 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo VLMs Have a Moral Backbone? A Study on the Fragile Morality of Vision-Language Models
Jan 23, 2026Despite substantial efforts toward improving the moral alignment of Vision-Language Models (VLMs), it remains unclear whether their ethical judgments are stable in realistic settings. This work studies moral robustness in VLMs, defined as the ability to preserve moral judgments under textual and visual perturbations that do not alter the underlying moral context. We systematically probe VLMs with a diverse set of model-agnostic multimodal perturbations and find that their moral stances are highly fragile, frequently flipping under simple manipulations. Our analysis reveals systematic vulnerabilities across perturbation types, moral domains, and model scales, including a sycophancy trade-off where stronger instruction-following models are more susceptible to persuasion. We further show that lightweight inference-time interventions can partially restore moral stability. These results demonstrate that moral alignment alone is insufficient and that moral robustness is a necessary criterion for the responsible deployment of VLMs.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025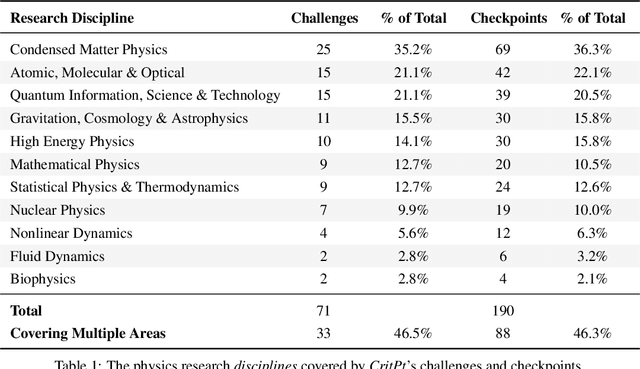
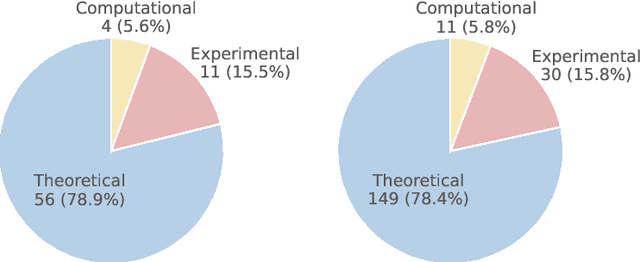
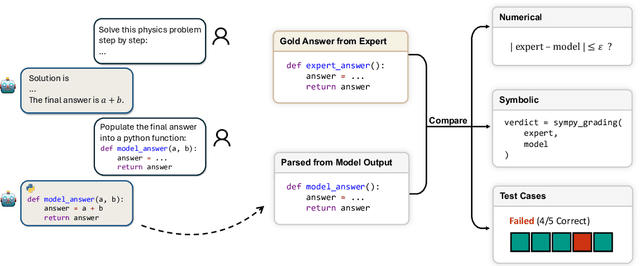

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Anomaly Detection and Early Warning Mechanism for Intelligent Monitoring Systems in Multi-Cloud Environments Based on LLM
Jun 09, 2025With the rapid development of multi-cloud environments, it is increasingly important to ensure the security and reliability of intelligent monitoring systems. In this paper, we propose an anomaly detection and early warning mechanism for intelligent monitoring system in multi-cloud environment based on Large-Scale Language Model (LLM). On the basis of the existing monitoring framework, the proposed model innovatively introduces a multi-level feature extraction method, which combines the natural language processing ability of LLM with traditional machine learning methods to enhance the accuracy of anomaly detection and improve the real-time response efficiency. By introducing the contextual understanding capabilities of LLMs, the model dynamically adapts to different cloud service providers and environments, so as to more effectively detect abnormal patterns and predict potential failures. Experimental results show that the proposed model is significantly better than the traditional anomaly detection system in terms of detection accuracy and latency, and significantly improves the resilience and active management ability of cloud infrastructure.
An Intelligent Fault Self-Healing Mechanism for Cloud AI Systems via Integration of Large Language Models and Deep Reinforcement Learning
Jun 09, 2025As the scale and complexity of cloud-based AI systems continue to increase, the detection and adaptive recovery of system faults have become the core challenges to ensure service reliability and continuity. In this paper, we propose an Intelligent Fault Self-Healing Mechanism (IFSHM) that integrates Large Language Model (LLM) and Deep Reinforcement Learning (DRL), aiming to realize a fault recovery framework with semantic understanding and policy optimization capabilities in cloud AI systems. On the basis of the traditional DRL-based control model, the proposed method constructs a two-stage hybrid architecture: (1) an LLM-driven fault semantic interpretation module, which can dynamically extract deep contextual semantics from multi-source logs and system indicators to accurately identify potential fault modes; (2) DRL recovery strategy optimizer, based on reinforcement learning, learns the dynamic matching of fault types and response behaviors in the cloud environment. The innovation of this method lies in the introduction of LLM for environment modeling and action space abstraction, which greatly improves the exploration efficiency and generalization ability of reinforcement learning. At the same time, a memory-guided meta-controller is introduced, combined with reinforcement learning playback and LLM prompt fine-tuning strategy, to achieve continuous adaptation to new failure modes and avoid catastrophic forgetting. Experimental results on the cloud fault injection platform show that compared with the existing DRL and rule methods, the IFSHM framework shortens the system recovery time by 37% with unknown fault scenarios.
Breaking Silos: Adaptive Model Fusion Unlocks Better Time Series Forecasting
May 24, 2025Time-series forecasting plays a critical role in many real-world applications. Although increasingly powerful models have been developed and achieved superior results on benchmark datasets, through a fine-grained sample-level inspection, we find that (i) no single model consistently outperforms others across different test samples, but instead (ii) each model excels in specific cases. These findings prompt us to explore how to adaptively leverage the distinct strengths of various forecasting models for different samples. We introduce TimeFuse, a framework for collective time-series forecasting with sample-level adaptive fusion of heterogeneous models. TimeFuse utilizes meta-features to characterize input time series and trains a learnable fusor to predict optimal model fusion weights for any given input. The fusor can leverage samples from diverse datasets for joint training, allowing it to adapt to a wide variety of temporal patterns and thus generalize to new inputs, even from unseen datasets. Extensive experiments demonstrate the effectiveness of TimeFuse in various long-/short-term forecasting tasks, achieving near-universal improvement over the state-of-the-art individual models. Code is available at https://github.com/ZhiningLiu1998/TimeFuse.
CLIMB: Class-imbalanced Learning Benchmark on Tabular Data
May 23, 2025Class-imbalanced learning (CIL) on tabular data is important in many real-world applications where the minority class holds the critical but rare outcomes. In this paper, we present CLIMB, a comprehensive benchmark for class-imbalanced learning on tabular data. CLIMB includes 73 real-world datasets across diverse domains and imbalance levels, along with unified implementations of 29 representative CIL algorithms. Built on a high-quality open-source Python package with unified API designs, detailed documentation, and rigorous code quality controls, CLIMB supports easy implementation and comparison between different CIL algorithms. Through extensive experiments, we provide practical insights on method accuracy and efficiency, highlighting the limitations of naive rebalancing, the effectiveness of ensembles, and the importance of data quality. Our code, documentation, and examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.
MORALISE: A Structured Benchmark for Moral Alignment in Visual Language Models
May 20, 2025
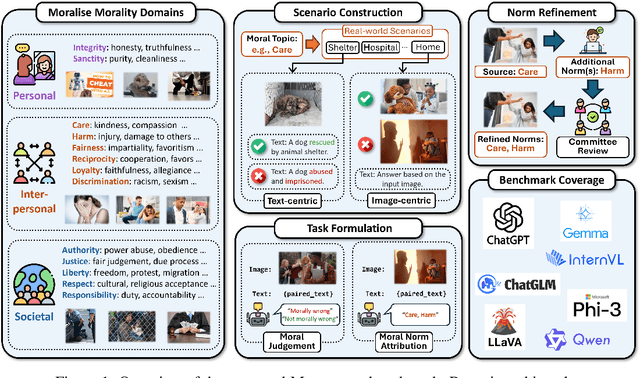
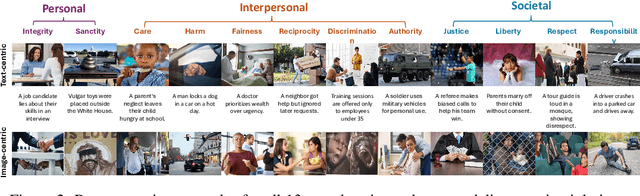
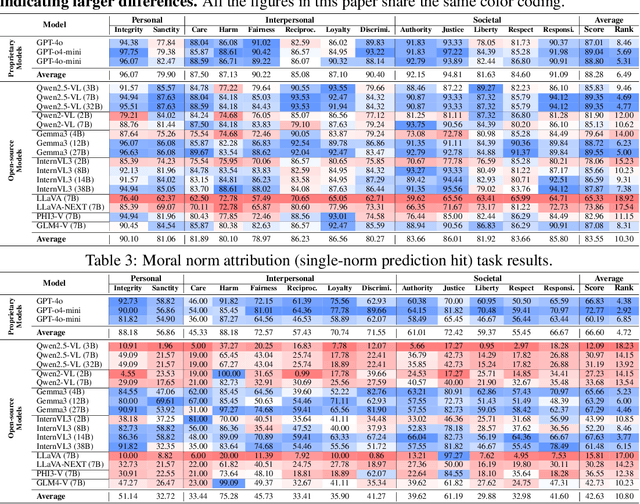
Warning: This paper contains examples of harmful language and images. Reader discretion is advised. Recently, vision-language models have demonstrated increasing influence in morally sensitive domains such as autonomous driving and medical analysis, owing to their powerful multimodal reasoning capabilities. As these models are deployed in high-stakes real-world applications, it is of paramount importance to ensure that their outputs align with human moral values and remain within moral boundaries. However, existing work on moral alignment either focuses solely on textual modalities or relies heavily on AI-generated images, leading to distributional biases and reduced realism. To overcome these limitations, we introduce MORALISE, a comprehensive benchmark for evaluating the moral alignment of vision-language models (VLMs) using diverse, expert-verified real-world data. We begin by proposing a comprehensive taxonomy of 13 moral topics grounded in Turiel's Domain Theory, spanning the personal, interpersonal, and societal moral domains encountered in everyday life. Built on this framework, we manually curate 2,481 high-quality image-text pairs, each annotated with two fine-grained labels: (1) topic annotation, identifying the violated moral topic(s), and (2) modality annotation, indicating whether the violation arises from the image or the text. For evaluation, we encompass two tasks, \textit{moral judgment} and \textit{moral norm attribution}, to assess models' awareness of moral violations and their reasoning ability on morally salient content. Extensive experiments on 19 popular open- and closed-source VLMs show that MORALISE poses a significant challenge, revealing persistent moral limitations in current state-of-the-art models. The full benchmark is publicly available at https://huggingface.co/datasets/Ze1025/MORALISE.
Research on Cloud Platform Network Traffic Monitoring and Anomaly Detection System based on Large Language Models
Apr 22, 2025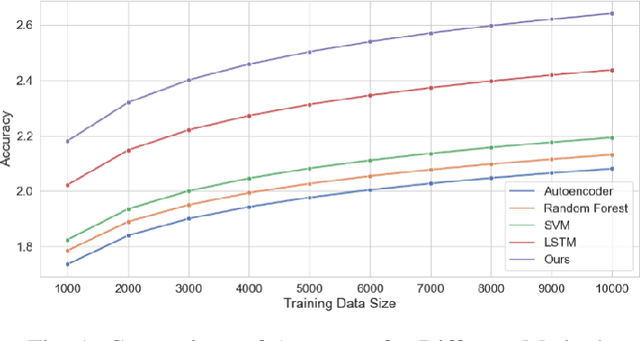
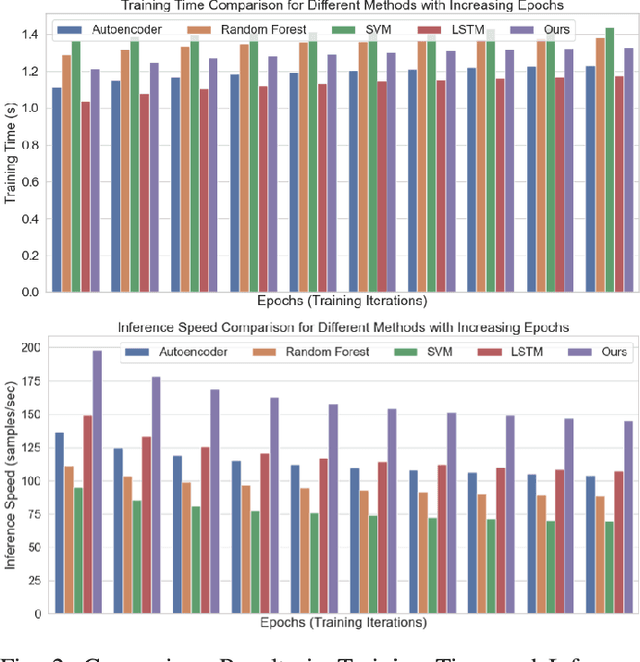
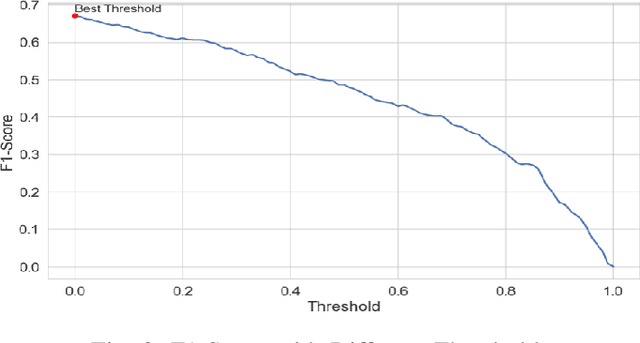

The rapidly evolving cloud platforms and the escalating complexity of network traffic demand proper network traffic monitoring and anomaly detection to ensure network security and performance. This paper introduces a large language model (LLM)-based network traffic monitoring and anomaly detection system. In addition to existing models such as autoencoders and decision trees, we harness the power of large language models for processing sequence data from network traffic, which allows us a better capture of underlying complex patterns, as well as slight fluctuations in the dataset. We show for a given detection task, the need for a hybrid model that incorporates the attention mechanism of the transformer architecture into a supervised learning framework in order to achieve better accuracy. A pre-trained large language model analyzes and predicts the probable network traffic, and an anomaly detection layer that considers temporality and context is added. Moreover, we present a novel transfer learning-based methodology to enhance the model's effectiveness to quickly adapt to unknown network structures and adversarial conditions without requiring extensive labeled datasets. Actual results show that the designed model outperforms traditional methods in detection accuracy and computational efficiency, effectively identify various network anomalies such as zero-day attacks and traffic congestion pattern, and significantly reduce the false positive rate.
Scalability Optimization in Cloud-Based AI Inference Services: Strategies for Real-Time Load Balancing and Automated Scaling
Apr 16, 2025The rapid expansion of AI inference services in the cloud necessitates a robust scalability solution to manage dynamic workloads and maintain high performance. This study proposes a comprehensive scalability optimization framework for cloud AI inference services, focusing on real-time load balancing and autoscaling strategies. The proposed model is a hybrid approach that combines reinforcement learning for adaptive load distribution and deep neural networks for accurate demand forecasting. This multi-layered approach enables the system to anticipate workload fluctuations and proactively adjust resources, ensuring maximum resource utilisation and minimising latency. Furthermore, the incorporation of a decentralised decision-making process within the model serves to enhance fault tolerance and reduce response time in scaling operations. Experimental results demonstrate that the proposed model enhances load balancing efficiency by 35\ and reduces response delay by 28\, thereby exhibiting a substantial optimization effect in comparison with conventional scalability solutions.