 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal CT Representations from Anatomy to Disease Phenotype through Agglomerative Pretraining
May 21, 2026Computed tomography (CT) is a central to three-dimensional medical imaging, yet CT-based artificial intelligence remains fragmented across task-specific models for segmentation, classification, registration, and report analysis. Here we present FlexiCT, a family of CT foundation models trained by agglomerative continual pretraining on 266,227 CT volumes from 56 publicly available datasets, forming a large-scale public resource for CT representation learning. FlexiCT uses agglomerative pretraining across three stages: two-dimensional axial pretraining, three-dimensional anatomical pretraining and report-guided semantic alignment. This training strategy supports slice-level, volume-level and vision-language analysis. Across five downstream task families (segmentation, classification, registration, vision-language understanding and clinical retrieval), FlexiCT matches or exceeds prior task-specific approaches on multiple benchmarks. Its embeddings further organize CT scans along gradients associated with various tumor stages, suggesting that CT foundation models can capture imaging features relevant to disease phenotype characterization. Code is available at https://github.com/ricklisz/FlexiCT
MedLVR: Latent Visual Reasoning for Reliable Medical Visual Question Answering
Apr 10, 2026Medical vision--language models (VLMs) have shown strong potential for medical visual question answering (VQA), yet their reasoning remains largely text-centric: images are encoded once as static context, and subsequent inference is dominated by language. This paradigm is fundamentally limited in clinical scenarios, where accurate answers often depend on subtle, localized visual evidence that cannot be reliably preserved in static embeddings. We propose \textsc{MedLVR}, a latent visual reasoning framework that introduces an explicit visual evidence state into autoregressive decoding. Instead of relying solely on text-based intermediate reasoning, \textsc{MedLVR} interleaves a short latent reasoning segment within the decoder by reusing hidden states as continuous latent steps, enabling iterative preservation and refinement of query-relevant visual evidence before answer generation. To support effective visual supervision, we adopt a two-stage training strategy: region of interest (ROI)-supervised fine-tuning aligns latent states with clinically relevant image evidence, and Visual-Latent Policy Optimization (VLPO) further optimizes latent reasoning and answer generation under outcome-level rewards. Experiments on OmniMedVQA and five external medical VQA benchmarks show that \textsc{MedLVR} consistently outperforms recent reasoning baselines and improves the average score over the Qwen2.5-VL-7B backbone from 48.3\% to 53.4\%. These results show that latent visual reasoning provides an effective mechanism for preserving diagnostically relevant visual evidence and improving the reliability of medical VQA.
Distilling Photon-Counting CT into Routine Chest CT through Clinically Validated Degradation Modeling
Apr 08, 2026Photon-counting CT (PCCT) provides superior image quality with higher spatial resolution and lower noise compared to conventional energy-integrating CT (EICT), but its limited clinical availability restricts large-scale research and clinical deployment. To bridge this gap, we propose SUMI, a simulated degradation-to-enhancement method that learns to reverse realistic acquisition artifacts in low-quality EICT by leveraging high-quality PCCT as reference. Our central insight is to explicitly model realistic acquisition degradations, transforming PCCT into clinically plausible lower-quality counterparts and learning to invert this process. The simulated degradations were validated for clinical realism by board-certified radiologists, enabling faithful supervision without requiring paired acquisitions at scale. As outcomes of this technical contribution, we: (1) train a latent diffusion model on 1,046 PCCTs, using an autoencoder first pre-trained on both these PCCTs and 405,379 EICTs from 145 hospitals to extract general CT latent features that we release for reuse in other generative medical imaging tasks; (2) construct a large-scale dataset of over 17,316 publicly available EICTs enhanced to PCCT-like quality, with radiologist-validated voxel-wise annotations of airway trees, arteries, veins, lungs, and lobes; and (3) demonstrate substantial improvements: across external data, SUMI outperforms state-of-the-art image translation methods by 15% in SSIM and 20% in PSNR, improves radiologist-rated clinical utility in reader studies, and enhances downstream top-ranking lesion detection performance, increasing sensitivity by up to 15% and F1 score by up to 10%. Our results suggest that emerging imaging advances can be systematically distilled into routine EICT using limited high-quality scans as reference.
Evaluating GPT-5 as a Multimodal Clinical Reasoner: A Landscape Commentary
Mar 05, 2026The transition from task-specific artificial intelligence toward general-purpose foundation models raises fundamental questions about their capacity to support the integrated reasoning required in clinical medicine, where diagnosis demands synthesis of ambiguous patient narratives, laboratory data, and multimodal imaging. This landscape commentary provides the first controlled, cross-sectional evaluation of the GPT-5 family (GPT-5, GPT-5 Mini, GPT-5 Nano) against its predecessor GPT-4o across a diverse spectrum of clinically grounded tasks, including medical education examinations, text-based reasoning benchmarks, and visual question-answering in neuroradiology, digital pathology, and mammography using a standardized zero-shot chain-of-thought protocol. GPT-5 demonstrated substantial gains in expert-level textual reasoning, with absolute improvements exceeding 25 percentage-points on MedXpertQA. When tasked with multimodal synthesis, GPT-5 effectively leveraged this enhanced reasoning capacity to ground uncertain clinical narratives in concrete imaging evidence, achieving state-of-the-art or competitive performance across most VQA benchmarks and outperforming GPT-4o by margins of 10-40% in mammography tasks requiring fine-grained lesion characterization. However, performance remained moderate in neuroradiology (44% macro-average accuracy) and lagged behind domain-specific models in mammography, where specialized systems exceed 80% accuracy compared to GPT-5's 52-64%. These findings indicate that while GPT-5 represents a meaningful advance toward integrated multimodal clinical reasoning, mirroring the clinician's cognitive process of biasing uncertain information with objective findings, generalist models are not yet substitutes for purpose-built systems in highly specialized, perception-critical tasks.
IPEC: Test-Time Incremental Prototype Enhancement Classifier for Few-Shot Learning
Jan 16, 2026Metric-based few-shot approaches have gained significant popularity due to their relatively straightforward implementation, high interpret ability, and computational efficiency. However, stemming from the batch-independence assumption during testing, which prevents the model from leveraging valuable knowledge accumulated from previous batches. To address these challenges, we propose a novel test-time method called Incremental Prototype Enhancement Classifier (IPEC), a test-time method that optimizes prototype estimation by leveraging information from previous query samples. IPEC maintains a dynamic auxiliary set by selectively incorporating query samples that are classified with high confidence. To ensure sample quality, we design a robust dual-filtering mechanism that assesses each query sample based on both global prediction confidence and local discriminative ability. By aggregating this auxiliary set with the support set in subsequent tasks, IPEC builds progressively more stable and representative prototypes, effectively reducing its reliance on the initial support set. We ground this approach in a Bayesian interpretation, conceptualizing the support set as a prior and the auxiliary set as a data-driven posterior, which in turn motivates the design of a practical "warm-up and test" two-stage inference protocol. Extensive empirical results validate the superior performance of our proposed method across multiple few-shot classification tasks.
InfoSculpt: Sculpting the Latent Space for Generalized Category Discovery
Jan 15, 2026Generalized Category Discovery (GCD) aims to classify instances from both known and novel categories within a large-scale unlabeled dataset, a critical yet challenging task for real-world, open-world applications. However, existing methods often rely on pseudo-labeling, or two-stage clustering, which lack a principled mechanism to explicitly disentangle essential, category-defining signals from instance-specific noise. In this paper, we address this fundamental limitation by re-framing GCD from an information-theoretic perspective, grounded in the Information Bottleneck (IB) principle. We introduce InfoSculpt, a novel framework that systematically sculpts the representation space by minimizing a dual Conditional Mutual Information (CMI) objective. InfoSculpt uniquely combines a Category-Level CMI on labeled data to learn compact and discriminative representations for known classes, and a complementary Instance-Level CMI on all data to distill invariant features by compressing augmentation-induced noise. These two objectives work synergistically at different scales to produce a disentangled and robust latent space where categorical information is preserved while noisy, instance-specific details are discarded. Extensive experiments on 8 benchmarks demonstrate that InfoSculpt validating the effectiveness of our information-theoretic approach.
Beyond Single Prompts: Synergistic Fusion and Arrangement for VICL
Jan 15, 2026Vision In-Context Learning (VICL) enables inpainting models to quickly adapt to new visual tasks from only a few prompts. However, existing methods suffer from two key issues: (1) selecting only the most similar prompt discards complementary cues from other high-quality prompts; and (2) failing to exploit the structured information implied by different prompt arrangements. We propose an end-to-end VICL framework to overcome these limitations. Firstly, an adaptive Fusion Module aggregates critical patterns and annotations from multiple prompts to form more precise contextual prompts. Secondly, we introduce arrangement-specific lightweight MLPs to decouple layout priors from the core model, while minimally affecting the overall model. In addition, an bidirectional fine-tuning mechanism swaps the roles of query and prompt, encouraging the model to reconstruct the original prompt from fused context and thus enhancing collaboration between the fusion module and the inpainting model. Experiments on foreground segmentation, single-object detection, and image colorization demonstrate superior results and strong cross-task generalization of our method.
Enhancing Visual In-Context Learning by Multi-Faceted Fusion
Jan 15, 2026Visual In-Context Learning (VICL) has emerged as a powerful paradigm, enabling models to perform novel visual tasks by learning from in-context examples. The dominant "retrieve-then-prompt" approach typically relies on selecting the single best visual prompt, a practice that often discards valuable contextual information from other suitable candidates. While recent work has explored fusing the top-K prompts into a single, enhanced representation, this still simply collapses multiple rich signals into one, limiting the model's reasoning capability. We argue that a more multi-faceted, collaborative fusion is required to unlock the full potential of these diverse contexts. To address this limitation, we introduce a novel framework that moves beyond single-prompt fusion towards an multi-combination collaborative fusion. Instead of collapsing multiple prompts into one, our method generates three contextual representation branches, each formed by integrating information from different combinations of top-quality prompts. These complementary guidance signals are then fed into proposed MULTI-VQGAN architecture, which is designed to jointly interpret and utilize collaborative information from multiple sources. Extensive experiments on diverse tasks, including foreground segmentation, single-object detection, and image colorization, highlight its strong cross-task generalization, effective contextual fusion, and ability to produce more robust and accurate predictions than existing methods.
Efficient Vision Mamba for MRI Super-Resolution via Hybrid Selective Scanning
Dec 22, 2025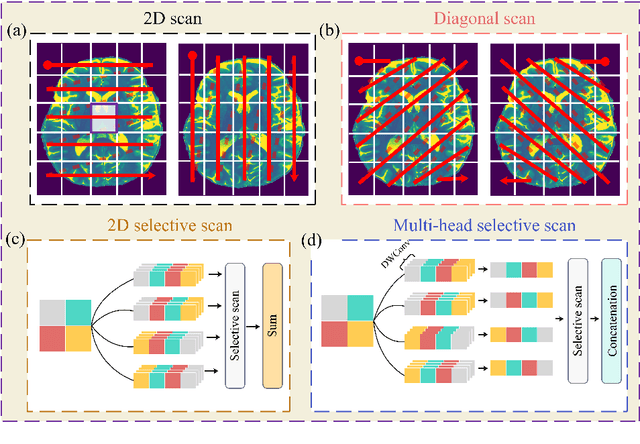
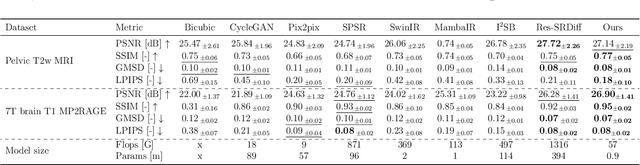
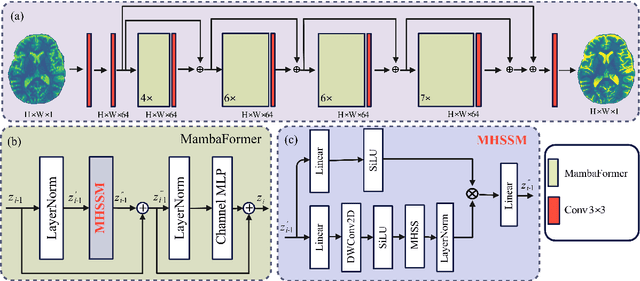

Background: High-resolution MRI is critical for diagnosis, but long acquisition times limit clinical use. Super-resolution (SR) can enhance resolution post-scan, yet existing deep learning methods face fidelity-efficiency trade-offs. Purpose: To develop a computationally efficient and accurate deep learning framework for MRI SR that preserves anatomical detail for clinical integration. Materials and Methods: We propose a novel SR framework combining multi-head selective state-space models (MHSSM) with a lightweight channel MLP. The model uses 2D patch extraction with hybrid scanning to capture long-range dependencies. Each MambaFormer block integrates MHSSM, depthwise convolutions, and gated channel mixing. Evaluation used 7T brain T1 MP2RAGE maps (n=142) and 1.5T prostate T2w MRI (n=334). Comparisons included Bicubic interpolation, GANs (CycleGAN, Pix2pix, SPSR), transformers (SwinIR), Mamba (MambaIR), and diffusion models (I2SB, Res-SRDiff). Results: Our model achieved superior performance with exceptional efficiency. For 7T brain data: SSIM=0.951+-0.021, PSNR=26.90+-1.41 dB, LPIPS=0.076+-0.022, GMSD=0.083+-0.017, significantly outperforming all baselines (p<0.001). For prostate data: SSIM=0.770+-0.049, PSNR=27.15+-2.19 dB, LPIPS=0.190+-0.095, GMSD=0.087+-0.013. The framework used only 0.9M parameters and 57 GFLOPs, reducing parameters by 99.8% and computation by 97.5% versus Res-SRDiff, while outperforming SwinIR and MambaIR in accuracy and efficiency. Conclusion: The proposed framework provides an efficient, accurate MRI SR solution, delivering enhanced anatomical detail across datasets. Its low computational demand and state-of-the-art performance show strong potential for clinical translation.
MeCaMIL: Causality-Aware Multiple Instance Learning for Fair and Interpretable Whole Slide Image Diagnosis
Nov 14, 2025Multiple instance learning (MIL) has emerged as the dominant paradigm for whole slide image (WSI) analysis in computational pathology, achieving strong diagnostic performance through patch-level feature aggregation. However, existing MIL methods face critical limitations: (1) they rely on attention mechanisms that lack causal interpretability, and (2) they fail to integrate patient demographics (age, gender, race), leading to fairness concerns across diverse populations. These shortcomings hinder clinical translation, where algorithmic bias can exacerbate health disparities. We introduce \textbf{MeCaMIL}, a causality-aware MIL framework that explicitly models demographic confounders through structured causal graphs. Unlike prior approaches treating demographics as auxiliary features, MeCaMIL employs principled causal inference -- leveraging do-calculus and collider structures -- to disentangle disease-relevant signals from spurious demographic correlations. Extensive evaluation on three benchmarks demonstrates state-of-the-art performance across CAMELYON16 (ACC/AUC/F1: 0.939/0.983/0.946), TCGA-Lung (0.935/0.979/0.931), and TCGA-Multi (0.977/0.993/0.970, five cancer types). Critically, MeCaMIL achieves superior fairness -- demographic disparity variance drops by over 65% relative reduction on average across attributes, with notable improvements for underserved populations. The framework generalizes to survival prediction (mean C-index: 0.653, +0.017 over best baseline across five cancer types). Ablation studies confirm causal graph structure is essential -- alternative designs yield 0.048 lower accuracy and 4.2x times worse fairness. These results establish MeCaMIL as a principled framework for fair, interpretable, and clinically actionable AI in digital pathology. Code will be released upon acceptance.