 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Humanity's Last Code Exam: Can Advanced LLMs Conquer Human's Hardest Code Competition?
Jun 15, 2025Code generation is a core capability of large language models (LLMs), yet mainstream benchmarks (e.g., APPs and LiveCodeBench) contain questions with medium-level difficulty and pose no challenge to advanced LLMs. To better reflected the advanced reasoning and code generation ability, We introduce Humanity's Last Code Exam (HLCE), comprising 235 most challenging problems from the International Collegiate Programming Contest (ICPC World Finals) and the International Olympiad in Informatics (IOI) spanning 2010 - 2024. As part of HLCE, we design a harmonized online-offline sandbox that guarantees fully reproducible evaluation. Through our comprehensive evaluation, we observe that even the strongest reasoning LLMs: o4-mini(high) and Gemini-2.5 Pro, achieve pass@1 rates of only 15.9% and 11.4%, respectively. Meanwhile, we propose a novel "self-recognition" task to measure LLMs' awareness of their own capabilities. Results indicate that LLMs' self-recognition abilities are not proportionally correlated with their code generation performance. Finally, our empirical validation of test-time scaling laws reveals that current advanced LLMs have substantial room for improvement on complex programming tasks. We expect HLCE to become a milestone challenge for code generation and to catalyze advances in high-performance reasoning and human-AI collaborative programming. Our code and dataset are also public available(https://github.com/Humanity-s-Last-Code-Exam/HLCE).
NL-Debugging: Exploiting Natural Language as an Intermediate Representation for Code Debugging
May 21, 2025Debugging is a critical aspect of LLM's coding ability. Early debugging efforts primarily focused on code-level analysis, which often falls short when addressing complex programming errors that require a deeper understanding of algorithmic logic. Recent advancements in large language models (LLMs) have shifted attention toward leveraging natural language reasoning to enhance code-related tasks. However, two fundamental questions remain unanswered: What type of natural language format is most effective for debugging tasks? And what specific benefits does natural language reasoning bring to the debugging process? In this paper, we introduce NL-DEBUGGING, a novel framework that employs natural language as an intermediate representation to improve code debugging. By debugging at a natural language level, we demonstrate that NL-DEBUGGING outperforms traditional debugging methods and enables a broader modification space through direct refinement guided by execution feedback. Our findings highlight the potential of natural language reasoning to advance automated code debugging and address complex programming challenges.
Instruction-Tuning Data Synthesis from Scratch via Web Reconstruction
Apr 22, 2025The improvement of LLMs' instruction-following capabilities depends critically on the availability of high-quality instruction-response pairs. While existing automatic data synthetic methods alleviate the burden of manual curation, they often rely heavily on either the quality of seed data or strong assumptions about the structure and content of web documents. To tackle these challenges, we propose Web Reconstruction (WebR), a fully automated framework for synthesizing high-quality instruction-tuning (IT) data directly from raw web documents with minimal assumptions. Leveraging the inherent diversity of raw web content, we conceptualize web reconstruction as an instruction-tuning data synthesis task via a novel dual-perspective paradigm--Web as Instruction and Web as Response--where each web document is designated as either an instruction or a response to trigger the reconstruction process. Comprehensive experiments show that datasets generated by WebR outperform state-of-the-art baselines by up to 16.65% across four instruction-following benchmarks. Notably, WebR demonstrates superior compatibility, data efficiency, and scalability, enabling enhanced domain adaptation with minimal effort. The data and code are publicly available at https://github.com/YJiangcm/WebR.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
AdvKT: An Adversarial Multi-Step Training Framework for Knowledge Tracing
Apr 07, 2025Knowledge Tracing (KT) monitors students' knowledge states and simulates their responses to question sequences. Existing KT models typically follow a single-step training paradigm, which leads to discrepancies with the multi-step inference process required in real-world simulations, resulting in significant error accumulation. This accumulation of error, coupled with the issue of data sparsity, can substantially degrade the performance of recommendation models in the intelligent tutoring systems. To address these challenges, we propose a novel Adversarial Multi-Step Training Framework for Knowledge Tracing (AdvKT), which, for the first time, focuses on the multi-step KT task. More specifically, AdvKT leverages adversarial learning paradigm involving a generator and a discriminator. The generator mimics high-reward responses, effectively reducing error accumulation across multiple steps, while the discriminator provides feedback to generate synthetic data. Additionally, we design specialized data augmentation techniques to enrich the training data with realistic variations, ensuring that the model generalizes well even in scenarios with sparse data. Experiments conducted on four real-world datasets demonstrate the superiority of AdvKT over existing KT models, showcasing its ability to address both error accumulation and data sparsity issues effectively.
LLM4Tag: Automatic Tagging System for Information Retrieval via Large Language Models
Feb 19, 2025



Tagging systems play an essential role in various information retrieval applications such as search engines and recommender systems. Recently, Large Language Models (LLMs) have been applied in tagging systems due to their extensive world knowledge, semantic understanding, and reasoning capabilities. Despite achieving remarkable performance, existing methods still have limitations, including difficulties in retrieving relevant candidate tags comprehensively, challenges in adapting to emerging domain-specific knowledge, and the lack of reliable tag confidence quantification. To address these three limitations above, we propose an automatic tagging system LLM4Tag. First, a graph-based tag recall module is designed to effectively and comprehensively construct a small-scale highly relevant candidate tag set. Subsequently, a knowledge-enhanced tag generation module is employed to generate accurate tags with long-term and short-term knowledge injection. Finally, a tag confidence calibration module is introduced to generate reliable tag confidence scores. Extensive experiments over three large-scale industrial datasets show that LLM4Tag significantly outperforms the state-of-the-art baselines and LLM4Tag has been deployed online for content tagging to serve hundreds of millions of users.
Boost, Disentangle, and Customize: A Robust System2-to-System1 Pipeline for Code Generation
Feb 18, 2025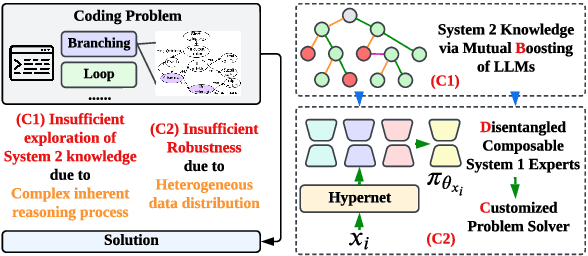
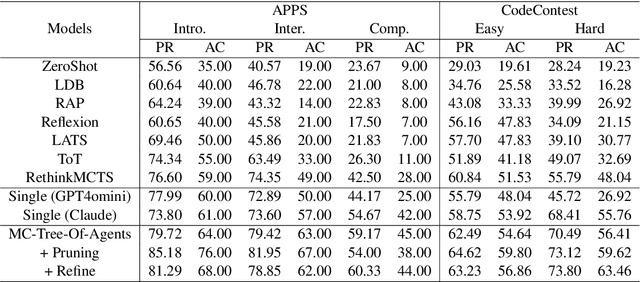
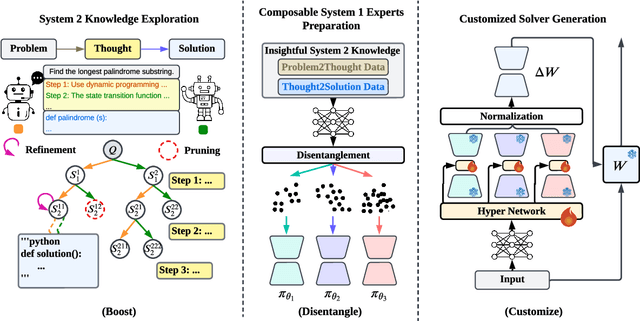
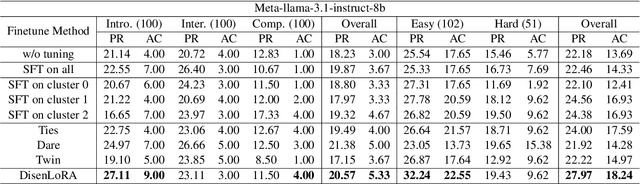
Large language models (LLMs) have demonstrated remarkable capabilities in various domains, particularly in system 1 tasks, yet the intricacies of their problem-solving mechanisms in system 2 tasks are not sufficiently explored. Recent research on System2-to-System1 methods surge, exploring the System 2 reasoning knowledge via inference-time computation and compressing the explored knowledge into System 1 process. In this paper, we focus on code generation, which is a representative System 2 task, and identify two primary challenges: (1) the complex hidden reasoning processes and (2) the heterogeneous data distributions that complicate the exploration and training of robust LLM solvers. To tackle these issues, we propose a novel BDC framework that explores insightful System 2 knowledge of LLMs using a MC-Tree-Of-Agents algorithm with mutual \textbf{B}oosting, \textbf{D}isentangles the heterogeneous training data for composable LoRA-experts, and obtain \textbf{C}ustomized problem solver for each data instance with an input-aware hypernetwork to weight over the LoRA-experts, offering effectiveness, flexibility, and robustness. This framework leverages multiple LLMs through mutual verification and boosting, integrated into a Monte-Carlo Tree Search process enhanced by reflection-based pruning and refinement. Additionally, we introduce the DisenLora algorithm, which clusters heterogeneous data to fine-tune LLMs into composable Lora experts, enabling the adaptive generation of customized problem solvers through an input-aware hypernetwork. This work lays the groundwork for advancing LLM capabilities in complex reasoning tasks, offering a novel System2-to-System1 solution.
A Survey on Multi-Turn Interaction Capabilities of Large Language Models
Jan 17, 2025Multi-turn interaction in the dialogue system research refers to a system's ability to maintain context across multiple dialogue turns, enabling it to generate coherent and contextually relevant responses. Recent advancements in large language models (LLMs) have significantly expanded the scope of multi-turn interaction, moving beyond chatbots to enable more dynamic agentic interactions with users or environments. In this paper, we provide a focused review of the multi-turn capabilities of LLMs, which are critical for a wide range of downstream applications, including conversational search and recommendation, consultation services, and interactive tutoring. This survey explores four key aspects: (1) the core model capabilities that contribute to effective multi-turn interaction, (2) how multi-turn interaction is evaluated in current practice, (3) the general algorithms used to enhance multi-turn interaction, and (4) potential future directions for research in this field.
RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation
Sep 15, 2024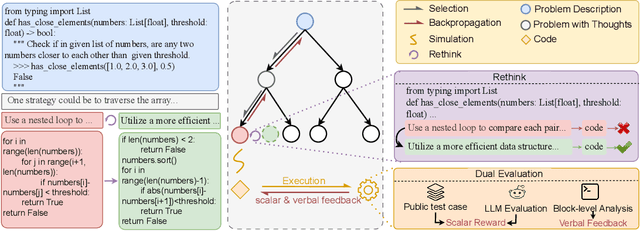

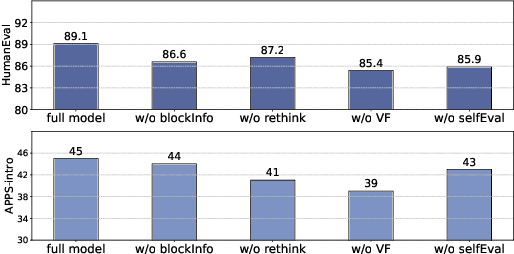

LLM agents enhanced by tree search algorithms have yielded notable performances in code generation. However, current search algorithms in this domain suffer from low search quality due to several reasons: 1) Ineffective design of the search space for the high-reasoning demands of code generation tasks, 2) Inadequate integration of code feedback with the search algorithm, and 3) Poor handling of negative feedback during the search, leading to reduced search efficiency and quality. To address these challenges, we propose to search for the reasoning process of the code and use the detailed feedback of code execution to refine erroneous thoughts during the search. In this paper, we introduce RethinkMCTS, which employs the Monte Carlo Tree Search (MCTS) algorithm to conduct thought-level searches before generating code, thereby exploring a wider range of strategies. More importantly, we construct verbal feedback from fine-grained code execution feedback to refine erroneous thoughts during the search. This ensures that the search progresses along the correct reasoning paths, thus improving the overall search quality of the tree by leveraging execution feedback. Through extensive experiments, we demonstrate that RethinkMCTS outperforms previous search-based and feedback-based code generation baselines. On the HumanEval dataset, it improves the pass@1 of GPT-3.5-turbo from 70.12 to 89.02 and GPT-4o-mini from 87.20 to 94.51. It effectively conducts more thorough exploration through thought-level searches and enhances the search quality of the entire tree by incorporating rethink operation.