 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDWM: Towards a Unified Driving World Model via Multifaceted Representation Learning
Feb 02, 2026Achieving reliable and efficient planning in complex driving environments requires a model that can reason over the scene's geometry, appearance, and dynamics. We present UniDWM, a unified driving world model that advances autonomous driving through multifaceted representation learning. UniDWM constructs a structure- and dynamic-aware latent world representation that serves as a physically grounded state space, enabling consistent reasoning across perception, prediction, and planning. Specifically, a joint reconstruction pathway learns to recover the scene's structure, including geometry and visual texture, while a collaborative generation framework leverages a conditional diffusion transformer to forecast future world evolution within the latent space. Furthermore, we show that our UniDWM can be deemed as a variation of VAE, which provides theoretical guidance for the multifaceted representation learning. Extensive experiments demonstrate the effectiveness of UniDWM in trajectory planning, 4D reconstruction and generation, highlighting the potential of multifaceted world representations as a foundation for unified driving intelligence. The code will be publicly available at https://github.com/Say2L/UniDWM.
Cooperative Double IRS aided Secure Communication for MIMO-OFDM Systems
Jan 27, 2026Cooperative double intelligent reflecting surface (double-IRS) has emerged as a promising approach for enhancing physical layer security (PLS) in MIMO systems. However, existing studies are limited to narrowband scenarios and fail to address wideband MIMO-OFDM. In this regime, frequency-flat IRS phases and cascaded IRS links cause severe coupling, rendering narrowband designs inapplicable. To overcome this challenge, we introduce cooperative double-IRS-assisted wideband MIMO-OFDM and propose an efficient manifold-based solution. By regarding the power and constant modulus constraints as Riemannian manifolds, we reformulate the non-convex secrecy sum rate maximization as an unconstrained optimization on a product manifold. Building on this formulation, we further develop a product Riemannian gradient descent (PRGD) algorithm with guaranteed stationary convergence. Simulation results demonstrate that the proposed scheme effectively resolves the OFDM coupling issue and achieves significant secrecy rate gains, outperforming single-IRS and distributed multi-IRS benchmarks by 32.0% and 22.3%, respectively.
Pairing-free Group-level Knowledge Distillation for Robust Gastrointestinal Lesion Classification in White-Light Endoscopy
Jan 14, 2026White-Light Imaging (WLI) is the standard for endoscopic cancer screening, but Narrow-Band Imaging (NBI) offers superior diagnostic details. A key challenge is transferring knowledge from NBI to enhance WLI-only models, yet existing methods are critically hampered by their reliance on paired NBI-WLI images of the same lesion, a costly and often impractical requirement that leaves vast amounts of clinical data untapped. In this paper, we break this paradigm by introducing PaGKD, a novel Pairing-free Group-level Knowledge Distillation framework that that enables effective cross-modal learning using unpaired WLI and NBI data. Instead of forcing alignment between individual, often semantically mismatched image instances, PaGKD operates at the group level to distill more complete and compatible knowledge across modalities. Central to PaGKD are two complementary modules: (1) Group-level Prototype Distillation (GKD-Pro) distills compact group representations by extracting modality-invariant semantic prototypes via shared lesion-aware queries; (2) Group-level Dense Distillation (GKD-Den) performs dense cross-modal alignment by guiding group-aware attention with activation-derived relation maps. Together, these modules enforce global semantic consistency and local structural coherence without requiring image-level correspondence. Extensive experiments on four clinical datasets demonstrate that PaGKD consistently and significantly outperforms state-of-the-art methods, achieving relative AUC improvements of 3.3%, 1.1%, 2.8%, and 3.2%, respectively, establishing a new direction for cross-modal learning from unpaired data.
From Understanding to Engagement: Personalized pharmacy Video Clips via Vision Language Models (VLMs)
Jan 08, 2026Vision Language Models (VLMs) are poised to revolutionize the digital transformation of pharmacyceutical industry by enabling intelligent, scalable, and automated multi-modality content processing. Traditional manual annotation of heterogeneous data modalities (text, images, video, audio, and web links), is prone to inconsistencies, quality degradation, and inefficiencies in content utilization. The sheer volume of long video and audio data further exacerbates these challenges, (e.g. long clinical trial interviews and educational seminars). Here, we introduce a domain adapted Video to Video Clip Generation framework that integrates Audio Language Models (ALMs) and Vision Language Models (VLMs) to produce highlight clips. Our contributions are threefold: (i) a reproducible Cut & Merge algorithm with fade in/out and timestamp normalization, ensuring smooth transitions and audio/visual alignment; (ii) a personalization mechanism based on role definition and prompt injection for tailored outputs (marketing, training, regulatory); (iii) a cost efficient e2e pipeline strategy balancing ALM/VLM enhanced processing. Evaluations on Video MME benchmark (900) and our proprietary dataset of 16,159 pharmacy videos across 14 disease areas demonstrate 3 to 4 times speedup, 4 times cost reduction, and competitive clip quality. Beyond efficiency gains, we also report our methods improved clip coherence scores (0.348) and informativeness scores (0.721) over state of the art VLM baselines (e.g., Gemini 2.5 Pro), highlighting the potential of transparent, custom extractive, and compliance supporting video summarization for life sciences.
Scaling Vision Language Models for Pharmaceutical Long Form Video Reasoning on Industrial GenAI Platform
Jan 08, 2026Vision Language Models (VLMs) have shown strong performance on multimodal reasoning tasks, yet most evaluations focus on short videos and assume unconstrained computational resources. In industrial settings such as pharmaceutical content understanding, practitioners must process long-form videos under strict GPU, latency, and cost constraints, where many existing approaches fail to scale. In this work, we present an industrial GenAI framework that processes over 200,000 PDFs, 25,326 videos across eight formats (e.g., MP4, M4V, etc.), and 888 multilingual audio files in more than 20 languages. Our study makes three contributions: (i) an industrial large-scale architecture for multimodal reasoning in pharmaceutical domains; (ii) empirical analysis of over 40 VLMs on two leading benchmarks (Video-MME and MMBench) and proprietary dataset of 25,326 videos across 14 disease areas; and (iii) four findings relevant to long-form video reasoning: the role of multimodality, attention mechanism trade-offs, temporal reasoning limits, and challenges of video splitting under GPU constraints. Results show 3-8 times efficiency gains with SDPA attention on commodity GPUs, multimodality improving up to 8/12 task domains (especially length-dependent tasks), and clear bottlenecks in temporal alignment and keyframe detection across open- and closed-source VLMs. Rather than proposing a new "A+B" model, this paper characterizes practical limits, trade-offs, and failure patterns of current VLMs under realistic deployment constraints, and provide actionable guidance for both researchers and practitioners designing scalable multimodal systems for long-form video understanding in industrial domains.
Deep Deterministic Nonlinear ICA via Total Correlation Minimization with Matrix-Based Entropy Functional
Dec 31, 2025Blind source separation, particularly through independent component analysis (ICA), is widely utilized across various signal processing domains for disentangling underlying components from observed mixed signals, owing to its fully data-driven nature that minimizes reliance on prior assumptions. However, conventional ICA methods rely on an assumption of linear mixing, limiting their ability to capture complex nonlinear relationships and to maintain robustness in noisy environments. In this work, we present deep deterministic nonlinear independent component analysis (DDICA), a novel deep neural network-based framework designed to address these limitations. DDICA leverages a matrix-based entropy function to directly optimize the independence criterion via stochastic gradient descent, bypassing the need for variational approximations or adversarial schemes. This results in a streamlined training process and improved resilience to noise. We validated the effectiveness and generalizability of DDICA across a range of applications, including simulated signal mixtures, hyperspectral image unmixing, modeling of primary visual receptive fields, and resting-state functional magnetic resonance imaging (fMRI) data analysis. Experimental results demonstrate that DDICA effectively separates independent components with high accuracy across a range of applications. These findings suggest that DDICA offers a robust and versatile solution for blind source separation in diverse signal processing tasks.
Exploiting Radio Frequency Fingerprints for Device Identification: Tackling Cross-receiver Challenges in the Source-data-free Scenario
Dec 18, 2025With the rapid proliferation of edge computing, Radio Frequency Fingerprint Identification (RFFI) has become increasingly important for secure device authentication. However, practical deployment of deep learning-based RFFI models is hindered by a critical challenge: their performance often degrades significantly when applied across receivers with different hardware characteristics due to distribution shifts introduced by receiver variation. To address this, we investigate the source-data-free cross-receiver RFFI (SCRFFI) problem, where a model pretrained on labeled signals from a source receiver must adapt to unlabeled signals from a target receiver, without access to any source-domain data during adaptation. We first formulate a novel constrained pseudo-labeling-based SCRFFI adaptation framework, and provide a theoretical analysis of its generalization performance. Our analysis highlights a key insight: the target-domain performance is highly sensitive to the quality of the pseudo-labels generated during adaptation. Motivated by this, we propose Momentum Soft pseudo-label Source Hypothesis Transfer (MS-SHOT), a new method for SCRFFI that incorporates momentum-center-guided soft pseudo-labeling and enforces global structural constraints to encourage confident and diverse predictions. Notably, MS-SHOT effectively addresses scenarios involving label shift or unknown, non-uniform class distributions in the target domain -- a significant limitation of prior methods. Extensive experiments on real-world datasets demonstrate that MS-SHOT consistently outperforms existing approaches in both accuracy and robustness, offering a practical and scalable solution for source-data-free cross-receiver adaptation in RFFI.
Joint Analog Beamforming and Antenna Position Design for Secure Communication systems With Movable Antennas
Nov 19, 2025Movable antennas (MA) are a novel technology that allows for the flexible adjustment of antenna positions within a specified region, thereby enhancing the performance of wireless communication systems. In this paper, we explore the use of MA to improve physical layer security in an analog beamforming (AB) communication system. Our goal is to maximize the secrecy rate by jointly optimizing the transmit AB and MA position, subject to constant modulus (CM) constraints on the AB and position constraints for the MA. The resulting problem is non-convex, and we propose a penalty product manifold (PPM) method to solve it efficiently. Specifically, we convert the inequality constraints related to MA position into a penalty function using smoothing techniques, thereby reformulating the problem as an unconstrained optimization on the product manifold space (PMS). We then derive a parallel conjugate gradient descent (PCGD) algorithm to update both the AB and MA position on the PMS. This method is efficient, providing an analytical solution at each step and ensuring convergence to a KKT point. Simulation results show that the MA system achieves a higher secrecy rate than systems with fixed-position antennas.
Enhancing Physical Layer Security in MIMO Systems Assisted by Beyond-Diagonal Reconfigurable Intelligent Surfaces
Nov 19, 2025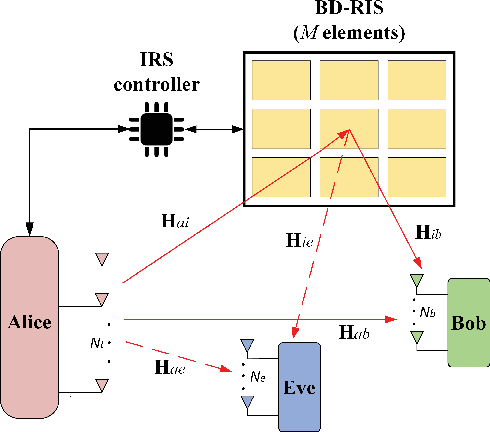
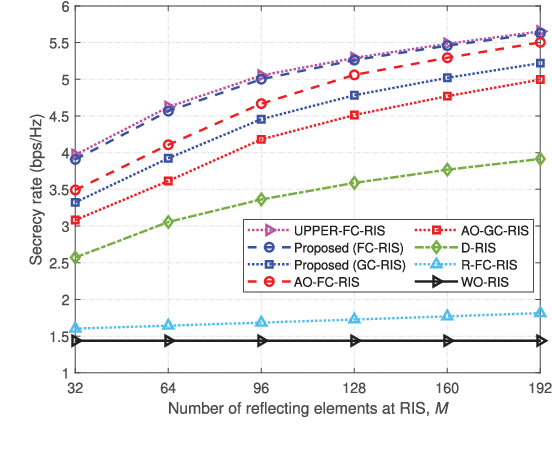
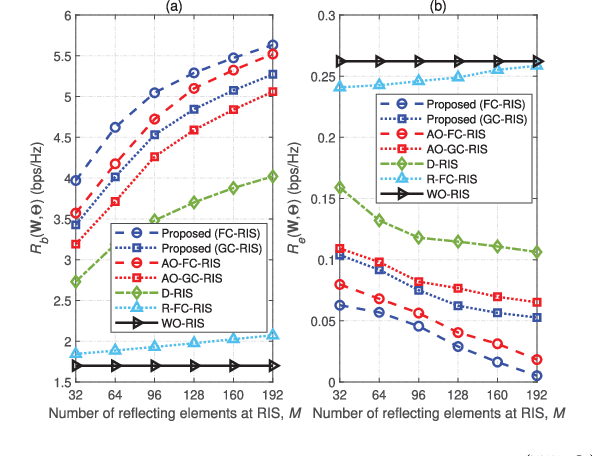
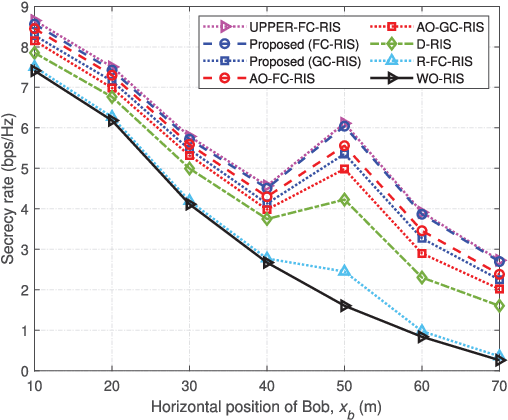
Reconfigurable intelligent surfaces (RISs) hold significant promise for enhancing physical layer security (PLS). However, conventional RISs are typically modeled using diagonal scattering matrices, capturing only independent reflections from each reflecting element, which limits their flexibility in channel manipulation. In contrast, beyond-diagonal RISs (BD-RISs) employ non-diagonal scattering matrices enabled by active and tunable inter-element connections through a shared impedance network. This architecture significantly enhances channel shaping capabilities, creating new opportunities for advanced PLS techniques. This paper investigates PLS in a multiple-input multiple-output (MIMO) system assisted by BD-RISs, where a multi-antenna transmitter sends confidential information to a multi-antenna legitimate user while a multi-antenna eavesdropper attempts interception. To maximize the secrecy rate (SR), we formulate it as a non-convex optimization problem by jointly optimizing the transmit beamforming and BD-RIS REs under power and structural constraints. To solve this problem, we first introduce an auxiliary variable to decouple BD-RIS constraints. We then propose a low-complexity penalty product Riemannian conjugate gradient descent (P-PRCGD) method, which combines the augmented Lagrangian (AL) approach with the product manifold gradient descent (PMGD) method to obtain a Karush-Kuhn-Tucker (KKT) solution. Simulation results confirm that BD-RIS-assisted systems significantly outperform conventional RIS-assisted systems in PLS performance.
Constant-Modulus Secure Analog Beamforming for an IRS-Assisted Communication System with Large-Scale Antenna Array
Nov 19, 2025



Physical layer security (PLS) is an important technology in wireless communication systems to safeguard communication privacy and security between transmitters and legitimate users. The integration of large-scale antenna arrays (LSAA) and intelligent reflecting surfaces (IRS) has emerged as a promising approach to enhance PLS. However, LSAA requires a dedicated radio frequency (RF) chain for each antenna element, and IRS comprises hundreds of reflecting micro-antennas, leading to increased hardware costs and power consumption. To address this, cost-effective solutions like constant modulus analog beamforming (CMAB) have gained attention. This paper investigates PLS in IRS-assisted communication systems with a focus on jointly designing the CMAB at the transmitter and phase shifts at the IRS to maximize the secrecy rate. The resulting secrecy rate maximization (SRM) problem is non-convex. To solve the problem efficiently, we propose two algorithms: (1) the time-efficient Dinkelbach-BSUM algorithm, which reformulates the fractional problem into a series of quadratic programs using the Dinkelbach method and solves them via block successive upper-bound minimization (BSUM), and (2) the product manifold conjugate gradient descent (PMCGD) algorithm, which provides a better solution at the cost of slightly higher computational time by transforming the problem into an unconstrained optimization on a Riemannian product manifold and solving it using the conjugate gradient descent (CGD) algorithm. Simulation results validate the effectiveness of the proposed algorithms and highlight their distinct advantages.