 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWIST: Web-Grounded Iterative Self-Play Tree for Domain-Targeted Reasoning Improvement
Mar 22, 2026Recent progress in reinforcement learning with verifiable rewards (RLVR) offers a practical path to self-improvement of language models, but existing methods face a key trade-off: endogenous self-play can drift over iterations, while corpus-grounded approaches rely on curated data environments. We present \textbf{WIST}, a \textbf{W}eb-grounded \textbf{I}terative \textbf{S}elf-play \textbf{T}ree framework for domain-targeted reasoning improvement that learns directly from the open web without requiring any pre-arranged domain corpus. WIST incrementally expands a domain tree for exploration, and retrieves and cleans path-consistent web corpus to construct a controllable training environment. It then performs Challenger--Solver self-play with verifiable rewards, and feeds learnability signals back to update node posteriors and guide subsequent exploration through an adaptive curriculum. Across four backbones, WIST consistently improves over the base models and typically outperforms both purely endogenous self-evolution and corpus-grounded self-play baselines, with the Overall gains reaching \textbf{+9.8} (\textit{Qwen3-4B-Base}) and \textbf{+9.7} (\textit{OctoThinker-8B}). WIST is also domain-steerable, improving \textit{Qwen3-8B-Base} by \textbf{+14.79} in medicine and \textit{Qwen3-4B-Base} by \textbf{+5.28} on PhyBench. Ablations further confirm the importance of WIST's key components for stable open-web learning. Our Code is available at https://github.com/lfy-123/WIST.
Fints: Efficient Inference-Time Personalization for LLMs with Fine-Grained Instance-Tailored Steering
Oct 31, 2025The rapid evolution of large language models (LLMs) has intensified the demand for effective personalization techniques that can adapt model behavior to individual user preferences. Despite the non-parametric methods utilizing the in-context learning ability of LLMs, recent parametric adaptation methods, including personalized parameter-efficient fine-tuning and reward modeling emerge. However, these methods face limitations in handling dynamic user patterns and high data sparsity scenarios, due to low adaptability and data efficiency. To address these challenges, we propose a fine-grained and instance-tailored steering framework that dynamically generates sample-level interference vectors from user data and injects them into the model's forward pass for personalized adaptation. Our approach introduces two key technical innovations: a fine-grained steering component that captures nuanced signals by hooking activations from attention and MLP layers, and an input-aware aggregation module that synthesizes these signals into contextually relevant enhancements. The method demonstrates high flexibility and data efficiency, excelling in fast-changing distribution and high data sparsity scenarios. In addition, the proposed method is orthogonal to existing methods and operates as a plug-in component compatible with different personalization techniques. Extensive experiments across diverse scenarios--including short-to-long text generation, and web function calling--validate the effectiveness and compatibility of our approach. Results show that our method significantly enhances personalization performance in fast-shifting environments while maintaining robustness across varying interaction modes and context lengths. Implementation is available at https://github.com/KounianhuaDu/Fints.
Graph Counselor: Adaptive Graph Exploration via Multi-Agent Synergy to Enhance LLM Reasoning
Jun 04, 2025Graph Retrieval Augmented Generation (GraphRAG) effectively enhances external knowledge integration capabilities by explicitly modeling knowledge relationships, thereby improving the factual accuracy and generation quality of Large Language Models (LLMs) in specialized domains. However, existing methods suffer from two inherent limitations: 1) Inefficient Information Aggregation: They rely on a single agent and fixed iterative patterns, making it difficult to adaptively capture multi-level textual, structural, and degree information within graph data. 2) Rigid Reasoning Mechanism: They employ preset reasoning schemes, which cannot dynamically adjust reasoning depth nor achieve precise semantic correction. To overcome these limitations, we propose Graph Counselor, an GraphRAG method based on multi-agent collaboration. This method uses the Adaptive Graph Information Extraction Module (AGIEM), where Planning, Thought, and Execution Agents work together to precisely model complex graph structures and dynamically adjust information extraction strategies, addressing the challenges of multi-level dependency modeling and adaptive reasoning depth. Additionally, the Self-Reflection with Multiple Perspectives (SR) module improves the accuracy and semantic consistency of reasoning results through self-reflection and backward reasoning mechanisms. Experiments demonstrate that Graph Counselor outperforms existing methods in multiple graph reasoning tasks, exhibiting higher reasoning accuracy and generalization ability. Our code is available at https://github.com/gjq100/Graph-Counselor.git.
Boost, Disentangle, and Customize: A Robust System2-to-System1 Pipeline for Code Generation
Feb 18, 2025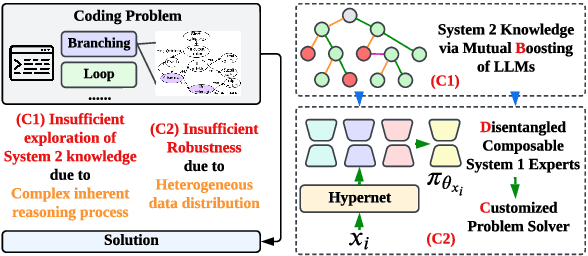
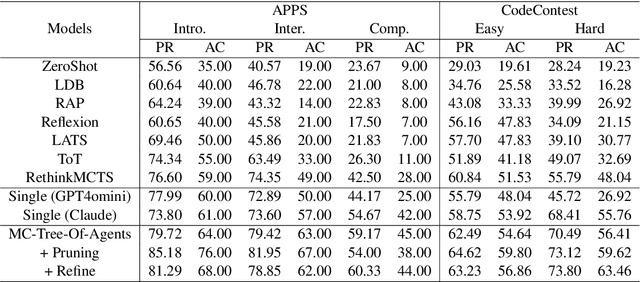
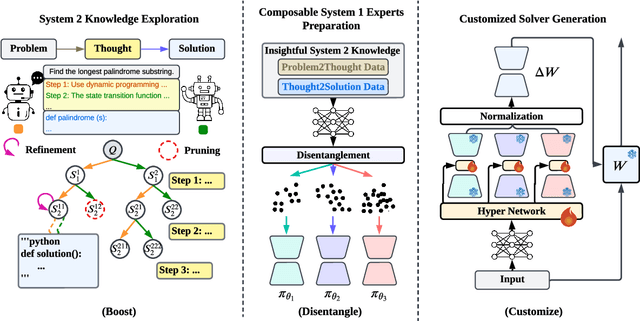
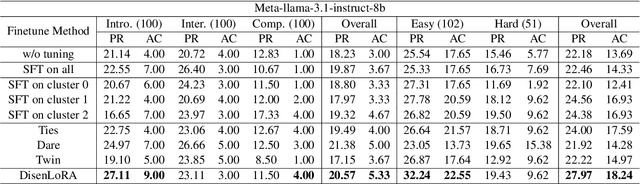
Large language models (LLMs) have demonstrated remarkable capabilities in various domains, particularly in system 1 tasks, yet the intricacies of their problem-solving mechanisms in system 2 tasks are not sufficiently explored. Recent research on System2-to-System1 methods surge, exploring the System 2 reasoning knowledge via inference-time computation and compressing the explored knowledge into System 1 process. In this paper, we focus on code generation, which is a representative System 2 task, and identify two primary challenges: (1) the complex hidden reasoning processes and (2) the heterogeneous data distributions that complicate the exploration and training of robust LLM solvers. To tackle these issues, we propose a novel BDC framework that explores insightful System 2 knowledge of LLMs using a MC-Tree-Of-Agents algorithm with mutual \textbf{B}oosting, \textbf{D}isentangles the heterogeneous training data for composable LoRA-experts, and obtain \textbf{C}ustomized problem solver for each data instance with an input-aware hypernetwork to weight over the LoRA-experts, offering effectiveness, flexibility, and robustness. This framework leverages multiple LLMs through mutual verification and boosting, integrated into a Monte-Carlo Tree Search process enhanced by reflection-based pruning and refinement. Additionally, we introduce the DisenLora algorithm, which clusters heterogeneous data to fine-tune LLMs into composable Lora experts, enabling the adaptive generation of customized problem solvers through an input-aware hypernetwork. This work lays the groundwork for advancing LLM capabilities in complex reasoning tasks, offering a novel System2-to-System1 solution.
Enhancing Adversarial Transferability via Information Bottleneck Constraints
Jun 08, 2024



From the perspective of information bottleneck (IB) theory, we propose a novel framework for performing black-box transferable adversarial attacks named IBTA, which leverages advancements in invariant features. Intuitively, diminishing the reliance of adversarial perturbations on the original data, under equivalent attack performance constraints, encourages a greater reliance on invariant features that contributes most to classification, thereby enhancing the transferability of adversarial attacks. Building on this motivation, we redefine the optimization of transferable attacks using a novel theoretical framework that centers around IB. Specifically, to overcome the challenge of unoptimizable mutual information, we propose a simple and efficient mutual information lower bound (MILB) for approximating computation. Moreover, to quantitatively evaluate mutual information, we utilize the Mutual Information Neural Estimator (MINE) to perform a thorough analysis. Our experiments on the ImageNet dataset well demonstrate the efficiency and scalability of IBTA and derived MILB. Our code is available at https://github.com/Biqing-Qi/Enhancing-Adversarial-Transferability-via-Information-Bottleneck-Constraints.
SMR: State Memory Replay for Long Sequence Modeling
May 27, 2024Despite the promising performance of state space models (SSMs) in long sequence modeling, limitations still exist. Advanced SSMs like S5 and S6 (Mamba) in addressing non-uniform sampling, their recursive structures impede efficient SSM computation via convolution. To overcome compatibility limitations in parallel convolutional computation, this paper proposes a novel non-recursive non-uniform sample processing strategy. Theoretical analysis of SSMs through the lens of Event-Triggered Control (ETC) theory reveals the Non-Stable State (NSS) problem, where deviations from sampling point requirements lead to error transmission and accumulation, causing the divergence of the SSM's hidden state. Our analysis further reveals that adjustments of input sequences with early memories can mitigate the NSS problem, achieving Sampling Step Adaptation (SSA). Building on this insight, we introduce a simple yet effective plug-and-play mechanism, State Memory Replay (SMR), which utilizes learnable memories to adjust the current state with multi-step information for generalization at sampling points different from those in the training data. This enables SSMs to stably model varying sampling points. Experiments on long-range modeling tasks in autoregressive language modeling and Long Range Arena demonstrate the general effectiveness of the SMR mechanism for a series of SSM models.
Contrastive Augmented Graph2Graph Memory Interaction for Few Shot Continual Learning
Mar 07, 2024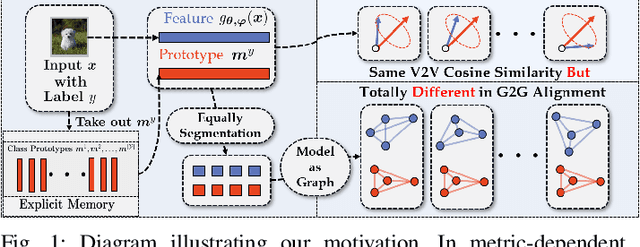
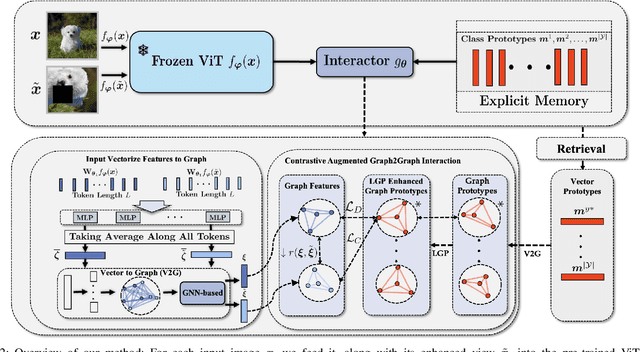
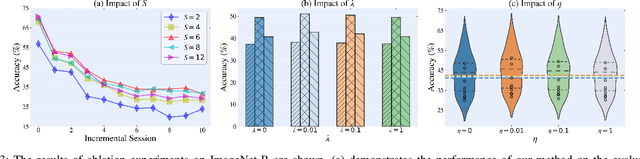
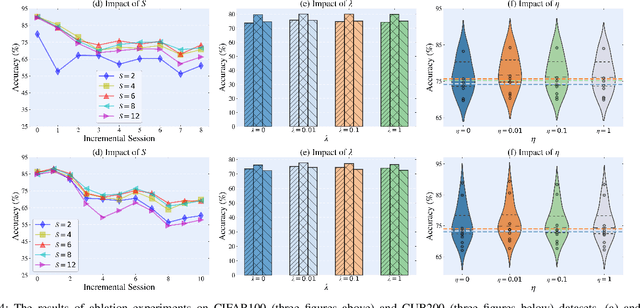
Few-Shot Class-Incremental Learning (FSCIL) has gained considerable attention in recent years for its pivotal role in addressing continuously arriving classes. However, it encounters additional challenges. The scarcity of samples in new sessions intensifies overfitting, causing incompatibility between the output features of new and old classes, thereby escalating catastrophic forgetting. A prevalent strategy involves mitigating catastrophic forgetting through the Explicit Memory (EM), which comprise of class prototypes. However, current EM-based methods retrieves memory globally by performing Vector-to-Vector (V2V) interaction between features corresponding to the input and prototypes stored in EM, neglecting the geometric structure of local features. This hinders the accurate modeling of their positional relationships. To incorporate information of local geometric structure, we extend the V2V interaction to Graph-to-Graph (G2G) interaction. For enhancing local structures for better G2G alignment and the prevention of local feature collapse, we propose the Local Graph Preservation (LGP) mechanism. Additionally, to address sample scarcity in classes from new sessions, the Contrast-Augmented G2G (CAG2G) is introduced to promote the aggregation of same class features thus helps few-shot learning. Extensive comparisons on CIFAR100, CUB200, and the challenging ImageNet-R dataset demonstrate the superiority of our method over existing methods.
Interactive Continual Learning: Fast and Slow Thinking
Mar 05, 2024Advanced life forms, sustained by the synergistic interaction of neural cognitive mechanisms, continually acquire and transfer knowledge throughout their lifespan. In contrast, contemporary machine learning paradigms exhibit limitations in emulating the facets of continual learning (CL). Nonetheless, the emergence of large language models (LLMs) presents promising avenues for realizing CL via interactions with these models. Drawing on Complementary Learning System theory, this paper presents a novel Interactive Continual Learning (ICL) framework, enabled by collaborative interactions among models of various sizes. Specifically, we assign the ViT model as System1 and multimodal LLM as System2. To enable the memory module to deduce tasks from class information and enhance Set2Set retrieval, we propose the Class-Knowledge-Task Multi-Head Attention (CKT-MHA). Additionally, to improve memory retrieval in System1 through enhanced geometric representation, we introduce the CL-vMF mechanism, based on the von Mises-Fisher (vMF) distribution. Meanwhile, we introduce the von Mises-Fisher Outlier Detection and Interaction (vMF-ODI) strategy to identify hard examples, thus enhancing collaboration between System1 and System2 for complex reasoning realization. Comprehensive evaluation of our proposed ICL demonstrates significant resistance to forgetting and superior performance relative to existing methods.
Investigating Deep Watermark Security: An Adversarial Transferability Perspective
Feb 26, 2024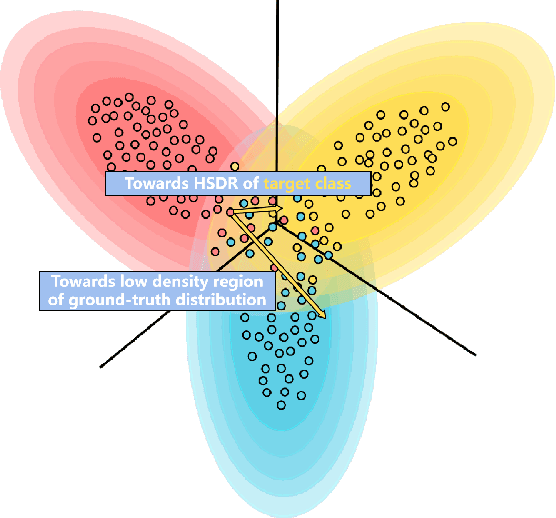
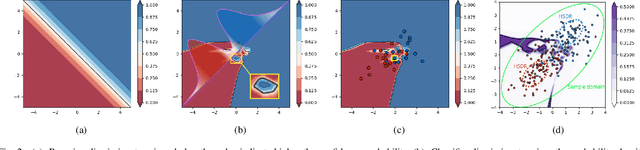

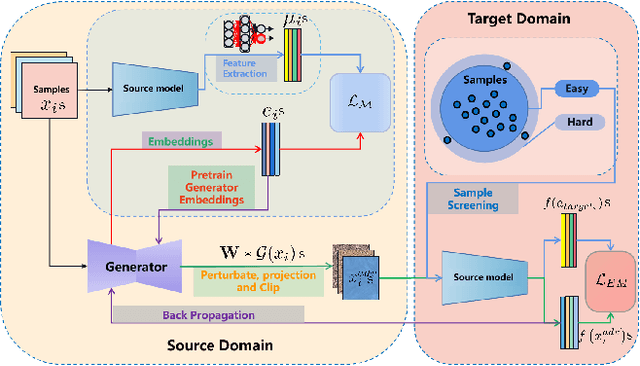
The rise of generative neural networks has triggered an increased demand for intellectual property (IP) protection in generated content. Deep watermarking techniques, recognized for their flexibility in IP protection, have garnered significant attention. However, the surge in adversarial transferable attacks poses unprecedented challenges to the security of deep watermarking techniques-an area currently lacking systematic investigation. This study fills this gap by introducing two effective transferable attackers to assess the vulnerability of deep watermarks against erasure and tampering risks. Specifically, we initially define the concept of local sample density, utilizing it to deduce theorems on the consistency of model outputs. Upon discovering that perturbing samples towards high sample density regions (HSDR) of the target class enhances targeted adversarial transferability, we propose the Easy Sample Selection (ESS) mechanism and the Easy Sample Matching Attack (ESMA) method. Additionally, we propose the Bottleneck Enhanced Mixup (BEM) that integrates information bottleneck theory to reduce the generator's dependence on irrelevant noise. Experiments show a significant enhancement in the success rate of targeted transfer attacks for both ESMA and BEM-ESMA methods. We further conduct a comprehensive evaluation using ESMA and BEM-ESMA as measurements, considering model architecture and watermark encoding length, and achieve some impressive findings.