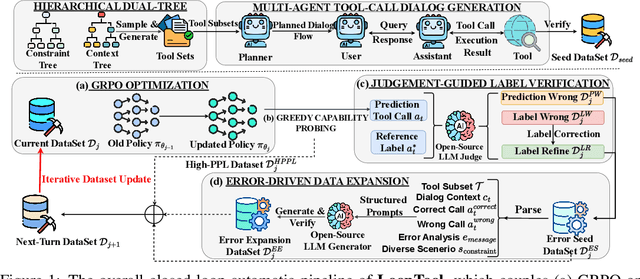
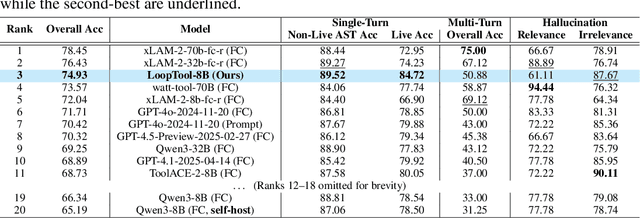
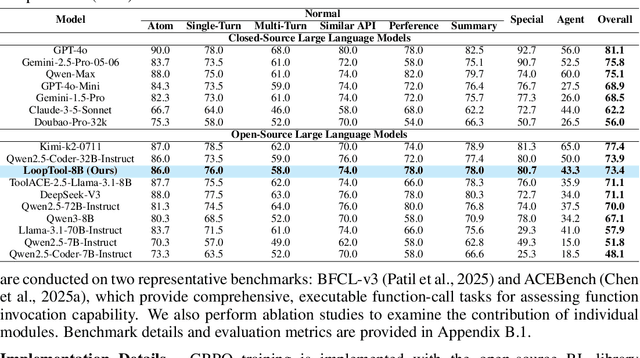
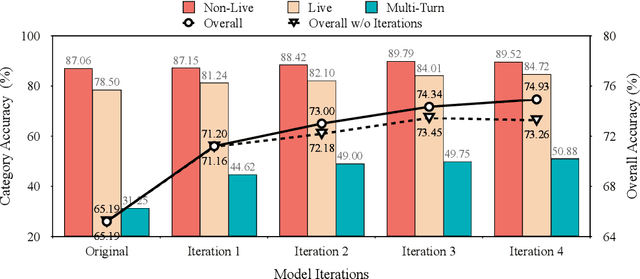
Augmenting Large Language Models (LLMs) with external tools enables them to execute complex, multi-step tasks. However, tool learning is hampered by the static synthetic data pipelines where data generation and model training are executed as two separate, non-interactive processes. This approach fails to adaptively focus on a model's specific weaknesses and allows noisy labels to persist, degrading training efficiency. We introduce LoopTool, a fully automated, model-aware data evolution framework that closes this loop by tightly integrating data synthesis and model training. LoopTool iteratively refines both the data and the model through three synergistic modules: (1) Greedy Capability Probing (GCP) diagnoses the model's mastered and failed capabilities; (2) Judgement-Guided Label Verification (JGLV) uses an open-source judge model to find and correct annotation errors, progressively purifying the dataset; and (3) Error-Driven Data Expansion (EDDE) generates new, challenging samples based on identified failures. This closed-loop process operates within a cost-effective, open-source ecosystem, eliminating dependence on expensive closed-source APIs. Experiments show that our 8B model trained with LoopTool significantly surpasses its 32B data generator and achieves new state-of-the-art results on the BFCL-v3 and ACEBench benchmarks for its scale. Our work demonstrates that closed-loop, self-refining data pipelines can dramatically enhance the tool-use capabilities of LLMs.
Fints: Efficient Inference-Time Personalization for LLMs with Fine-Grained Instance-Tailored Steering
Oct 31, 2025The rapid evolution of large language models (LLMs) has intensified the demand for effective personalization techniques that can adapt model behavior to individual user preferences. Despite the non-parametric methods utilizing the in-context learning ability of LLMs, recent parametric adaptation methods, including personalized parameter-efficient fine-tuning and reward modeling emerge. However, these methods face limitations in handling dynamic user patterns and high data sparsity scenarios, due to low adaptability and data efficiency. To address these challenges, we propose a fine-grained and instance-tailored steering framework that dynamically generates sample-level interference vectors from user data and injects them into the model's forward pass for personalized adaptation. Our approach introduces two key technical innovations: a fine-grained steering component that captures nuanced signals by hooking activations from attention and MLP layers, and an input-aware aggregation module that synthesizes these signals into contextually relevant enhancements. The method demonstrates high flexibility and data efficiency, excelling in fast-changing distribution and high data sparsity scenarios. In addition, the proposed method is orthogonal to existing methods and operates as a plug-in component compatible with different personalization techniques. Extensive experiments across diverse scenarios--including short-to-long text generation, and web function calling--validate the effectiveness and compatibility of our approach. Results show that our method significantly enhances personalization performance in fast-shifting environments while maintaining robustness across varying interaction modes and context lengths. Implementation is available at https://github.com/KounianhuaDu/Fints.
Synthesize, Retrieve, and Propagate: A Unified Predictive Modeling Framework for Relational Databases
Aug 10, 2025Relational databases (RDBs) have become the industry standard for storing massive and heterogeneous data. However, despite the widespread use of RDBs across various fields, the inherent structure of relational databases hinders their ability to benefit from flourishing deep learning methods. Previous research has primarily focused on exploiting the unary dependency among multiple tables in a relational database using the primary key - foreign key relationships, either joining multiple tables into a single table or constructing a graph among them, which leaves the implicit composite relations among different tables and a substantial potential of improvement for predictive modeling unexplored. In this paper, we propose SRP, a unified predictive modeling framework that synthesizes features using the unary dependency, retrieves related information to capture the composite dependency, and propagates messages across a constructed graph to learn adjacent patterns for prediction on relation databases. By introducing a new retrieval mechanism into RDB, SRP is designed to fully capture both the unary and the composite dependencies within a relational database, thereby enhancing the receptive field of tabular data prediction. In addition, we conduct a comprehensive analysis on the components of SRP, offering a nuanced understanding of model behaviors and practical guidelines for future applications. Extensive experiments on five real-world datasets demonstrate the effectiveness of SRP and its potential applicability in industrial scenarios. The code is released at https://github.com/NingLi670/SRP.
NL-Debugging: Exploiting Natural Language as an Intermediate Representation for Code Debugging
May 21, 2025Debugging is a critical aspect of LLM's coding ability. Early debugging efforts primarily focused on code-level analysis, which often falls short when addressing complex programming errors that require a deeper understanding of algorithmic logic. Recent advancements in large language models (LLMs) have shifted attention toward leveraging natural language reasoning to enhance code-related tasks. However, two fundamental questions remain unanswered: What type of natural language format is most effective for debugging tasks? And what specific benefits does natural language reasoning bring to the debugging process? In this paper, we introduce NL-DEBUGGING, a novel framework that employs natural language as an intermediate representation to improve code debugging. By debugging at a natural language level, we demonstrate that NL-DEBUGGING outperforms traditional debugging methods and enables a broader modification space through direct refinement guided by execution feedback. Our findings highlight the potential of natural language reasoning to advance automated code debugging and address complex programming challenges.
Retrieval-Augmented Process Reward Model for Generalizable Mathematical Reasoning
Feb 20, 2025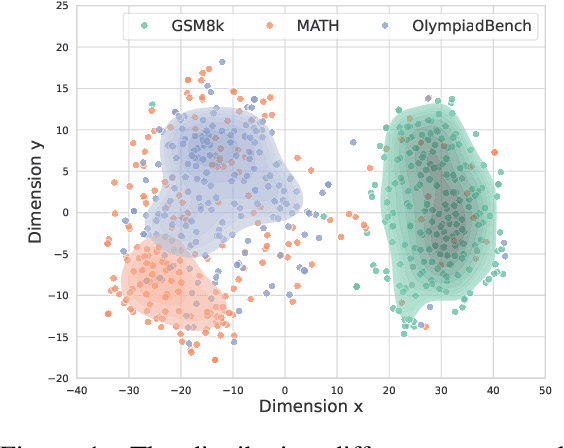
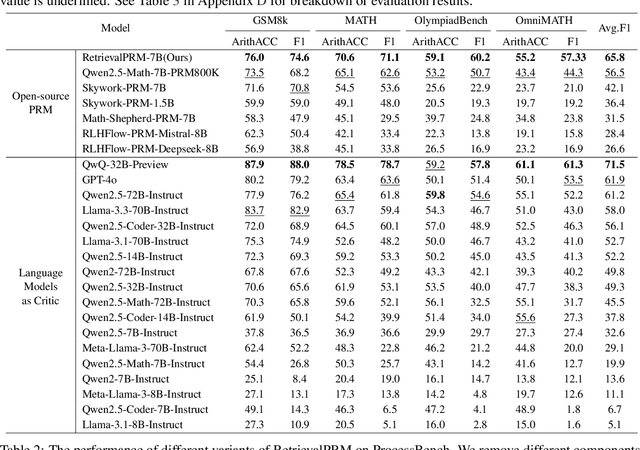
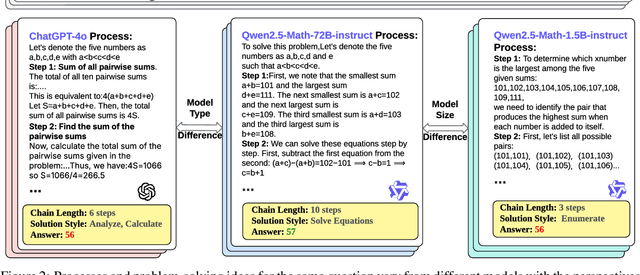
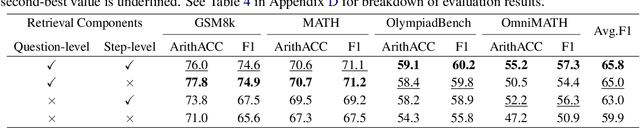
While large language models (LLMs) have significantly advanced mathematical reasoning, Process Reward Models (PRMs) have been developed to evaluate the logical validity of reasoning steps. However, PRMs still struggle with out-of-distribution (OOD) challenges. This paper identifies key OOD issues, including step OOD, caused by differences in reasoning patterns across model types and sizes, and question OOD, which arises from dataset shifts between training data and real-world problems. To address these issues, we introduce Retrieval-Augmented Process Reward Model (RetrievalPRM), a novel framework designed to tackle these OOD issues. By utilizing a two-stage retrieval-enhanced mechanism, RetrievalPRM retrieves semantically similar questions and steps as a warmup, enhancing PRM's ability to evaluate target steps and improving generalization and reasoning consistency across different models and problem types. Our extensive experiments demonstrate that RetrievalPRM outperforms existing baselines across multiple real-world datasets. Our open-source contributions include a retrieval-enhanced dataset, a tuning framework for PRM training, and the RetrievalPRM model, establishing a new standard for PRM performance.
Boost, Disentangle, and Customize: A Robust System2-to-System1 Pipeline for Code Generation
Feb 18, 2025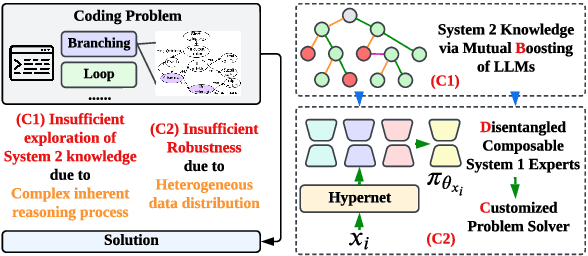
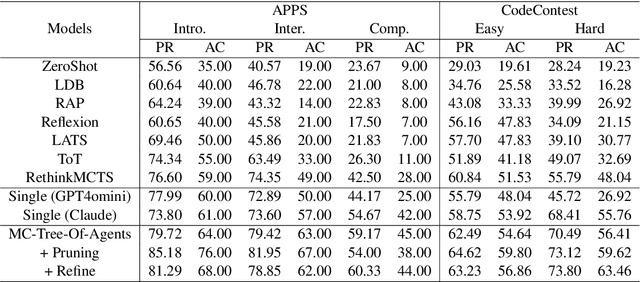
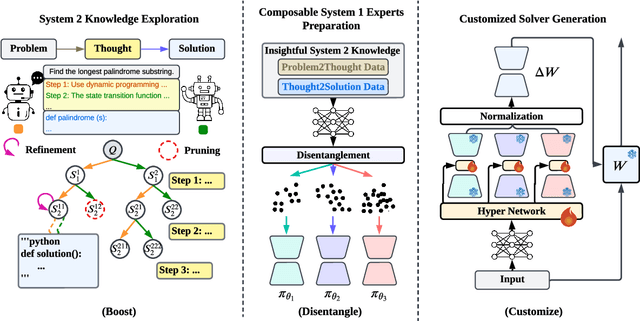
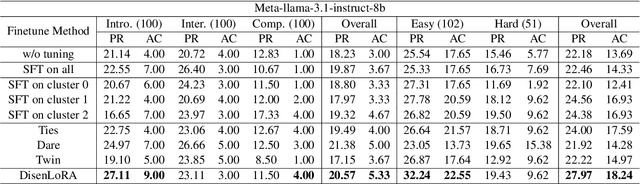
Large language models (LLMs) have demonstrated remarkable capabilities in various domains, particularly in system 1 tasks, yet the intricacies of their problem-solving mechanisms in system 2 tasks are not sufficiently explored. Recent research on System2-to-System1 methods surge, exploring the System 2 reasoning knowledge via inference-time computation and compressing the explored knowledge into System 1 process. In this paper, we focus on code generation, which is a representative System 2 task, and identify two primary challenges: (1) the complex hidden reasoning processes and (2) the heterogeneous data distributions that complicate the exploration and training of robust LLM solvers. To tackle these issues, we propose a novel BDC framework that explores insightful System 2 knowledge of LLMs using a MC-Tree-Of-Agents algorithm with mutual \textbf{B}oosting, \textbf{D}isentangles the heterogeneous training data for composable LoRA-experts, and obtain \textbf{C}ustomized problem solver for each data instance with an input-aware hypernetwork to weight over the LoRA-experts, offering effectiveness, flexibility, and robustness. This framework leverages multiple LLMs through mutual verification and boosting, integrated into a Monte-Carlo Tree Search process enhanced by reflection-based pruning and refinement. Additionally, we introduce the DisenLora algorithm, which clusters heterogeneous data to fine-tune LLMs into composable Lora experts, enabling the adaptive generation of customized problem solvers through an input-aware hypernetwork. This work lays the groundwork for advancing LLM capabilities in complex reasoning tasks, offering a novel System2-to-System1 solution.
Agentic Information Retrieval
Oct 13, 2024



What will information entry look like in the next generation of digital products? Since the 1970s, user access to relevant information has relied on domain-specific architectures of information retrieval (IR). Over the past two decades, the advent of modern IR systems, including web search engines and personalized recommender systems, has greatly improved the efficiency of retrieving relevant information from vast data corpora. However, the core paradigm of these IR systems remains largely unchanged, relying on filtering a predefined set of candidate items. Since 2022, breakthroughs in large language models (LLMs) have begun transforming how information is accessed, establishing a new technical paradigm. In this position paper, we introduce Agentic Information Retrieval (Agentic IR), a novel IR paradigm shaped by the capabilities of LLM agents. Agentic IR expands the scope of accessible tasks and leverages a suite of new techniques to redefine information retrieval. We discuss three types of cutting-edge applications of agentic IR and the challenges faced. We propose that agentic IR holds promise for generating innovative applications, potentially becoming a central information entry point in future digital ecosystems.
RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation
Sep 15, 2024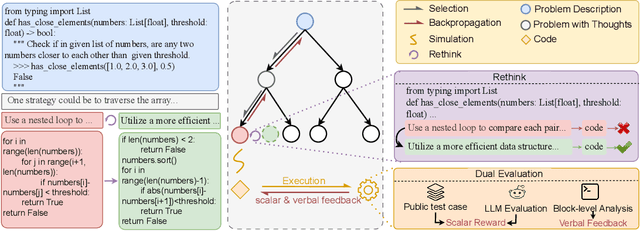

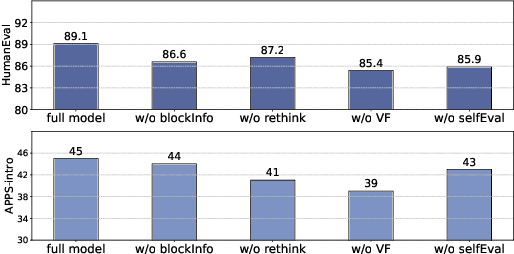

LLM agents enhanced by tree search algorithms have yielded notable performances in code generation. However, current search algorithms in this domain suffer from low search quality due to several reasons: 1) Ineffective design of the search space for the high-reasoning demands of code generation tasks, 2) Inadequate integration of code feedback with the search algorithm, and 3) Poor handling of negative feedback during the search, leading to reduced search efficiency and quality. To address these challenges, we propose to search for the reasoning process of the code and use the detailed feedback of code execution to refine erroneous thoughts during the search. In this paper, we introduce RethinkMCTS, which employs the Monte Carlo Tree Search (MCTS) algorithm to conduct thought-level searches before generating code, thereby exploring a wider range of strategies. More importantly, we construct verbal feedback from fine-grained code execution feedback to refine erroneous thoughts during the search. This ensures that the search progresses along the correct reasoning paths, thus improving the overall search quality of the tree by leveraging execution feedback. Through extensive experiments, we demonstrate that RethinkMCTS outperforms previous search-based and feedback-based code generation baselines. On the HumanEval dataset, it improves the pass@1 of GPT-3.5-turbo from 70.12 to 89.02 and GPT-4o-mini from 87.20 to 94.51. It effectively conducts more thorough exploration through thought-level searches and enhances the search quality of the entire tree by incorporating rethink operation.
SINKT: A Structure-Aware Inductive Knowledge Tracing Model with Large Language Model
Jul 01, 2024



Knowledge Tracing (KT) aims to determine whether students will respond correctly to the next question, which is a crucial task in intelligent tutoring systems (ITS). In educational KT scenarios, transductive ID-based methods often face severe data sparsity and cold start problems, where interactions between individual students and questions are sparse, and new questions and concepts consistently arrive in the database. In addition, existing KT models only implicitly consider the correlation between concepts and questions, lacking direct modeling of the more complex relationships in the heterogeneous graph of concepts and questions. In this paper, we propose a Structure-aware Inductive Knowledge Tracing model with large language model (dubbed SINKT), which, for the first time, introduces large language models (LLMs) and realizes inductive knowledge tracing. Firstly, SINKT utilizes LLMs to introduce structural relationships between concepts and constructs a heterogeneous graph for concepts and questions. Secondly, by encoding concepts and questions with LLMs, SINKT incorporates semantic information to aid prediction. Finally, SINKT predicts the student's response to the target question by interacting with the student's knowledge state and the question representation. Experiments on four real-world datasets demonstrate that SINKT achieves state-of-the-art performance among 12 existing transductive KT models. Additionally, we explore the performance of SINKT on the inductive KT task and provide insights into various modules.
ELCoRec: Enhance Language Understanding with Co-Propagation of Numerical and Categorical Features for Recommendation
Jun 27, 2024



Large language models have been flourishing in the natural language processing (NLP) domain, and their potential for recommendation has been paid much attention to. Despite the intelligence shown by the recommendation-oriented finetuned models, LLMs struggle to fully understand the user behavior patterns due to their innate weakness in interpreting numerical features and the overhead for long context, where the temporal relations among user behaviors, subtle quantitative signals among different ratings, and various side features of items are not well explored. Existing works only fine-tune a sole LLM on given text data without introducing that important information to it, leaving these problems unsolved. In this paper, we propose ELCoRec to Enhance Language understanding with CoPropagation of numerical and categorical features for Recommendation. Concretely, we propose to inject the preference understanding capability into LLM via a GAT expert model where the user preference is better encoded by parallelly propagating the temporal relations, and rating signals as well as various side information of historical items. The parallel propagation mechanism could stabilize heterogeneous features and offer an informative user preference encoding, which is then injected into the language models via soft prompting at the cost of a single token embedding. To further obtain the user's recent interests, we proposed a novel Recent interaction Augmented Prompt (RAP) template. Experiment results over three datasets against strong baselines validate the effectiveness of ELCoRec. The code is available at https://anonymous.4open.science/r/CIKM_Code_Repo-E6F5/README.md.