 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJanus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
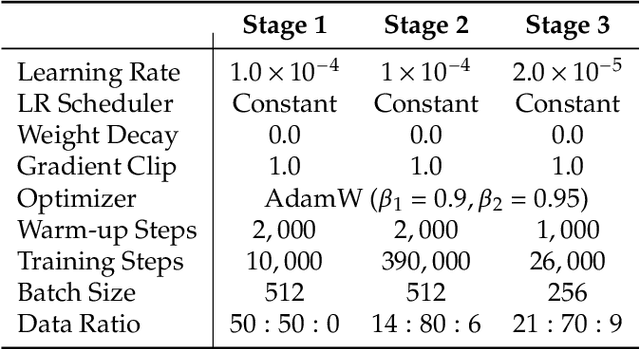
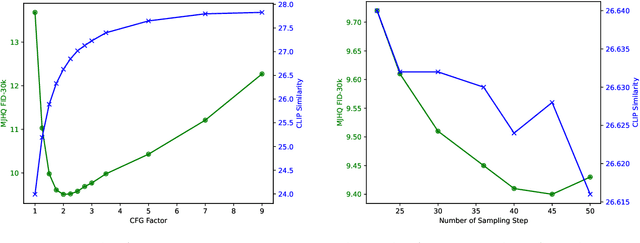
Jan 29, 2025In this work, we introduce Janus-Pro, an advanced version of the previous work Janus. Specifically, Janus-Pro incorporates (1) an optimized training strategy, (2) expanded training data, and (3) scaling to larger model size. With these improvements, Janus-Pro achieves significant advancements in both multimodal understanding and text-to-image instruction-following capabilities, while also enhancing the stability of text-to-image generation. We hope this work will inspire further exploration in the field. Code and models are publicly available.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
Nov 12, 2024

We present JanusFlow, a powerful framework that unifies image understanding and generation in a single model. JanusFlow introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. To further improve the performance of our unified model, we adopt two key strategies: (i) decoupling the understanding and generation encoders, and (ii) aligning their representations during unified training. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Oct 17, 2024



In this paper, we introduce Janus, an autoregressive framework that unifies multimodal understanding and generation. Prior research often relies on a single visual encoder for both tasks, such as Chameleon. However, due to the differing levels of information granularity required by multimodal understanding and generation, this approach can lead to suboptimal performance, particularly in multimodal understanding. To address this issue, we decouple visual encoding into separate pathways, while still leveraging a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder's roles in understanding and generation, but also enhances the framework's flexibility. For instance, both the multimodal understanding and generation components can independently select their most suitable encoding methods. Experiments show that Janus surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.
PaRa: Personalizing Text-to-Image Diffusion via Parameter Rank Reduction
Jun 09, 2024



Personalizing a large-scale pretrained Text-to-Image (T2I) diffusion model is challenging as it typically struggles to make an appropriate trade-off between its training data distribution and the target distribution, i.e., learning a novel concept with only a few target images to achieve personalization (aligning with the personalized target) while preserving text editability (aligning with diverse text prompts). In this paper, we propose PaRa, an effective and efficient Parameter Rank Reduction approach for T2I model personalization by explicitly controlling the rank of the diffusion model parameters to restrict its initial diverse generation space into a small and well-balanced target space. Our design is motivated by the fact that taming a T2I model toward a novel concept such as a specific art style implies a small generation space. To this end, by reducing the rank of model parameters during finetuning, we can effectively constrain the space of the denoising sampling trajectories towards the target. With comprehensive experiments, we show that PaRa achieves great advantages over existing finetuning approaches on single/multi-subject generation as well as single-image editing. Notably, compared to the prevailing fine-tuning technique LoRA, PaRa achieves better parameter efficiency (2x fewer learnable parameters) and much better target image alignment.
MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
May 23, 2024



A critical approach for efficiently deploying computationally demanding large language models (LLMs) is Key-Value (KV) caching. The KV cache stores key-value states of previously generated tokens, significantly reducing the need for repetitive computations and thereby lowering latency in autoregressive generation. However, the size of the KV cache grows linearly with sequence length, posing challenges for applications requiring long context input and extensive sequence generation. In this paper, we present a simple yet effective approach, called MiniCache, to compress the KV cache across layers from a novel depth perspective, significantly reducing the memory footprint for LLM inference. Our approach is based on the observation that KV cache states exhibit high similarity between the adjacent layers in the middle-to-deep portion of LLMs. To facilitate merging, we propose disentangling the states into the magnitude and direction components, interpolating the directions of the state vectors while preserving their lengths unchanged. Furthermore, we introduce a token retention strategy to keep highly distinct state pairs unmerged, thus preserving the information with minimal additional storage overhead. Our MiniCache is training-free and general, complementing existing KV cache compression strategies, such as quantization and sparsity. We conduct a comprehensive evaluation of MiniCache utilizing various models including LLaMA-2, LLaMA-3, Phi-3, Mistral, and Mixtral across multiple benchmarks, demonstrating its exceptional performance in achieving superior compression ratios and high throughput. On the ShareGPT dataset, LLaMA-2-7B with 4-bit MiniCache achieves a remarkable compression ratio of up to 5.02x, enhances inference throughput by approximately 5x, and reduces the memory footprint by 41% compared to the FP16 full cache baseline, all while maintaining near-lossless performance.
T-Stitch: Accelerating Sampling in Pre-Trained Diffusion Models with Trajectory Stitching
Feb 21, 2024



Sampling from diffusion probabilistic models (DPMs) is often expensive for high-quality image generation and typically requires many steps with a large model. In this paper, we introduce sampling Trajectory Stitching T-Stitch, a simple yet efficient technique to improve the sampling efficiency with little or no generation degradation. Instead of solely using a large DPM for the entire sampling trajectory, T-Stitch first leverages a smaller DPM in the initial steps as a cheap drop-in replacement of the larger DPM and switches to the larger DPM at a later stage. Our key insight is that different diffusion models learn similar encodings under the same training data distribution and smaller models are capable of generating good global structures in the early steps. Extensive experiments demonstrate that T-Stitch is training-free, generally applicable for different architectures, and complements most existing fast sampling techniques with flexible speed and quality trade-offs. On DiT-XL, for example, 40% of the early timesteps can be safely replaced with a 10x faster DiT-S without performance drop on class-conditional ImageNet generation. We further show that our method can also be used as a drop-in technique to not only accelerate the popular pretrained stable diffusion (SD) models but also improve the prompt alignment of stylized SD models from the public model zoo. Code is released at https://github.com/NVlabs/T-Stitch
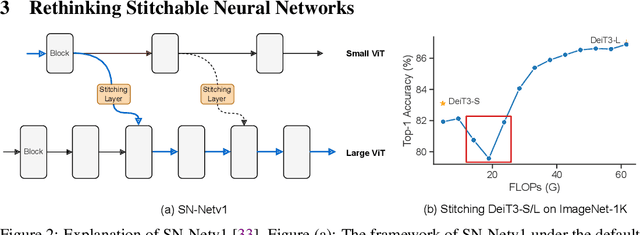
Efficient Stitchable Task Adaptation
Nov 29, 2023The paradigm of pre-training and fine-tuning has laid the foundation for deploying deep learning models. However, most fine-tuning methods are designed to meet a specific resource budget. Recently, considering diverse deployment scenarios with various resource budgets, stitchable neural network (SN-Net) is introduced to quickly obtain numerous new networks (stitches) from the pre-trained models (anchors) in a model family via model stitching. Although promising, SN-Net confronts new challenges when adapting it to new target domains, including huge memory and storage requirements and a long and sub-optimal multistage adaptation process. In this work, we present a novel framework, Efficient Stitchable Task Adaptation (ESTA), to efficiently produce a palette of fine-tuned models that adhere to diverse resource constraints. Specifically, we first tailor parameter-efficient fine-tuning to share low-rank updates among the stitches while maintaining independent bias terms. In this way, we largely reduce fine-tuning memory burdens and mitigate the interference among stitches that arises in task adaptation. Furthermore, we streamline a simple yet effective one-stage deployment pipeline, which estimates the important stitches to deploy with training-time gradient statistics. By assigning higher sampling probabilities to important stitches, we also get a boosted Pareto frontier. Extensive experiments on 25 downstream visual recognition tasks demonstrate that our ESTA is capable of generating stitches with smooth accuracy-efficiency trade-offs and surpasses the direct SN-Net adaptation by remarkable margins with significantly lower training time and fewer trainable parameters. Furthermore, we demonstrate the flexibility and scalability of our ESTA framework by stitching LLMs from LLaMA family, obtaining chatbot stitches of assorted sizes.
Stitched ViTs are Flexible Vision Backbones
Jun 30, 2023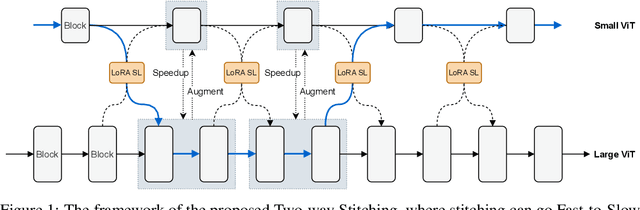


Large pretrained plain vision Transformers (ViTs) have been the workhorse for many downstream tasks. However, existing works utilizing off-the-shelf ViTs are inefficient in terms of training and deployment, because adopting ViTs with individual sizes requires separate training and is restricted by fixed performance-efficiency trade-offs. In this paper, we are inspired by stitchable neural networks, which is a new framework that cheaply produces a single model that covers rich subnetworks by stitching pretrained model families, supporting diverse performance-efficiency trade-offs at runtime. Building upon this foundation, we introduce SN-Netv2, a systematically improved model stitching framework to facilitate downstream task adaptation. Specifically, we first propose a Two-way stitching scheme to enlarge the stitching space. We then design a resource-constrained sampling strategy that takes into account the underlying FLOPs distributions in the space for improved sampling. Finally, we observe that learning stitching layers is a low-rank update, which plays an essential role on downstream tasks to stabilize training and ensure a good Pareto frontier. With extensive experiments on ImageNet-1K, ADE20K, COCO-Stuff-10K, NYUv2 and COCO-2017, SN-Netv2 demonstrates strong ability to serve as a flexible vision backbone, achieving great advantages in both training efficiency and adaptation. Code will be released at https://github.com/ziplab/SN-Netv2.