 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Architecture Knowledge Transfer for Large-Scale Online User Response Prediction
Feb 02, 2026Deploying new architectures in large-scale user response prediction systems incurs high model switching costs due to expensive retraining on massive historical data and performance degradation under data retention constraints. Existing knowledge distillation methods struggle with architectural heterogeneity and the prohibitive cost of transferring large embedding tables. We propose CrossAdapt, a two-stage framework for efficient cross-architecture knowledge transfer. The offline stage enables rapid embedding transfer via dimension-adaptive projections without iterative training, combined with progressive network distillation and strategic sampling to reduce computational cost. The online stage introduces asymmetric co-distillation, where students update frequently while teachers update infrequently, together with a distribution-aware adaptation mechanism that dynamically balances historical knowledge preservation and fast adaptation to evolving data. Experiments on three public datasets show that CrossAdapt achieves 0.27-0.43% AUC improvements while reducing training time by 43-71%. Large-scale deployment on Tencent WeChat Channels (~10M daily samples) further demonstrates its effectiveness, significantly mitigating AUC degradation, LogLoss increase, and prediction bias compared to standard distillation baselines.
T2I-RiskyPrompt: A Benchmark for Safety Evaluation, Attack, and Defense on Text-to-Image Model
Oct 25, 2025



Using risky text prompts, such as pornography and violent prompts, to test the safety of text-to-image (T2I) models is a critical task. However, existing risky prompt datasets are limited in three key areas: 1) limited risky categories, 2) coarse-grained annotation, and 3) low effectiveness. To address these limitations, we introduce T2I-RiskyPrompt, a comprehensive benchmark designed for evaluating safety-related tasks in T2I models. Specifically, we first develop a hierarchical risk taxonomy, which consists of 6 primary categories and 14 fine-grained subcategories. Building upon this taxonomy, we construct a pipeline to collect and annotate risky prompts. Finally, we obtain 6,432 effective risky prompts, where each prompt is annotated with both hierarchical category labels and detailed risk reasons. Moreover, to facilitate the evaluation, we propose a reason-driven risky image detection method that explicitly aligns the MLLM with safety annotations. Based on T2I-RiskyPrompt, we conduct a comprehensive evaluation of eight T2I models, nine defense methods, five safety filters, and five attack strategies, offering nine key insights into the strengths and limitations of T2I model safety. Finally, we discuss potential applications of T2I-RiskyPrompt across various research fields. The dataset and code are provided in https://github.com/datar001/T2I-RiskyPrompt.
Structure Causal Models and LLMs Integration in Medical Visual Question Answering
May 05, 2025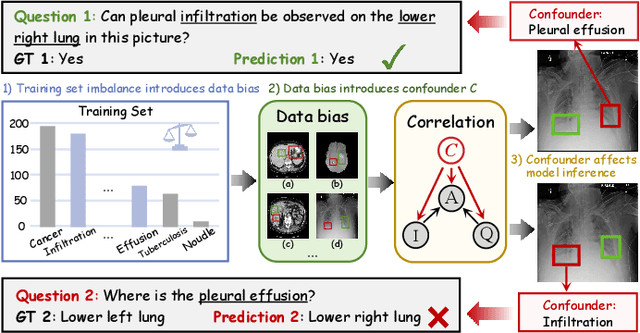

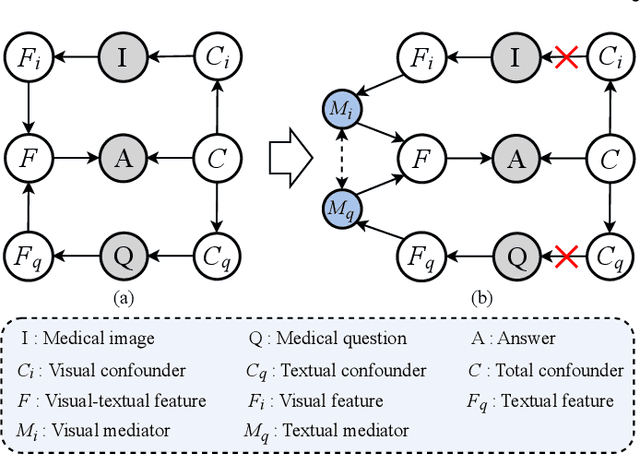
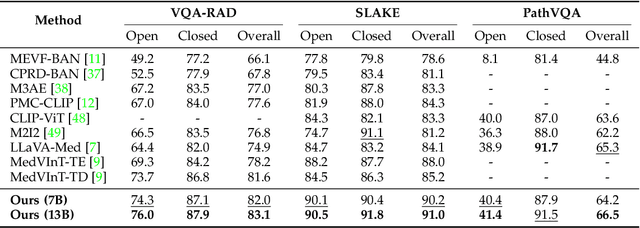
Medical Visual Question Answering (MedVQA) aims to answer medical questions according to medical images. However, the complexity of medical data leads to confounders that are difficult to observe, so bias between images and questions is inevitable. Such cross-modal bias makes it challenging to infer medically meaningful answers. In this work, we propose a causal inference framework for the MedVQA task, which effectively eliminates the relative confounding effect between the image and the question to ensure the precision of the question-answering (QA) session. We are the first to introduce a novel causal graph structure that represents the interaction between visual and textual elements, explicitly capturing how different questions influence visual features. During optimization, we apply the mutual information to discover spurious correlations and propose a multi-variable resampling front-door adjustment method to eliminate the relative confounding effect, which aims to align features based on their true causal relevance to the question-answering task. In addition, we also introduce a prompt strategy that combines multiple prompt forms to improve the model's ability to understand complex medical data and answer accurately. Extensive experiments on three MedVQA datasets demonstrate that 1) our method significantly improves the accuracy of MedVQA, and 2) our method achieves true causal correlations in the face of complex medical data.
Pushing the Limits of Low-Bit Optimizers: A Focus on EMA Dynamics
May 01, 2025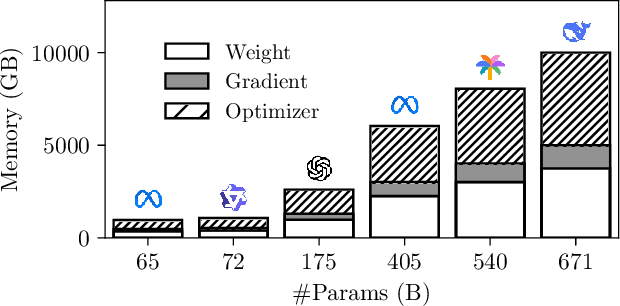
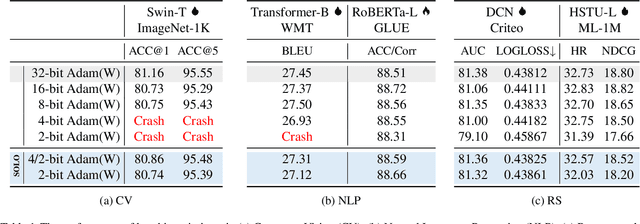
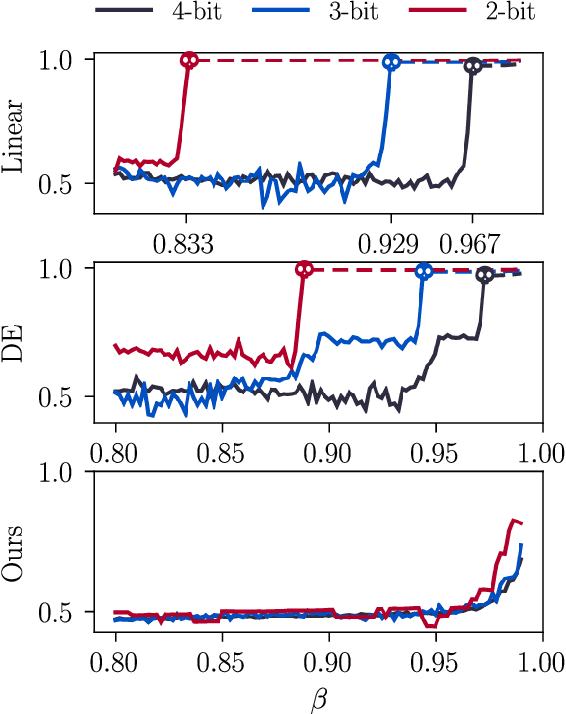
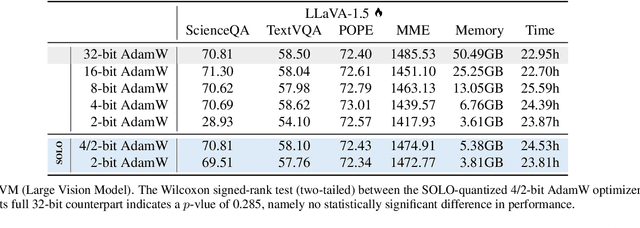
The explosion in model sizes leads to continued growth in prohibitive training/fine-tuning costs, particularly for stateful optimizers which maintain auxiliary information of even 2x the model size to achieve optimal convergence. We therefore present in this work a novel type of optimizer that carries with extremely lightweight state overloads, achieved through ultra-low-precision quantization. While previous efforts have achieved certain success with 8-bit or 4-bit quantization, our approach enables optimizers to operate at precision as low as 3 bits, or even 2 bits per state element. This is accomplished by identifying and addressing two critical challenges: the signal swamping problem in unsigned quantization that results in unchanged state dynamics, and the rapidly increased gradient variance in signed quantization that leads to incorrect descent directions. The theoretical analysis suggests a tailored logarithmic quantization for the former and a precision-specific momentum value for the latter. Consequently, the proposed SOLO achieves substantial memory savings (approximately 45 GB when training a 7B model) with minimal accuracy loss. We hope that SOLO can contribute to overcoming the bottleneck in computational resources, thereby promoting greater accessibility in fundamental research.
Causal Disentanglement for Robust Long-tail Medical Image Generation
Apr 20, 2025Counterfactual medical image generation effectively addresses data scarcity and enhances the interpretability of medical images. However, due to the complex and diverse pathological features of medical images and the imbalanced class distribution in medical data, generating high-quality and diverse medical images from limited data is significantly challenging. Additionally, to fully leverage the information in limited data, such as anatomical structure information and generate more structurally stable medical images while avoiding distortion or inconsistency. In this paper, in order to enhance the clinical relevance of generated data and improve the interpretability of the model, we propose a novel medical image generation framework, which generates independent pathological and structural features based on causal disentanglement and utilizes text-guided modeling of pathological features to regulate the generation of counterfactual images. First, we achieve feature separation through causal disentanglement and analyze the interactions between features. Here, we introduce group supervision to ensure the independence of pathological and identity features. Second, we leverage a diffusion model guided by pathological findings to model pathological features, enabling the generation of diverse counterfactual images. Meanwhile, we enhance accuracy by leveraging a large language model to extract lesion severity and location from medical reports. Additionally, we improve the performance of the latent diffusion model on long-tailed categories through initial noise optimization.
CAdam: Confidence-Based Optimization for Online Learning
Nov 29, 2024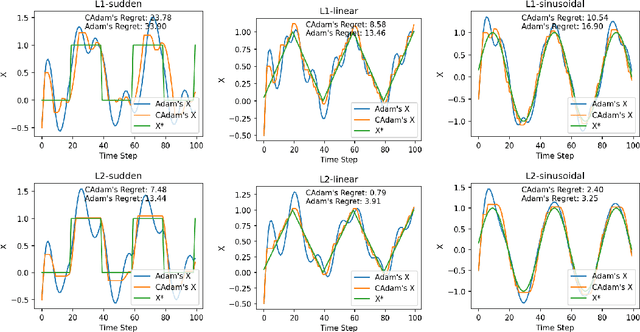

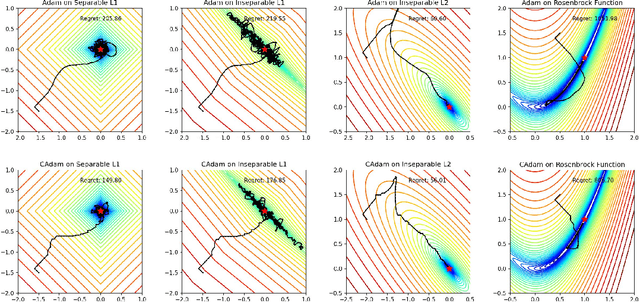

Modern recommendation systems frequently employ online learning to dynamically update their models with freshly collected data. The most commonly used optimizer for updating neural networks in these contexts is the Adam optimizer, which integrates momentum ($m_t$) and adaptive learning rate ($v_t$). However, the volatile nature of online learning data, characterized by its frequent distribution shifts and presence of noises, poses significant challenges to Adam's standard optimization process: (1) Adam may use outdated momentum and the average of squared gradients, resulting in slower adaptation to distribution changes, and (2) Adam's performance is adversely affected by data noise. To mitigate these issues, we introduce CAdam, a confidence-based optimization strategy that assesses the consistence between the momentum and the gradient for each parameter dimension before deciding on updates. If momentum and gradient are in sync, CAdam proceeds with parameter updates according to Adam's original formulation; if not, it temporarily withholds updates and monitors potential shifts in data distribution in subsequent iterations. This method allows CAdam to distinguish between the true distributional shifts and mere noise, and adapt more quickly to new data distributions. Our experiments with both synthetic and real-world datasets demonstrate that CAdam surpasses other well-known optimizers, including the original Adam, in efficiency and noise robustness. Furthermore, in large-scale A/B testing within a live recommendation system, CAdam significantly enhances model performance compared to Adam, leading to substantial increases in the system's gross merchandise volume (GMV).
BooW-VTON: Boosting In-the-Wild Virtual Try-On via Mask-Free Pseudo Data Training
Aug 12, 2024

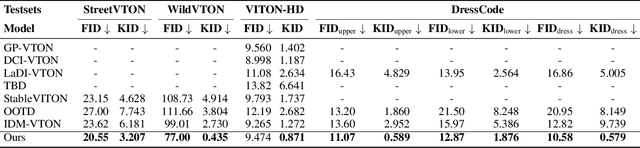
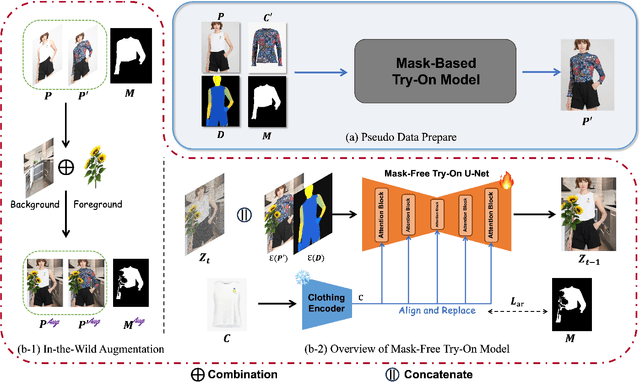
Image-based virtual try-on is an increasingly popular and important task to generate realistic try-on images of specific person. Existing methods always employ an accurate mask to remove the original garment in the source image, thus achieving realistic synthesized images in simple and conventional try-on scenarios based on powerful diffusion model. Therefore, acquiring suitable mask is vital to the try-on performance of these methods. However, obtaining precise inpainting masks, especially for complex wild try-on data containing diverse foreground occlusions and person poses, is not easy as Figure 1-Top shows. This difficulty often results in poor performance in more practical and challenging real-life scenarios, such as the selfie scene shown in Figure 1-Bottom. To this end, we propose a novel training paradigm combined with an efficient data augmentation method to acquire large-scale unpaired training data from wild scenarios, thereby significantly facilitating the try-on performance of our model without the need for additional inpainting masks. Besides, a try-on localization loss is designed to localize a more accurate try-on area to obtain more reasonable try-on results. It is noted that our method only needs the reference cloth image, source pose image and source person image as input, which is more cost-effective and user-friendly compared to existing methods. Extensive qualitative and quantitative experiments have demonstrated superior performance in wild scenarios with such a low-demand input.
Better Fit: Accommodate Variations in Clothing Types for Virtual Try-on
Mar 13, 2024

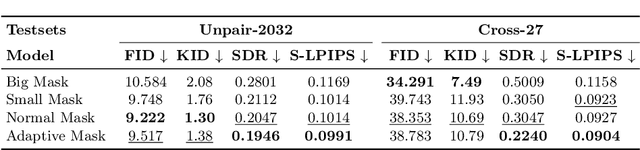
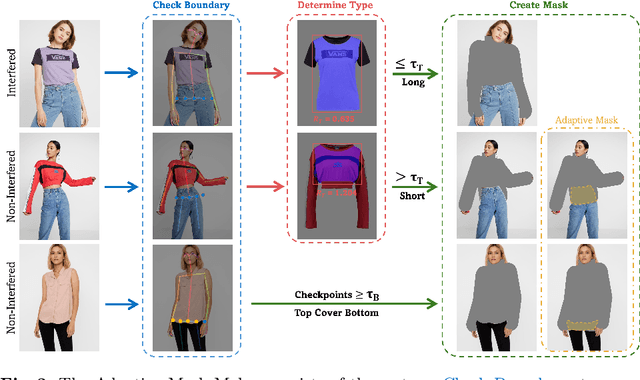
Image-based virtual try-on aims to transfer target in-shop clothing to a dressed model image, the objectives of which are totally taking off original clothing while preserving the contents outside of the try-on area, naturally wearing target clothing and correctly inpainting the gap between target clothing and original clothing. Tremendous efforts have been made to facilitate this popular research area, but cannot keep the type of target clothing with the try-on area affected by original clothing. In this paper, we focus on the unpaired virtual try-on situation where target clothing and original clothing on the model are different, i.e., the practical scenario. To break the correlation between the try-on area and the original clothing and make the model learn the correct information to inpaint, we propose an adaptive mask training paradigm that dynamically adjusts training masks. It not only improves the alignment and fit of clothing but also significantly enhances the fidelity of virtual try-on experience. Furthermore, we for the first time propose two metrics for unpaired try-on evaluation, the Semantic-Densepose-Ratio (SDR) and Skeleton-LPIPS (S-LPIPS), to evaluate the correctness of clothing type and the accuracy of clothing texture. For unpaired try-on validation, we construct a comprehensive cross-try-on benchmark (Cross-27) with distinctive clothing items and model physiques, covering a broad try-on scenarios. Experiments demonstrate the effectiveness of the proposed methods, contributing to the advancement of virtual try-on technology and offering new insights and tools for future research in the field. The code, model and benchmark will be publicly released.
Revealing Vulnerabilities in Stable Diffusion via Targeted Attacks
Jan 16, 2024Recent developments in text-to-image models, particularly Stable Diffusion, have marked significant achievements in various applications. With these advancements, there are growing safety concerns about the vulnerability of the model that malicious entities exploit to generate targeted harmful images. However, the existing methods in the vulnerability of the model mainly evaluate the alignment between the prompt and generated images, but fall short in revealing the vulnerability associated with targeted image generation. In this study, we formulate the problem of targeted adversarial attack on Stable Diffusion and propose a framework to generate adversarial prompts. Specifically, we design a gradient-based embedding optimization method to craft reliable adversarial prompts that guide stable diffusion to generate specific images. Furthermore, after obtaining successful adversarial prompts, we reveal the mechanisms that cause the vulnerability of the model. Extensive experiments on two targeted attack tasks demonstrate the effectiveness of our method in targeted attacks. The code can be obtained in https://github.com/datar001/Revealing-Vulnerabilities-in-Stable-Diffusion-via-Targeted-Attacks.
CAT-DM: Controllable Accelerated Virtual Try-on with Diffusion Model
Nov 30, 2023



Image-based virtual try-on enables users to virtually try on different garments by altering original clothes in their photographs. Generative Adversarial Networks (GANs) dominate the research field in image-based virtual try-on, but have not resolved problems such as unnatural deformation of garments and the blurry generation quality. Recently, diffusion models have emerged with surprising performance across various image generation tasks. While the generative quality of diffusion models is impressive, achieving controllability poses a significant challenge when applying it to virtual try-on tasks and multiple denoising iterations limit its potential for real-time applications. In this paper, we propose Controllable Accelerated virtual Try-on with Diffusion Model called CAT-DM. To enhance the controllability, a basic diffusion-based virtual try-on network is designed, which utilizes ControlNet to introduce additional control conditions and improves the feature extraction of garment images. In terms of acceleration, CAT-DM initiates a reverse denoising process with an implicit distribution generated by a pre-trained GAN-based model. Compared with previous try-on methods based on diffusion models, CAT-DM not only retains the pattern and texture details of the in-shop garment but also reduces the sampling steps without compromising generation quality. Extensive experiments demonstrate the superiority of CAT-DM against both GAN-based and diffusion-based methods in producing more realistic images and accurately reproducing garment patterns. Our code and models will be publicly released.