 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAR-MAER: Metric-Aware and Ambiguity-Adaptive Autoregressive Image Generation
Apr 02, 2026Autoregressive (AR) models have demonstrated significant success in the realm of text-to-image generation. However, they usually face two major challenges. Firstly, the generated images may not always meet the quality standards expected by humans. Furthermore, these models face difficulty when dealing with ambiguous prompts that could be interpreted in several valid ways. To address these issues, we introduce MAR-MAER, an innovative hierarchical autoregressive framework. It combines two main components. It is a metric-aware embedding regularization method. The other one is a probabilistic latent model used for handling ambiguous semantics. Our method utilizes a lightweight projection head, which is trained with an adaptive kernel regression loss function. This aligns the model's internal representations with human-preferred quality metrics, such as CLIPScore and HPSv2. As a result, the embedding space that is learned more accurately reflects human judgment. We are also introducing a conditional variational module. This approach incorporates an aspect of controlled randomness within the hierarchical token generation process. This capability allows the model to produce a diverse array of coherent images based on ambiguous or open-ended prompts. We conducted extensive experiments using COCO and a newly developed Ambiguous-Prompt Benchmark. The results show that MAR-MAER achieves excellent performance in both metric consistency and semantic flexibility. It exceeds the baseline Hi-MAR model's performance, showing an improvement of +1.6 in CLIPScore and +5.3 in HPSv2. For unclear inputs, it produces a notably wider range of outputs. These findings have been confirmed through both human evaluation and automated metrics.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Jun 17, 2024



We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Mar 11, 2024
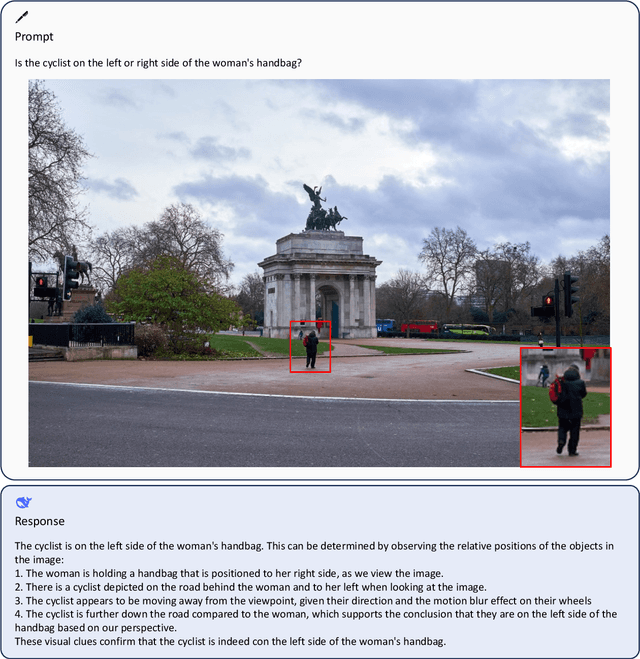
We present DeepSeek-VL, an open-source Vision-Language (VL) Model designed for real-world vision and language understanding applications. Our approach is structured around three key dimensions: We strive to ensure our data is diverse, scalable, and extensively covers real-world scenarios including web screenshots, PDFs, OCR, charts, and knowledge-based content, aiming for a comprehensive representation of practical contexts. Further, we create a use case taxonomy from real user scenarios and construct an instruction tuning dataset accordingly. The fine-tuning with this dataset substantially improves the model's user experience in practical applications. Considering efficiency and the demands of most real-world scenarios, DeepSeek-VL incorporates a hybrid vision encoder that efficiently processes high-resolution images (1024 x 1024), while maintaining a relatively low computational overhead. This design choice ensures the model's ability to capture critical semantic and detailed information across various visual tasks. We posit that a proficient Vision-Language Model should, foremost, possess strong language abilities. To ensure the preservation of LLM capabilities during pretraining, we investigate an effective VL pretraining strategy by integrating LLM training from the beginning and carefully managing the competitive dynamics observed between vision and language modalities. The DeepSeek-VL family (both 1.3B and 7B models) showcases superior user experiences as a vision-language chatbot in real-world applications, achieving state-of-the-art or competitive performance across a wide range of visual-language benchmarks at the same model size while maintaining robust performance on language-centric benchmarks. We have made both 1.3B and 7B models publicly accessible to foster innovations based on this foundation model.
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Jan 26, 2024



The rapid development of large language models has revolutionized code intelligence in software development. However, the predominance of closed-source models has restricted extensive research and development. To address this, we introduce the DeepSeek-Coder series, a range of open-source code models with sizes from 1.3B to 33B, trained from scratch on 2 trillion tokens. These models are pre-trained on a high-quality project-level code corpus and employ a fill-in-the-blank task with a 16K window to enhance code generation and infilling. Our extensive evaluations demonstrate that DeepSeek-Coder not only achieves state-of-the-art performance among open-source code models across multiple benchmarks but also surpasses existing closed-source models like Codex and GPT-3.5. Furthermore, DeepSeek-Coder models are under a permissive license that allows for both research and unrestricted commercial use.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation
Jun 07, 2023



With the development of the online education system, personalized education recommendation has played an essential role. In this paper, we focus on developing path recommendation systems that aim to generating and recommending an entire learning path to the given user in each session. Noticing that existing approaches fail to consider the correlations of concepts in the path, we propose a novel framework named Set-to-Sequence Ranking-based Concept-aware Learning Path Recommendation (SRC), which formulates the recommendation task under a set-to-sequence paradigm. Specifically, we first design a concept-aware encoder module which can capture the correlations among the input learning concepts. The outputs are then fed into a decoder module that sequentially generates a path through an attention mechanism that handles correlations between the learning and target concepts. Our recommendation policy is optimized by policy gradient. In addition, we also introduce an auxiliary module based on knowledge tracing to enhance the model's stability by evaluating students' learning effects on learning concepts. We conduct extensive experiments on two real-world public datasets and one industrial dataset, and the experimental results demonstrate the superiority and effectiveness of SRC. Code will be available at https://gitee.com/mindspore/models/tree/master/research/recommend/SRC.
Advanced Tri-Sectoral Multi-User Millimeter-Wave Smart Repeater
Oct 10, 2022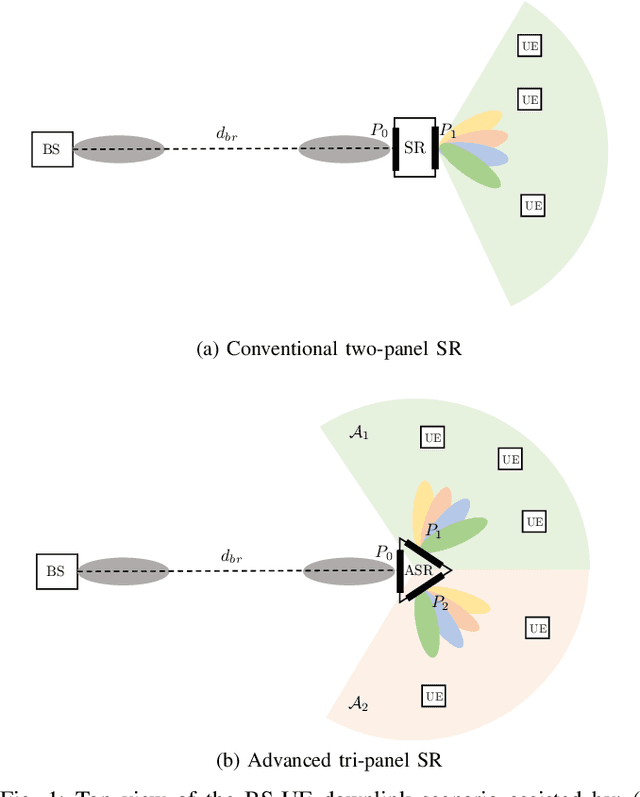
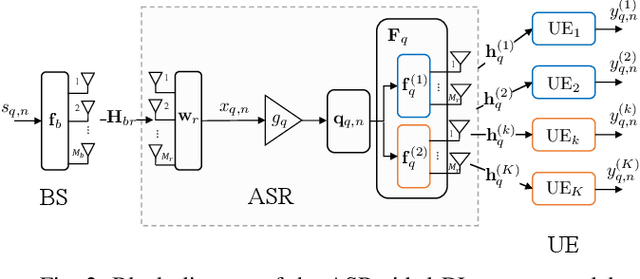
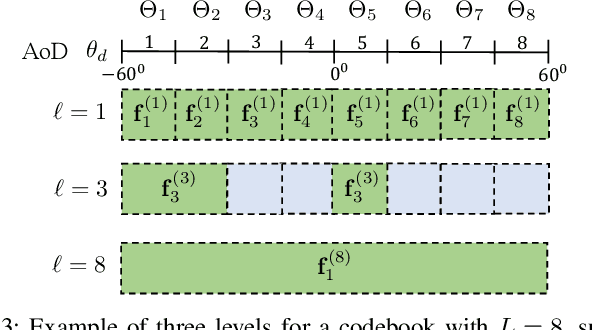
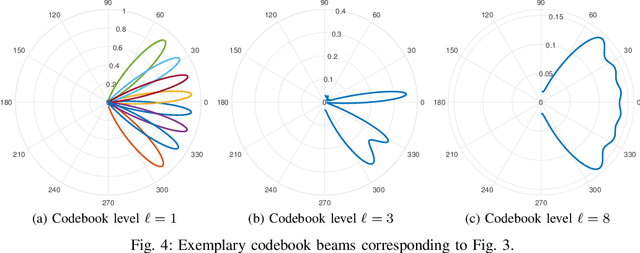
Smart Repeaters (SR) can potentially enhance the coverage in Millimeter-wave (mmWave) wireless communications. However, the angular coverage of the existing two-panel SR is too limited to make the SR a truly cost-effective mmWave range extender. This paper proposes the usage of a tri-sectoral Advanced SR (ASR) to extend the angular coverage with respect to conventional SR. We propose a multi-user precoder optimization for ASR in a downlink multi-carrier communication system to maximize the number of served User Equipments (UEs) while guaranteeing constraints on per-UE rate and time-frequency resources. Numerical results show the benefits of the ASR against conventional SR in terms of both cumulative spectral efficiency and number of served UEs (both improved by an average factor 2), varying the system parameters.