 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Hitem3D 2.0: Multi-View Guided Native 3D Texture Generation
Apr 10, 2026Although recent advances have improved the quality of 3D texture generation, existing methods still struggle with incomplete texture coverage, cross-view inconsistency, and misalignment between geometry and texture. To address these limitations, we propose Hitem3D 2.0, a multi-view guided native 3D texture generation framework that enhances texture quality through the integration of 2D multi-view generation priors and native 3D texture representations. Hitem3D 2.0 comprises two key components: a multi-view synthesis framework and a native 3D texture generation model. The multi-view generation is built upon a pre-trained image editing backbone and incorporates plug-and-play modules that explicitly promote geometric alignment, cross-view consistency, and illumination uniformity, thereby enabling the synthesis of high-fidelity multi-view images. Conditioned on the generated views and 3D geometry, the native 3D texture generation model projects multi-view textures onto 3D surfaces while plausibly completing textures in unseen regions. Through the integration of multi-view consistency constraints with native 3D texture modeling, Hitem3D 2.0 significantly improves texture completeness, cross-view coherence, and geometric alignment. Experimental results demonstrate that Hitem3D 2.0 outperforms existing methods in terms of texture detail, fidelity, consistency, coherence, and alignment.
daVinci-Env: Open SWE Environment Synthesis at Scale
Mar 16, 2026Training capable software engineering (SWE) agents demands large-scale, executable, and verifiable environments that provide dynamic feedback loops for iterative code editing, test execution, and solution refinement. However, existing open-source datasets remain limited in scale and repository diversity, while industrial solutions are opaque with unreleased infrastructure, creating a prohibitive barrier for most academic research groups. We present OpenSWE, the largest fully transparent framework for SWE agent training in Python, comprising 45,320 executable Docker environments spanning over 12.8k repositories, with all Dockerfiles, evaluation scripts, and infrastructure fully open-sourced for reproducibility. OpenSWE is built through a multi-agent synthesis pipeline deployed across a 64-node distributed cluster, automating repository exploration, Dockerfile construction, evaluation script generation, and iterative test analysis. Beyond scale, we propose a quality-centric filtering pipeline that characterizes the inherent difficulty of each environment, filtering out instances that are either unsolvable or insufficiently challenging and retaining only those that maximize learning efficiency. With $891K spent on environment construction and an additional $576K on trajectory sampling and difficulty-aware curation, the entire project represents a total investment of approximately $1.47 million, yielding about 13,000 curated trajectories from roughly 9,000 quality guaranteed environments. Extensive experiments validate OpenSWE's effectiveness: OpenSWE-32B and OpenSWE-72B achieve 62.4% and 66.0% on SWE-bench Verified, establishing SOTA among Qwen2.5 series. Moreover, SWE-focused training yields substantial out-of-domain improvements, including up to 12 points on mathematical reasoning and 5 points on science benchmarks, without degrading factual recall.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
DeepSeek-OCR 2: Visual Causal Flow
Jan 28, 2026We present DeepSeek-OCR 2 to investigate the feasibility of a novel encoder-DeepEncoder V2-capable of dynamically reordering visual tokens upon image semantics. Conventional vision-language models (VLMs) invariably process visual tokens in a rigid raster-scan order (top-left to bottom-right) with fixed positional encoding when fed into LLMs. However, this contradicts human visual perception, which follows flexible yet semantically coherent scanning patterns driven by inherent logical structures. Particularly for images with complex layouts, human vision exhibits causally-informed sequential processing. Inspired by this cognitive mechanism, DeepEncoder V2 is designed to endow the encoder with causal reasoning capabilities, enabling it to intelligently reorder visual tokens prior to LLM-based content interpretation. This work explores a novel paradigm: whether 2D image understanding can be effectively achieved through two-cascaded 1D causal reasoning structures, thereby offering a new architectural approach with the potential to achieve genuine 2D reasoning. Codes and model weights are publicly accessible at http://github.com/deepseek-ai/DeepSeek-OCR-2.
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Jan 12, 2026While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embedding for O(1) lookup. By formulating the Sparsity Allocation problem, we uncover a U-shaped scaling law that optimizes the trade-off between neural computation (MoE) and static memory (Engram). Guided by this law, we scale Engram to 27B parameters, achieving superior performance over a strictly iso-parameter and iso-FLOPs MoE baseline. Most notably, while the memory module is expected to aid knowledge retrieval (e.g., MMLU +3.4; CMMLU +4.0), we observe even larger gains in general reasoning (e.g., BBH +5.0; ARC-Challenge +3.7) and code/math domains~(HumanEval +3.0; MATH +2.4). Mechanistic analyses reveal that Engram relieves the backbone's early layers from static reconstruction, effectively deepening the network for complex reasoning. Furthermore, by delegating local dependencies to lookups, it frees up attention capacity for global context, substantially boosting long-context retrieval (e.g., Multi-Query NIAH: 84.2 to 97.0). Finally, Engram establishes infrastructure-aware efficiency: its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead. We envision conditional memory as an indispensable modeling primitive for next-generation sparse models.
Incorporating Inductive Biases to Energy-based Generative Models
May 02, 2025



With the advent of score-matching techniques for model training and Langevin dynamics for sample generation, energy-based models (EBMs) have gained renewed interest as generative models. Recent EBMs usually use neural networks to define their energy functions. In this work, we introduce a novel hybrid approach that combines an EBM with an exponential family model to incorporate inductive bias into data modeling. Specifically, we augment the energy term with a parameter-free statistic function to help the model capture key data statistics. Like an exponential family model, the hybrid model aims to align the distribution statistics with data statistics during model training, even when it only approximately maximizes the data likelihood. This property enables us to impose constraints on the hybrid model. Our empirical study validates the hybrid model's ability to match statistics. Furthermore, experimental results show that data fitting and generation improve when suitable informative statistics are incorporated into the hybrid model.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
Graph-based Confidence Calibration for Large Language Models
Nov 03, 2024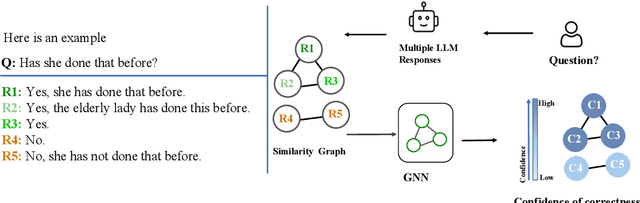
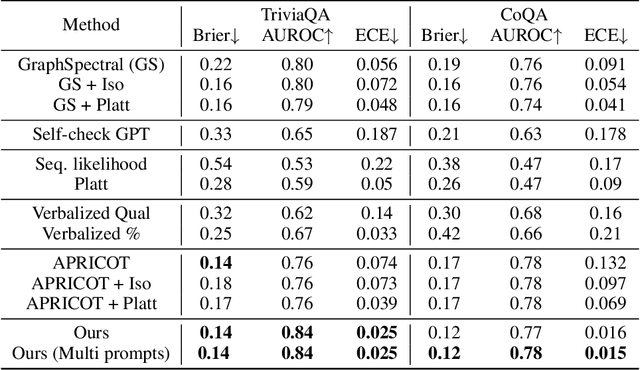
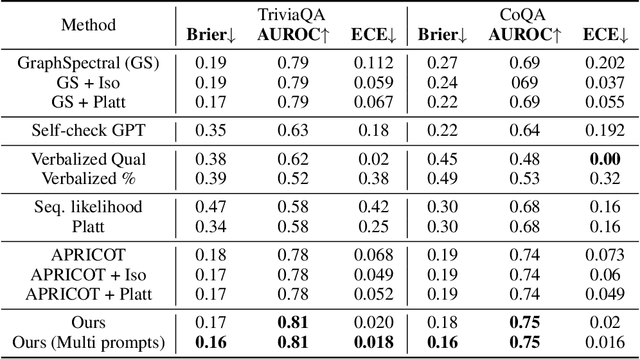
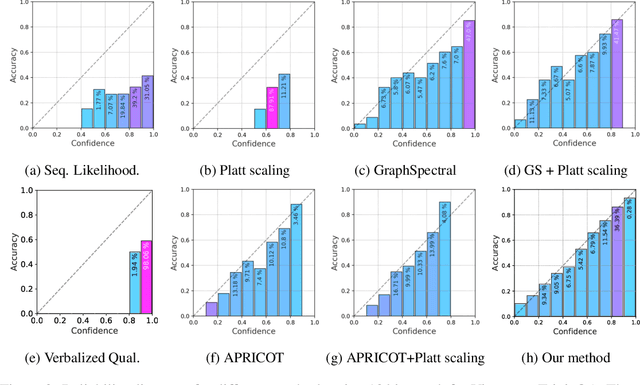
One important approach to improving the reliability of large language models (LLMs) is to provide accurate confidence estimations regarding the correctness of their answers. However, developing a well-calibrated confidence estimation model is challenging, as mistakes made by LLMs can be difficult to detect. We propose a novel method combining the LLM's self-consistency with labeled data and training an auxiliary model to estimate the correctness of its responses to questions. This auxiliary model predicts the correctness of responses based solely on their consistent information. To set up the learning problem, we use a weighted graph to represent the consistency among the LLM's multiple responses to a question. Correctness labels are assigned to these responses based on their similarity to the correct answer. We then train a graph neural network to estimate the probability of correct responses. Experiments demonstrate that the proposed approach substantially outperforms several of the most recent methods in confidence calibration across multiple widely adopted benchmark datasets. Furthermore, the proposed approach significantly improves the generalization capability of confidence calibration on out-of-domain (OOD) data.
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Jun 17, 2024



We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.