 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAssets: Generating in-the-wild 3D Assets in Latent Space
Apr 24, 2026High-quality 3D assets for traffic participants are critical for multi-sensor simulation, which is essential for the safe end-to-end development of autonomy. Building assets from in-the-wild data is key for diversity and realism, but existing neural-rendering based reconstruction methods are slow and generate assets that render well only from viewpoints close to the original observations, limiting their usefulness in simulation. Recent diffusion-based generative models build complete and diverse assets, but perform poorly on in-the-wild driving scenes, where observed actors are captured under sparse and limited fields of view, and are partially occluded. In this work, we propose a 3D latent diffusion model that learns on in-the-wild LiDAR and camera data captured by a sensor platform and generates high-quality 3D assets with complete geometry and appearance. Key to our method is a "reconstruct-then-generate" approach that first leverages occlusion-aware neural rendering trained over multiple scenes to build a high-quality latent space for objects, and then trains a diffusion model that operates on the latent space. We show our method outperforms existing reconstruction and generation based methods, unlocking diverse and scalable content creation for simulation.
Can Large Multimodal Models Inspect Buildings? A Hierarchical Benchmark for Structural Pathology Reasoning
Mar 20, 2026Automated building facade inspection is a critical component of urban resilience and smart city maintenance. Traditionally, this field has relied on specialized discriminative models (e.g., YOLO, Mask R-CNN) that excel at pixel-level localization but are constrained to passive perception and worse generization without the visual understandng to interpret structural topology. Large Multimodal Models (LMMs) promise a paradigm shift toward active reasoning, yet their application in such high-stakes engineering domains lacks rigorous evaluation standards. To bridge this gap, we introduce a human-in-the-loop semi-automated annotation framework, leveraging expert-proposal verification to unify 12 fragmented datasets into a standardized, hierarchical ontology. Building on this foundation, we present \textit{DefectBench}, the first multi-dimensional benchmark designed to interrogate LMMs beyond basic semantic recognition. \textit{DefectBench} evaluates 18 state-of-the-art (SOTA) LMMs across three escalating cognitive dimensions: Semantic Perception, Spatial Localization, and Generative Geometry Segmentation. Extensive experiments reveal that while current LMMs demonstrate exceptional topological awareness and semantic understanding (effectively diagnosing "what" and "how"), they exhibit significant deficiencies in metric localization precision ("where"). Crucially, however, we validate the viability of zero-shot generative segmentation, showing that general-purpose foundation models can rival specialized supervised networks without domain-specific training. This work provides both a rigorous benchmarking standard and a high-quality open-source database, establishing a new baseline for the advancement of autonomous AI agents in civil engineering.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
Jan 21, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated significant improvement in offline video understanding. However, extending these capabilities to streaming video inputs, remains challenging, as existing models struggle to simultaneously maintain stable understanding performance, real-time responses, and low GPU memory overhead. To address this challenge, we propose HERMES, a novel training-free architecture for real-time and accurate understanding of video streams. Based on a mechanistic attention investigation, we conceptualize KV cache as a hierarchical memory framework that encapsulates video information across multiple granularities. During inference, HERMES reuses a compact KV cache, enabling efficient streaming understanding under resource constraints. Notably, HERMES requires no auxiliary computations upon the arrival of user queries, thereby guaranteeing real-time responses for continuous video stream interactions, which achieves 10$\times$ faster TTFT compared to prior SOTA. Even when reducing video tokens by up to 68% compared with uniform sampling, HERMES achieves superior or comparable accuracy across all benchmarks, with up to 11.4% gains on streaming datasets.
FGM-HD: Boosting Generation Diversity of Fractal Generative Models through Hausdorff Dimension Induction
Nov 18, 2025Improving the diversity of generated results while maintaining high visual quality remains a significant challenge in image generation tasks. Fractal Generative Models (FGMs) are efficient in generating high-quality images, but their inherent self-similarity limits the diversity of output images. To address this issue, we propose a novel approach based on the Hausdorff Dimension (HD), a widely recognized concept in fractal geometry used to quantify structural complexity, which aids in enhancing the diversity of generated outputs. To incorporate HD into FGM, we propose a learnable HD estimation method that predicts HD directly from image embeddings, addressing computational cost concerns. However, simply introducing HD into a hybrid loss is insufficient to enhance diversity in FGMs due to: 1) degradation of image quality, and 2) limited improvement in generation diversity. To this end, during training, we adopt an HD-based loss with a monotonic momentum-driven scheduling strategy to progressively optimize the hyperparameters, obtaining optimal diversity without sacrificing visual quality. Moreover, during inference, we employ HD-guided rejection sampling to select geometrically richer outputs. Extensive experiments on the ImageNet dataset demonstrate that our FGM-HD framework yields a 39\% improvement in output diversity compared to vanilla FGMs, while preserving comparable image quality. To our knowledge, this is the very first work introducing HD into FGM. Our method effectively enhances the diversity of generated outputs while offering a principled theoretical contribution to FGM development.
MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
Jan 21, 2025



We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
Nov 12, 2024
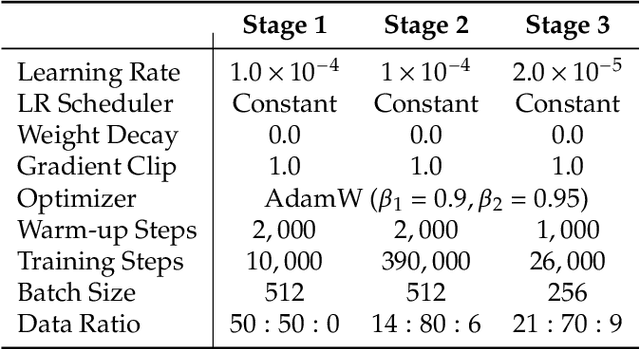

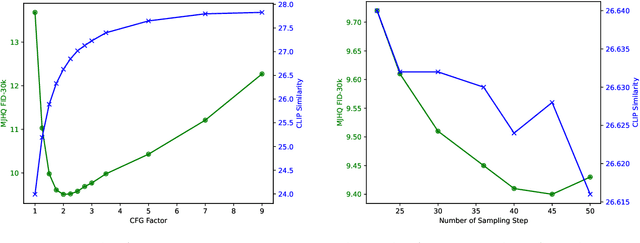
We present JanusFlow, a powerful framework that unifies image understanding and generation in a single model. JanusFlow introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. To further improve the performance of our unified model, we adopt two key strategies: (i) decoupling the understanding and generation encoders, and (ii) aligning their representations during unified training. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.
Visual Question Decomposition on Multimodal Large Language Models
Sep 28, 2024



Question decomposition has emerged as an effective strategy for prompting Large Language Models (LLMs) to answer complex questions. However, while existing methods primarily focus on unimodal language models, the question decomposition capability of Multimodal Large Language Models (MLLMs) has yet to be explored. To this end, this paper explores visual question decomposition on MLLMs. Specifically, we introduce a systematic evaluation framework including a dataset and several evaluation criteria to assess the quality of the decomposed sub-questions, revealing that existing MLLMs struggle to produce high-quality sub-questions. To address this limitation, we propose a specific finetuning dataset, DecoVQA+, for enhancing the model's question decomposition capability. Aiming at enabling models to perform appropriate selective decomposition, we propose an efficient finetuning pipeline. The finetuning pipeline consists of our proposed dataset and a training objective for selective decomposition. Finetuned MLLMs demonstrate significant improvements in the quality of sub-questions and the policy of selective question decomposition. Additionally, the models also achieve higher accuracy with selective decomposition on VQA benchmark datasets.