 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Learning Dynamics of Long-Context Continual Pre-training
Apr 03, 2026Existing studies on Long-Context Continual Pre-training (LCCP) mainly focus on small-scale models and limited data regimes (tens of billions of tokens). We argue that directly migrating these small-scale settings to industrial-grade models risks insufficient adaptation and premature training termination. Furthermore, current evaluation methods rely heavily on downstream benchmarks (e.g., Needle-in-a-Haystack), which often fail to reflect the intrinsic convergence state and can lead to "deceptive saturation". In this paper, we present the first systematic investigation of LCCP learning dynamics using the industrial-grade Hunyuan-A13B (80B total parameters), tracking its evolution across a 200B-token training trajectory. Specifically, we propose a hierarchical framework to analyze LCCP dynamics across behavioral (supervised fine-tuning probing), probabilistic (perplexity), and mechanistic (attention patterns) levels. Our findings reveal: (1) Necessity of Massive Data Scaling: Training regimes of dozens of billions of tokens are insufficient for industrial-grade LLMs' LCCP (e.g., Hunyuan-A13B reaches saturation after training over 150B tokens). (2) Deceptive Saturation vs. Intrinsic Saturation: Traditional NIAH scores report "fake saturation" early, while our PPL-based analysis reveals continuous intrinsic improvements and correlates more strongly with downstream performance. (3) Mechanistic Monitoring for Training Stability: Retrieval heads act as efficient, low-resource training monitors, as their evolving attention scores reliably track LCCP progress and exhibit high correlation with SFT results. This work provides a comprehensive monitoring framework, evaluation system, and mechanistic interpretation for the LCCP of industrial-grade LLM.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Sequential-NIAH: A Needle-In-A-Haystack Benchmark for Extracting Sequential Needles from Long Contexts
Apr 09, 2025Evaluating the ability of large language models (LLMs) to handle extended contexts is critical, particularly for retrieving information relevant to specific queries embedded within lengthy inputs. We introduce Sequential-NIAH, a benchmark specifically designed to evaluate the capability of LLMs to extract sequential information items (known as needles) from long contexts. The benchmark comprises three types of needle generation pipelines: synthetic, real, and open-domain QA. It includes contexts ranging from 8K to 128K tokens in length, with a dataset of 14,000 samples (2,000 reserved for testing). To facilitate evaluation on this benchmark, we trained a synthetic data-driven evaluation model capable of evaluating answer correctness based on chronological or logical order, achieving an accuracy of 99.49% on synthetic test data. We conducted experiments on six well-known LLMs, revealing that even the best-performing model achieved a maximum accuracy of only 63.15%. Further analysis highlights the growing challenges posed by increasing context lengths and the number of needles, underscoring substantial room for improvement. Additionally, noise robustness experiments validate the reliability of the benchmark, making Sequential-NIAH an important reference for advancing research on long text extraction capabilities of LLMs.
CAdam: Confidence-Based Optimization for Online Learning
Nov 29, 2024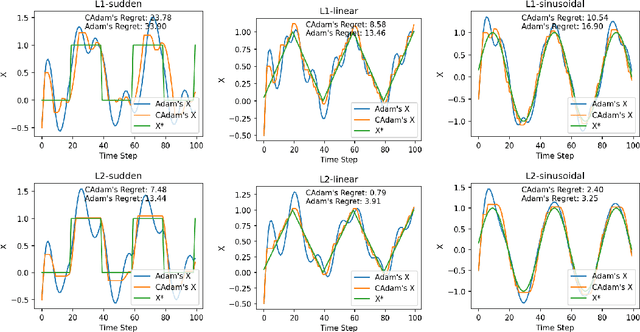

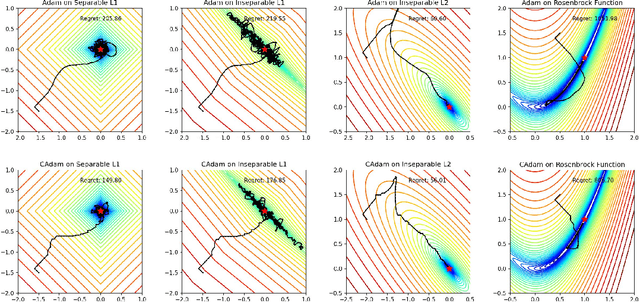

Modern recommendation systems frequently employ online learning to dynamically update their models with freshly collected data. The most commonly used optimizer for updating neural networks in these contexts is the Adam optimizer, which integrates momentum ($m_t$) and adaptive learning rate ($v_t$). However, the volatile nature of online learning data, characterized by its frequent distribution shifts and presence of noises, poses significant challenges to Adam's standard optimization process: (1) Adam may use outdated momentum and the average of squared gradients, resulting in slower adaptation to distribution changes, and (2) Adam's performance is adversely affected by data noise. To mitigate these issues, we introduce CAdam, a confidence-based optimization strategy that assesses the consistence between the momentum and the gradient for each parameter dimension before deciding on updates. If momentum and gradient are in sync, CAdam proceeds with parameter updates according to Adam's original formulation; if not, it temporarily withholds updates and monitors potential shifts in data distribution in subsequent iterations. This method allows CAdam to distinguish between the true distributional shifts and mere noise, and adapt more quickly to new data distributions. Our experiments with both synthetic and real-world datasets demonstrate that CAdam surpasses other well-known optimizers, including the original Adam, in efficiency and noise robustness. Furthermore, in large-scale A/B testing within a live recommendation system, CAdam significantly enhances model performance compared to Adam, leading to substantial increases in the system's gross merchandise volume (GMV).
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Taking a Deep Breath: Enhancing Language Modeling of Large Language Models with Sentinel Tokens
Jun 16, 2024



Large language models (LLMs) have shown promising efficacy across various tasks, becoming powerful tools in numerous aspects of human life. However, Transformer-based LLMs suffer a performance degradation when modeling long-term contexts due to they discard some information to reduce computational overhead. In this work, we propose a simple yet effective method to enable LLMs to take a deep breath, encouraging them to summarize information contained within discrete text chunks. Specifically, we segment the text into multiple chunks and insert special token <SR> at the end of each chunk. We then modify the attention mask to integrate the chunk's information into the corresponding <SR> token. This facilitates LLMs to interpret information not only from historical individual tokens but also from the <SR> token, aggregating the chunk's semantic information. Experiments on language modeling and out-of-domain downstream tasks validate the superiority of our approach.
TexSmart: A Text Understanding System for Fine-Grained NER and Enhanced Semantic Analysis
Dec 31, 2020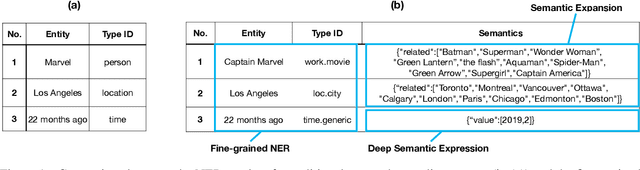


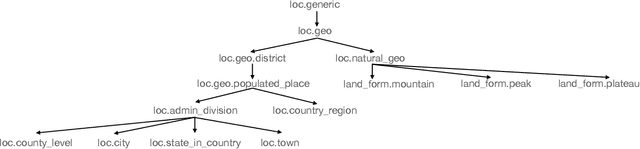
This technique report introduces TexSmart, a text understanding system that supports fine-grained named entity recognition (NER) and enhanced semantic analysis functionalities. Compared to most previous publicly available text understanding systems and tools, TexSmart holds some unique features. First, the NER function of TexSmart supports over 1,000 entity types, while most other public tools typically support several to (at most) dozens of entity types. Second, TexSmart introduces new semantic analysis functions like semantic expansion and deep semantic representation, that are absent in most previous systems. Third, a spectrum of algorithms (from very fast algorithms to those that are relatively slow but more accurate) are implemented for one function in TexSmart, to fulfill the requirements of different academic and industrial applications. The adoption of unsupervised or weakly-supervised algorithms is especially emphasized, with the goal of easily updating our models to include fresh data with less human annotation efforts. The main contents of this report include major functions of TexSmart, algorithms for achieving these functions, how to use the TexSmart toolkit and Web APIs, and evaluation results of some key algorithms.
Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
Jun 07, 2017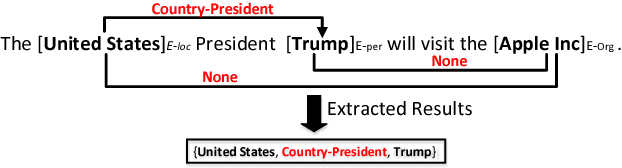
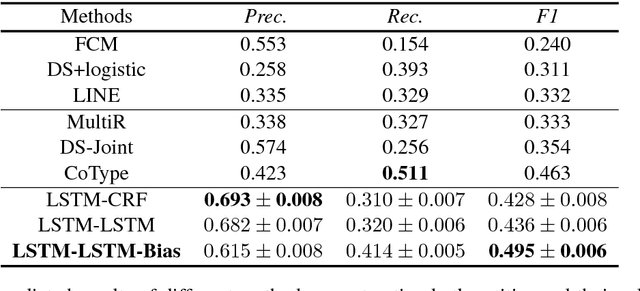


Joint extraction of entities and relations is an important task in information extraction. To tackle this problem, we firstly propose a novel tagging scheme that can convert the joint extraction task to a tagging problem. Then, based on our tagging scheme, we study different end-to-end models to extract entities and their relations directly, without identifying entities and relations separately. We conduct experiments on a public dataset produced by distant supervision method and the experimental results show that the tagging based methods are better than most of the existing pipelined and joint learning methods. What's more, the end-to-end model proposed in this paper, achieves the best results on the public dataset.
Self-Taught Convolutional Neural Networks for Short Text Clustering
Jan 01, 2017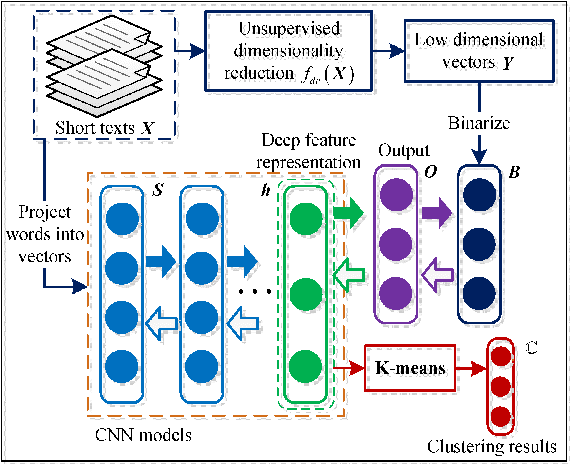
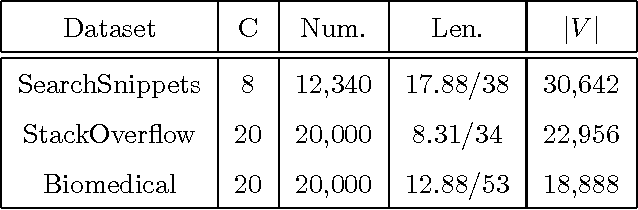
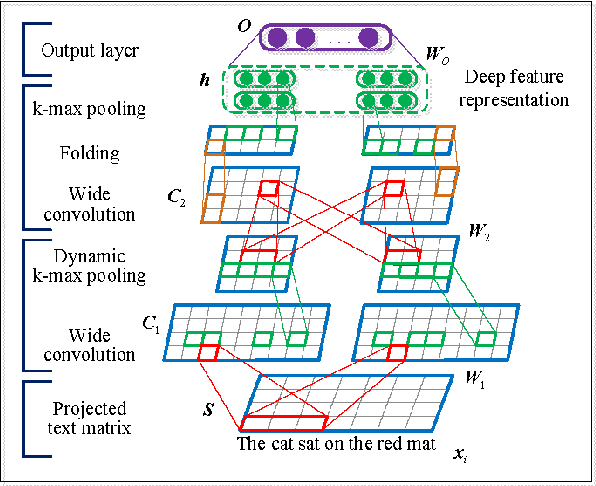
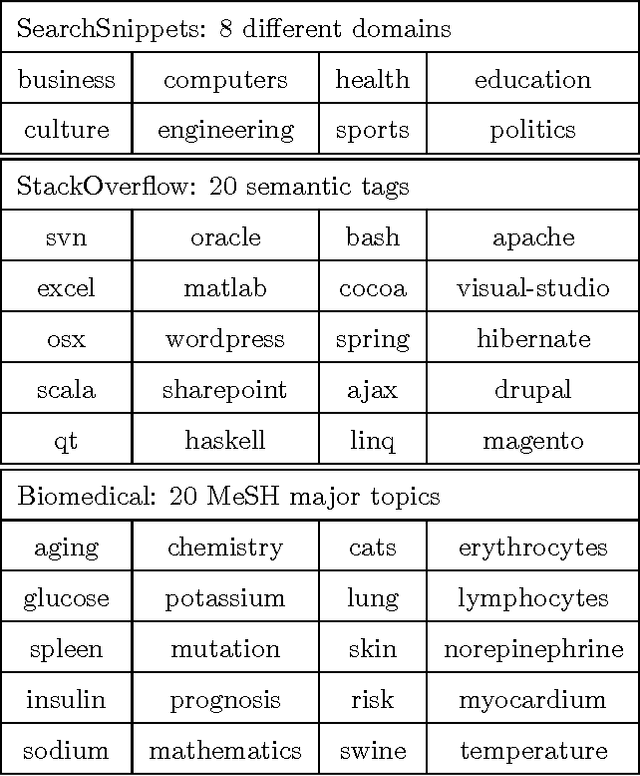
Short text clustering is a challenging problem due to its sparseness of text representation. Here we propose a flexible Self-Taught Convolutional neural network framework for Short Text Clustering (dubbed STC^2), which can flexibly and successfully incorporate more useful semantic features and learn non-biased deep text representation in an unsupervised manner. In our framework, the original raw text features are firstly embedded into compact binary codes by using one existing unsupervised dimensionality reduction methods. Then, word embeddings are explored and fed into convolutional neural networks to learn deep feature representations, meanwhile the output units are used to fit the pre-trained binary codes in the training process. Finally, we get the optimal clusters by employing K-means to cluster the learned representations. Extensive experimental results demonstrate that the proposed framework is effective, flexible and outperform several popular clustering methods when tested on three public short text datasets.
Text Classification Improved by Integrating Bidirectional LSTM with Two-dimensional Max Pooling
Nov 21, 2016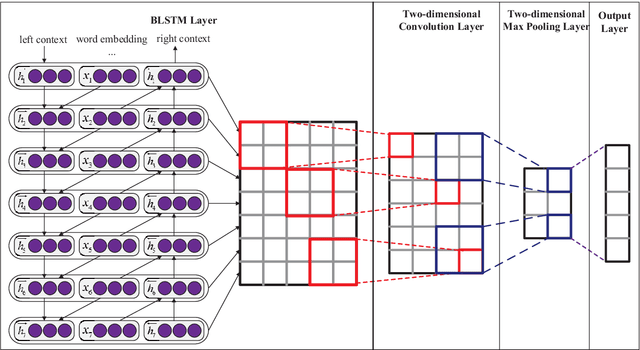
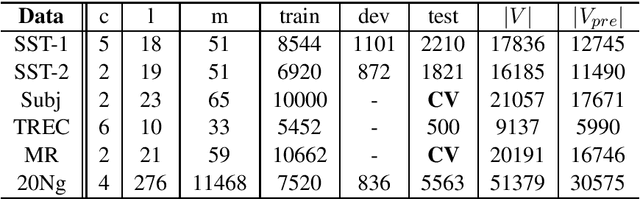
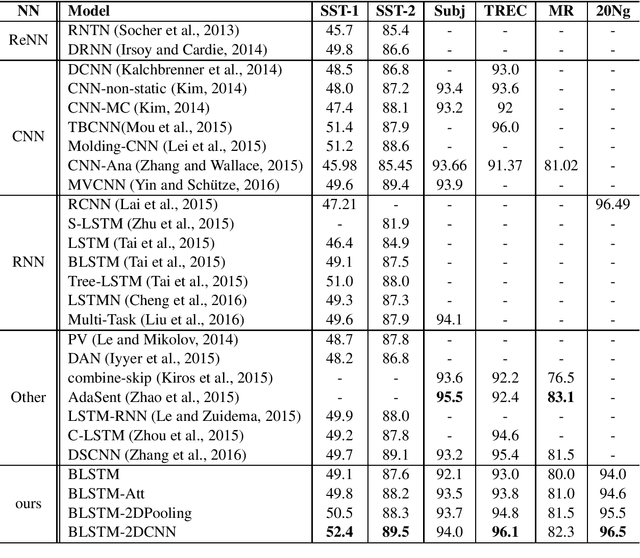
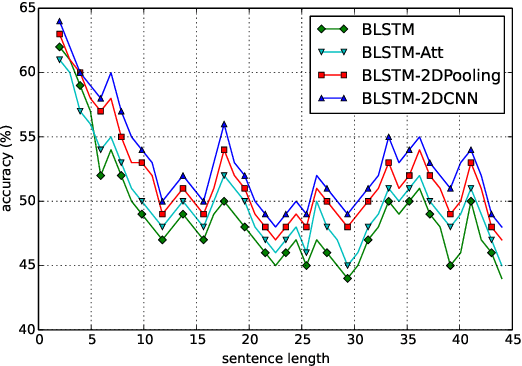
Recurrent Neural Network (RNN) is one of the most popular architectures used in Natural Language Processsing (NLP) tasks because its recurrent structure is very suitable to process variable-length text. RNN can utilize distributed representations of words by first converting the tokens comprising each text into vectors, which form a matrix. And this matrix includes two dimensions: the time-step dimension and the feature vector dimension. Then most existing models usually utilize one-dimensional (1D) max pooling operation or attention-based operation only on the time-step dimension to obtain a fixed-length vector. However, the features on the feature vector dimension are not mutually independent, and simply applying 1D pooling operation over the time-step dimension independently may destroy the structure of the feature representation. On the other hand, applying two-dimensional (2D) pooling operation over the two dimensions may sample more meaningful features for sequence modeling tasks. To integrate the features on both dimensions of the matrix, this paper explores applying 2D max pooling operation to obtain a fixed-length representation of the text. This paper also utilizes 2D convolution to sample more meaningful information of the matrix. Experiments are conducted on six text classification tasks, including sentiment analysis, question classification, subjectivity classification and newsgroup classification. Compared with the state-of-the-art models, the proposed models achieve excellent performance on 4 out of 6 tasks. Specifically, one of the proposed models achieves highest accuracy on Stanford Sentiment Treebank binary classification and fine-grained classification tasks.