 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL-Debugging: Exploiting Natural Language as an Intermediate Representation for Code Debugging
May 21, 2025Debugging is a critical aspect of LLM's coding ability. Early debugging efforts primarily focused on code-level analysis, which often falls short when addressing complex programming errors that require a deeper understanding of algorithmic logic. Recent advancements in large language models (LLMs) have shifted attention toward leveraging natural language reasoning to enhance code-related tasks. However, two fundamental questions remain unanswered: What type of natural language format is most effective for debugging tasks? And what specific benefits does natural language reasoning bring to the debugging process? In this paper, we introduce NL-DEBUGGING, a novel framework that employs natural language as an intermediate representation to improve code debugging. By debugging at a natural language level, we demonstrate that NL-DEBUGGING outperforms traditional debugging methods and enables a broader modification space through direct refinement guided by execution feedback. Our findings highlight the potential of natural language reasoning to advance automated code debugging and address complex programming challenges.
Boost, Disentangle, and Customize: A Robust System2-to-System1 Pipeline for Code Generation
Feb 18, 2025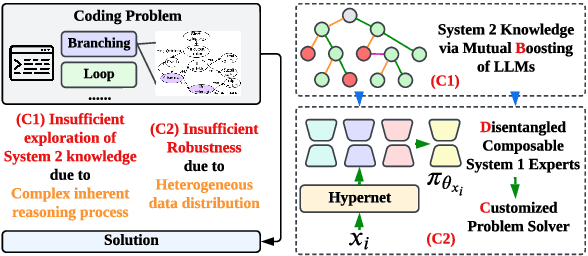
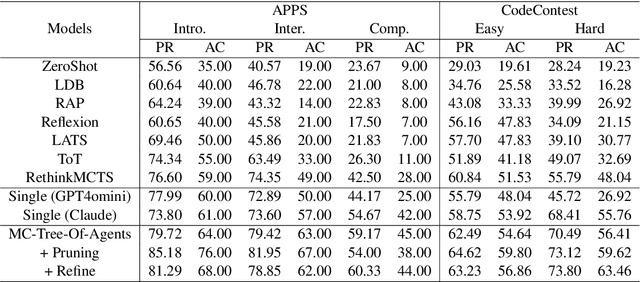
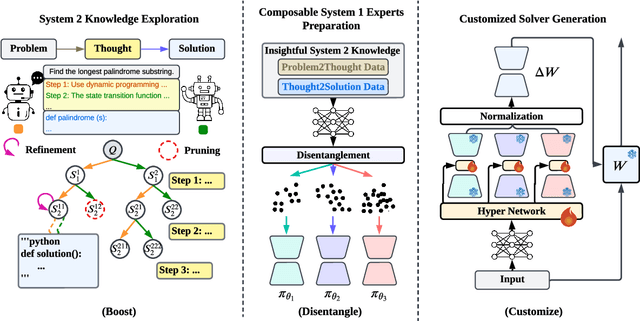
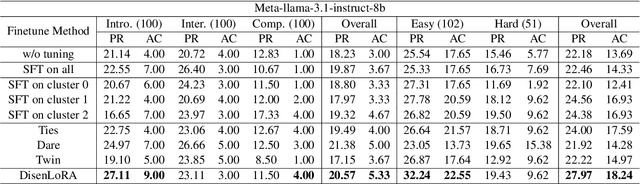
Large language models (LLMs) have demonstrated remarkable capabilities in various domains, particularly in system 1 tasks, yet the intricacies of their problem-solving mechanisms in system 2 tasks are not sufficiently explored. Recent research on System2-to-System1 methods surge, exploring the System 2 reasoning knowledge via inference-time computation and compressing the explored knowledge into System 1 process. In this paper, we focus on code generation, which is a representative System 2 task, and identify two primary challenges: (1) the complex hidden reasoning processes and (2) the heterogeneous data distributions that complicate the exploration and training of robust LLM solvers. To tackle these issues, we propose a novel BDC framework that explores insightful System 2 knowledge of LLMs using a MC-Tree-Of-Agents algorithm with mutual \textbf{B}oosting, \textbf{D}isentangles the heterogeneous training data for composable LoRA-experts, and obtain \textbf{C}ustomized problem solver for each data instance with an input-aware hypernetwork to weight over the LoRA-experts, offering effectiveness, flexibility, and robustness. This framework leverages multiple LLMs through mutual verification and boosting, integrated into a Monte-Carlo Tree Search process enhanced by reflection-based pruning and refinement. Additionally, we introduce the DisenLora algorithm, which clusters heterogeneous data to fine-tune LLMs into composable Lora experts, enabling the adaptive generation of customized problem solvers through an input-aware hypernetwork. This work lays the groundwork for advancing LLM capabilities in complex reasoning tasks, offering a novel System2-to-System1 solution.
ELCoRec: Enhance Language Understanding with Co-Propagation of Numerical and Categorical Features for Recommendation
Jun 27, 2024



Large language models have been flourishing in the natural language processing (NLP) domain, and their potential for recommendation has been paid much attention to. Despite the intelligence shown by the recommendation-oriented finetuned models, LLMs struggle to fully understand the user behavior patterns due to their innate weakness in interpreting numerical features and the overhead for long context, where the temporal relations among user behaviors, subtle quantitative signals among different ratings, and various side features of items are not well explored. Existing works only fine-tune a sole LLM on given text data without introducing that important information to it, leaving these problems unsolved. In this paper, we propose ELCoRec to Enhance Language understanding with CoPropagation of numerical and categorical features for Recommendation. Concretely, we propose to inject the preference understanding capability into LLM via a GAT expert model where the user preference is better encoded by parallelly propagating the temporal relations, and rating signals as well as various side information of historical items. The parallel propagation mechanism could stabilize heterogeneous features and offer an informative user preference encoding, which is then injected into the language models via soft prompting at the cost of a single token embedding. To further obtain the user's recent interests, we proposed a novel Recent interaction Augmented Prompt (RAP) template. Experiment results over three datasets against strong baselines validate the effectiveness of ELCoRec. The code is available at https://anonymous.4open.science/r/CIKM_Code_Repo-E6F5/README.md.