 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoDeepSeek: Benchmarking Agentic Information Seeking for Retrieval-Augmented Generation
May 21, 2025Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by grounding responses with retrieved information. As an emerging paradigm, Agentic RAG further enhances this process by introducing autonomous LLM agents into the information seeking process. However, existing benchmarks fall short in evaluating such systems, as they are confined to a static retrieval environment with a fixed, limited corpus} and simple queries that fail to elicit agentic behavior. Moreover, their evaluation protocols assess information seeking effectiveness by pre-defined gold sets of documents, making them unsuitable for the open-ended and dynamic nature of real-world web environments. To bridge this gap, we present InfoDeepSeek, a new benchmark with challenging questions designed for assessing agentic information seeking in real-world, dynamic web environments. We propose a systematic methodology for constructing challenging queries satisfying the criteria of determinacy, difficulty, and diversity. Based on this, we develop the first evaluation framework tailored to dynamic agentic information seeking, including fine-grained metrics about the accuracy, utility, and compactness of information seeking outcomes. Through extensive experiments across LLMs, search engines, and question types, InfoDeepSeek reveals nuanced agent behaviors and offers actionable insights for future research.
LLM4Tag: Automatic Tagging System for Information Retrieval via Large Language Models
Feb 19, 2025



Tagging systems play an essential role in various information retrieval applications such as search engines and recommender systems. Recently, Large Language Models (LLMs) have been applied in tagging systems due to their extensive world knowledge, semantic understanding, and reasoning capabilities. Despite achieving remarkable performance, existing methods still have limitations, including difficulties in retrieving relevant candidate tags comprehensively, challenges in adapting to emerging domain-specific knowledge, and the lack of reliable tag confidence quantification. To address these three limitations above, we propose an automatic tagging system LLM4Tag. First, a graph-based tag recall module is designed to effectively and comprehensively construct a small-scale highly relevant candidate tag set. Subsequently, a knowledge-enhanced tag generation module is employed to generate accurate tags with long-term and short-term knowledge injection. Finally, a tag confidence calibration module is introduced to generate reliable tag confidence scores. Extensive experiments over three large-scale industrial datasets show that LLM4Tag significantly outperforms the state-of-the-art baselines and LLM4Tag has been deployed online for content tagging to serve hundreds of millions of users.
An Automatic Graph Construction Framework based on Large Language Models for Recommendation
Dec 24, 2024Graph neural networks (GNNs) have emerged as state-of-the-art methods to learn from graph-structured data for recommendation. However, most existing GNN-based recommendation methods focus on the optimization of model structures and learning strategies based on pre-defined graphs, neglecting the importance of the graph construction stage. Earlier works for graph construction usually rely on speciffic rules or crowdsourcing, which are either too simplistic or too labor-intensive. Recent works start to utilize large language models (LLMs) to automate the graph construction, in view of their abundant open-world knowledge and remarkable reasoning capabilities. Nevertheless, they generally suffer from two limitations: (1) invisibility of global view (e.g., overlooking contextual information) and (2) construction inefficiency. To this end, we introduce AutoGraph, an automatic graph construction framework based on LLMs for recommendation. Specifically, we first use LLMs to infer the user preference and item knowledge, which is encoded as semantic vectors. Next, we employ vector quantization to extract the latent factors from the semantic vectors. The latent factors are then incorporated as extra nodes to link the user/item nodes, resulting in a graph with in-depth global-view semantics. We further design metapath-based message aggregation to effectively aggregate the semantic and collaborative information. The framework is model-agnostic and compatible with different backbone models. Extensive experiments on three real-world datasets demonstrate the efficacy and efffciency of AutoGraph compared to existing baseline methods. We have deployed AutoGraph in Huawei advertising platform, and gain a 2.69% improvement on RPM and a 7.31% improvement on eCPM in the online A/B test. Currently AutoGraph has been used as the main trafffc model, serving hundreds of millions of people.
AIE: Auction Information Enhanced Framework for CTR Prediction in Online Advertising
Aug 15, 2024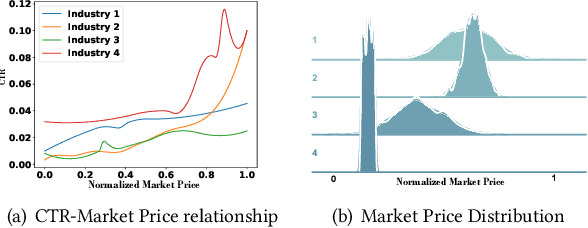
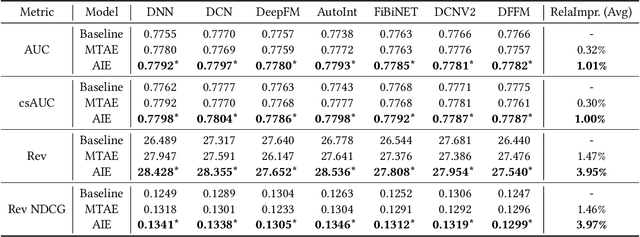
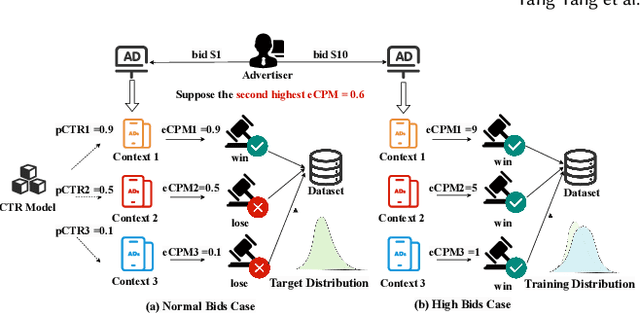
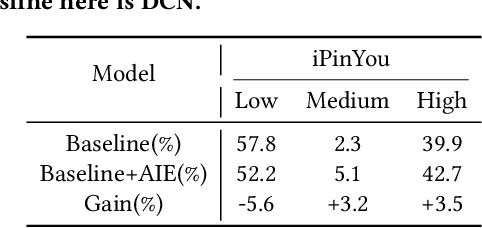
Click-Through Rate (CTR) prediction is a fundamental technique for online advertising recommendation and the complex online competitive auction process also brings many difficulties to CTR optimization. Recent studies have shown that introducing posterior auction information contributes to the performance of CTR prediction. However, existing work doesn't fully capitalize on the benefits of auction information and overlooks the data bias brought by the auction, leading to biased and suboptimal results. To address these limitations, we propose Auction Information Enhanced Framework (AIE) for CTR prediction in online advertising, which delves into the problem of insufficient utilization of auction signals and first reveals the auction bias. Specifically, AIE introduces two pluggable modules, namely Adaptive Market-price Auxiliary Module (AM2) and Bid Calibration Module (BCM), which work collaboratively to excavate the posterior auction signals better and enhance the performance of CTR prediction. Furthermore, the two proposed modules are lightweight, model-agnostic, and friendly to inference latency. Extensive experiments are conducted on a public dataset and an industrial dataset to demonstrate the effectiveness and compatibility of AIE. Besides, a one-month online A/B test in a large-scale advertising platform shows that AIE improves the base model by 5.76% and 2.44% in terms of eCPM and CTR, respectively.
A Decoding Acceleration Framework for Industrial Deployable LLM-based Recommender Systems
Aug 11, 2024Recently, increasing attention has been paid to LLM-based recommender systems, but their deployment is still under exploration in the industry. Most deployments utilize LLMs as feature enhancers, generating augmentation knowledge in the offline stage. However, in recommendation scenarios, involving numerous users and items, even offline generation with LLMs consumes considerable time and resources. This generation inefficiency stems from the autoregressive nature of LLMs, and a promising direction for acceleration is speculative decoding, a Draft-then-Verify paradigm that increases the number of generated tokens per decoding step. In this paper, we first identify that recommendation knowledge generation is suitable for retrieval-based speculative decoding. Then, we discern two characteristics: (1) extensive items and users in RSs bring retrieval inefficiency, and (2) RSs exhibit high diversity tolerance for text generated by LLMs. Based on the above insights, we propose a Decoding Acceleration Framework for LLM-based Recommendation (dubbed DARE), with Customized Retrieval Pool to improve retrieval efficiency and Relaxed Verification to increase the acceptance rate of draft tokens, respectively. Extensive experiments demonstrate that DARE achieves a 3-5x speedup and is compatible with various frameworks and backbone LLMs. DARE has also been deployed to online advertising scenarios within a large-scale commercial environment, achieving a 3.45x speedup while maintaining the downstream performance.
Retrieval-Oriented Knowledge for Click-Through Rate Prediction
Apr 28, 2024

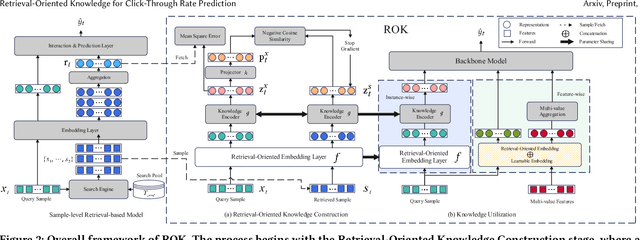

Click-through rate (CTR) prediction plays an important role in personalized recommendations. Recently, sample-level retrieval-based models (e.g., RIM) have achieved remarkable performance by retrieving and aggregating relevant samples. However, their inefficiency at the inference stage makes them impractical for industrial applications. To overcome this issue, this paper proposes a universal plug-and-play Retrieval-Oriented Knowledge (ROK) framework. Specifically, a knowledge base, consisting of a retrieval-oriented embedding layer and a knowledge encoder, is designed to preserve and imitate the retrieved & aggregated representations in a decomposition-reconstruction paradigm. Knowledge distillation and contrastive learning methods are utilized to optimize the knowledge base, and the learned retrieval-enhanced representations can be integrated with arbitrary CTR models in both instance-wise and feature-wise manners. Extensive experiments on three large-scale datasets show that ROK achieves competitive performance with the retrieval-based CTR models while reserving superior inference efficiency and model compatibility.
Scenario-Aware Hierarchical Dynamic Network for Multi-Scenario Recommendation
Sep 05, 2023



Click-Through Rate (CTR) prediction is a fundamental technique in recommendation and advertising systems. Recent studies have shown that implementing multi-scenario recommendations contributes to strengthening information sharing and improving overall performance. However, existing multi-scenario models only consider coarse-grained explicit scenario modeling that depends on pre-defined scenario identification from manual prior rules, which is biased and sub-optimal. To address these limitations, we propose a Scenario-Aware Hierarchical Dynamic Network for Multi-Scenario Recommendations (HierRec), which perceives implicit patterns adaptively and conducts explicit and implicit scenario modeling jointly. In particular, HierRec designs a basic scenario-oriented module based on the dynamic weight to capture scenario-specific information. Then the hierarchical explicit and implicit scenario-aware modules are proposed to model hybrid-grained scenario information. The multi-head implicit modeling design contributes to perceiving distinctive patterns from different perspectives. Our experiments on two public datasets and real-world industrial applications on a mainstream online advertising platform demonstrate that our HierRec outperforms existing models significantly.
Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation
Jun 07, 2023



With the development of the online education system, personalized education recommendation has played an essential role. In this paper, we focus on developing path recommendation systems that aim to generating and recommending an entire learning path to the given user in each session. Noticing that existing approaches fail to consider the correlations of concepts in the path, we propose a novel framework named Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation (SRC), which formulates the recommendation task under a set-to-sequence paradigm. Specifically, we first design a concept-aware encoder module which can capture the correlations among the input learning concepts. The outputs are then fed into a decoder module that sequentially generates a path through an attention mechanism that handles correlations between the learning and target concepts. Our recommendation policy is optimized by policy gradient. In addition, we also introduce an auxiliary module based on knowledge tracing to enhance the model's stability by evaluating students' learning effects on learning concepts. We conduct extensive experiments on two real-world public datasets and one industrial dataset, and the experimental results demonstrate the superiority and effectiveness of SRC. Code will be available at https://gitee.com/mindspore/models/tree/master/research/recommend/SRC.
Planning Immediate Landmarks of Targets for Model-Free Skill Transfer across Agents
Dec 18, 2022In reinforcement learning applications like robotics, agents usually need to deal with various input/output features when specified with different state/action spaces by their developers or physical restrictions. This indicates unnecessary re-training from scratch and considerable sample inefficiency, especially when agents follow similar solution steps to achieve tasks. In this paper, we aim to transfer similar high-level goal-transition knowledge to alleviate the challenge. Specifically, we propose PILoT, i.e., Planning Immediate Landmarks of Targets. PILoT utilizes the universal decoupled policy optimization to learn a goal-conditioned state planner; then, distills a goal-planner to plan immediate landmarks in a model-free style that can be shared among different agents. In our experiments, we show the power of PILoT on various transferring challenges, including few-shot transferring across action spaces and dynamics, from low-dimensional vector states to image inputs, from simple robot to complicated morphology; and we also illustrate a zero-shot transfer solution from a simple 2D navigation task to the harder Ant-Maze task.
Generative Adversarial Exploration for Reinforcement Learning
Jan 27, 2022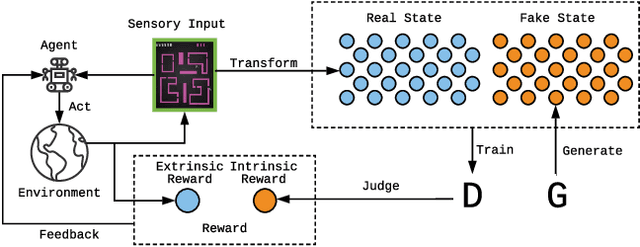
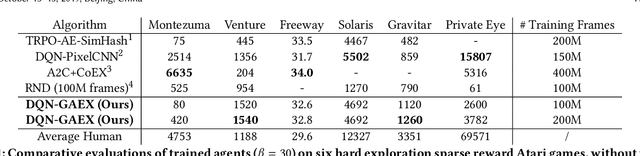
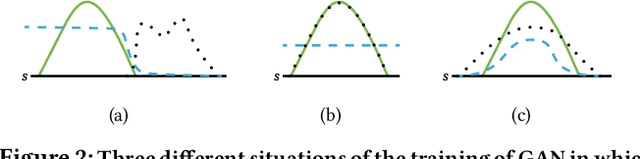
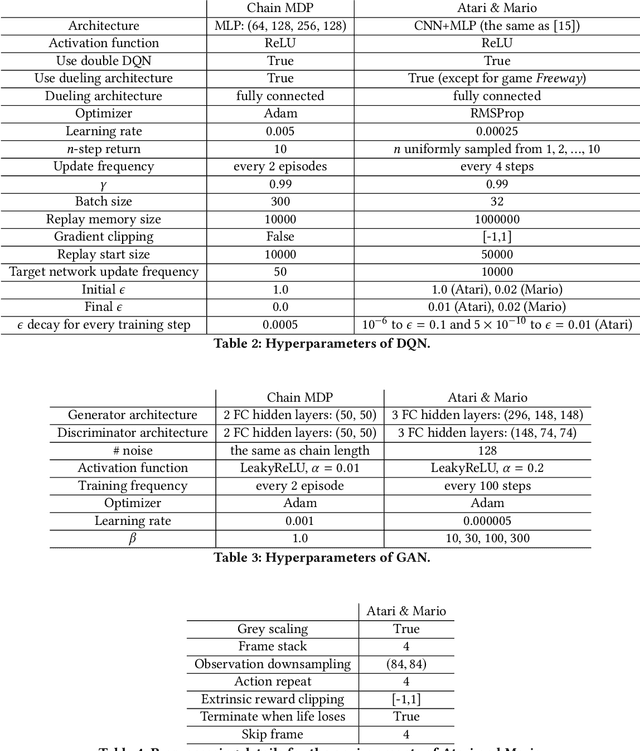
Exploration is crucial for training the optimal reinforcement learning (RL) policy, where the key is to discriminate whether a state visiting is novel. Most previous work focuses on designing heuristic rules or distance metrics to check whether a state is novel without considering such a discrimination process that can be learned. In this paper, we propose a novel method called generative adversarial exploration (GAEX) to encourage exploration in RL via introducing an intrinsic reward output from a generative adversarial network, where the generator provides fake samples of states that help discriminator identify those less frequently visited states. Thus the agent is encouraged to visit those states which the discriminator is less confident to judge as visited. GAEX is easy to implement and of high training efficiency. In our experiments, we apply GAEX into DQN and the DQN-GAEX algorithm achieves convincing performance on challenging exploration problems, including the game Venture, Montezuma's Revenge and Super Mario Bros, without further fine-tuning on complicate learning algorithms. To our knowledge, this is the first work to employ GAN in RL exploration problems.