 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Architecture Knowledge Transfer for Large-Scale Online User Response Prediction
Feb 02, 2026Deploying new architectures in large-scale user response prediction systems incurs high model switching costs due to expensive retraining on massive historical data and performance degradation under data retention constraints. Existing knowledge distillation methods struggle with architectural heterogeneity and the prohibitive cost of transferring large embedding tables. We propose CrossAdapt, a two-stage framework for efficient cross-architecture knowledge transfer. The offline stage enables rapid embedding transfer via dimension-adaptive projections without iterative training, combined with progressive network distillation and strategic sampling to reduce computational cost. The online stage introduces asymmetric co-distillation, where students update frequently while teachers update infrequently, together with a distribution-aware adaptation mechanism that dynamically balances historical knowledge preservation and fast adaptation to evolving data. Experiments on three public datasets show that CrossAdapt achieves 0.27-0.43% AUC improvements while reducing training time by 43-71%. Large-scale deployment on Tencent WeChat Channels (~10M daily samples) further demonstrates its effectiveness, significantly mitigating AUC degradation, LogLoss increase, and prediction bias compared to standard distillation baselines.
Real-time Ad retrieval via LLM-generative Commercial Intention for Sponsored Search Advertising
Apr 02, 2025



The integration of Large Language Models (LLMs) with retrieval systems has shown promising potential in retrieving documents (docs) or advertisements (ads) for a given query. Existing LLM-based retrieval methods generate numeric or content-based DocIDs to retrieve docs/ads. However, the one-to-few mapping between numeric IDs and docs, along with the time-consuming content extraction, leads to semantic inefficiency and limits scalability in large-scale corpora. In this paper, we propose the Real-time Ad REtrieval (RARE) framework, which leverages LLM-generated text called Commercial Intentions (CIs) as an intermediate semantic representation to directly retrieve ads for queries in real-time. These CIs are generated by a customized LLM injected with commercial knowledge, enhancing its domain relevance. Each CI corresponds to multiple ads, yielding a lightweight and scalable set of CIs. RARE has been implemented in a real-world online system, handling daily search volumes in the hundreds of millions. The online implementation has yielded significant benefits: a 5.04% increase in consumption, a 6.37% rise in Gross Merchandise Volume (GMV), a 1.28% enhancement in click-through rate (CTR) and a 5.29% increase in shallow conversions. Extensive offline experiments show RARE's superiority over ten competitive baselines in four major categories.
CAdam: Confidence-Based Optimization for Online Learning
Nov 29, 2024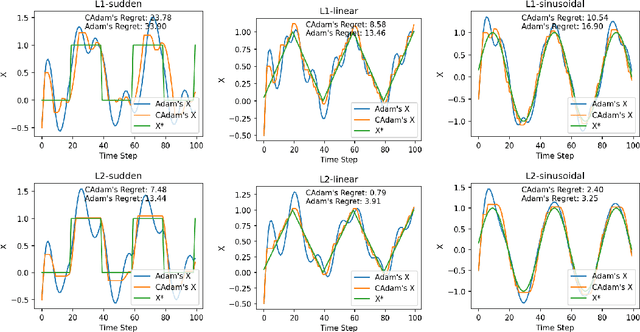

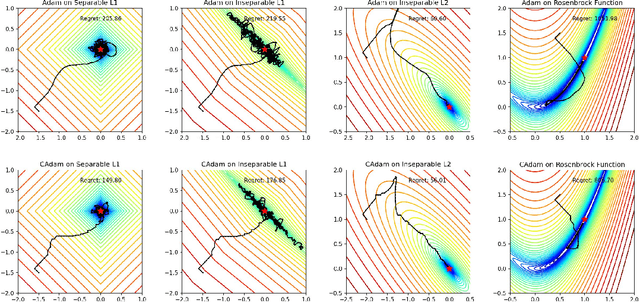

Modern recommendation systems frequently employ online learning to dynamically update their models with freshly collected data. The most commonly used optimizer for updating neural networks in these contexts is the Adam optimizer, which integrates momentum ($m_t$) and adaptive learning rate ($v_t$). However, the volatile nature of online learning data, characterized by its frequent distribution shifts and presence of noises, poses significant challenges to Adam's standard optimization process: (1) Adam may use outdated momentum and the average of squared gradients, resulting in slower adaptation to distribution changes, and (2) Adam's performance is adversely affected by data noise. To mitigate these issues, we introduce CAdam, a confidence-based optimization strategy that assesses the consistence between the momentum and the gradient for each parameter dimension before deciding on updates. If momentum and gradient are in sync, CAdam proceeds with parameter updates according to Adam's original formulation; if not, it temporarily withholds updates and monitors potential shifts in data distribution in subsequent iterations. This method allows CAdam to distinguish between the true distributional shifts and mere noise, and adapt more quickly to new data distributions. Our experiments with both synthetic and real-world datasets demonstrate that CAdam surpasses other well-known optimizers, including the original Adam, in efficiency and noise robustness. Furthermore, in large-scale A/B testing within a live recommendation system, CAdam significantly enhances model performance compared to Adam, leading to substantial increases in the system's gross merchandise volume (GMV).
AdaS&S: a One-Shot Supernet Approach for Automatic Embedding Size Search in Deep Recommender System
Nov 12, 2024



Deep Learning Recommendation Model(DLRM)s utilize the embedding layer to represent various categorical features. Traditional DLRMs adopt unified embedding size for all features, leading to suboptimal performance and redundant parameters. Thus, lots of Automatic Embedding size Search (AES) works focus on obtaining mixed embedding sizes with strong model performance. However, previous AES works can hardly address several challenges together: (1) The search results of embedding sizes are unstable; (2) Recommendation effect with AES results is unsatisfactory; (3) Memory cost of embeddings is uncontrollable. To address these challenges, we propose a novel one-shot AES framework called AdaS&S, in which a supernet encompassing various candidate embeddings is built and AES is performed as searching network architectures within it. Our framework contains two main stages: In the first stage, we decouple training parameters from searching embedding sizes, and propose the Adaptive Sampling method to yield a well-trained supernet, which further helps to produce stable AES results. In the second stage, to obtain embedding sizes that benefits the model effect, we design a reinforcement learning search process which utilizes the supernet trained previously. Meanwhile, to adapt searching to specific resource constraint, we introduce the resource competition penalty to balance the model effectiveness and memory cost of embeddings. We conduct extensive experiments on public datasets to show the superiority of AdaS&S. Our method could improve AUC by about 0.3% while saving about 20% of model parameters. Empirical analysis also shows that the stability of searching results in AdaS&S significantly exceeds other methods.
Exploring the Potential of Large Language Models in Graph Generation
Mar 21, 2024Large language models (LLMs) have achieved great success in many fields, and recent works have studied exploring LLMs for graph discriminative tasks such as node classification. However, the abilities of LLMs for graph generation remain unexplored in the literature. Graph generation requires the LLM to generate graphs with given properties, which has valuable real-world applications such as drug discovery, while tends to be more challenging. In this paper, we propose LLM4GraphGen to explore the ability of LLMs for graph generation with systematical task designs and extensive experiments. Specifically, we propose several tasks tailored with comprehensive experiments to address key questions regarding LLMs' understanding of different graph structure rules, their ability to capture structural type distributions, and their utilization of domain knowledge for property-based graph generation. Our evaluations demonstrate that LLMs, particularly GPT-4, exhibit preliminary abilities in graph generation tasks, including rule-based and distribution-based generation. We also observe that popular prompting methods, such as few-shot and chain-of-thought prompting, do not consistently enhance performance. Besides, LLMs show potential in generating molecules with specific properties. These findings may serve as foundations for designing good LLMs based models for graph generation and provide valuable insights and further research.
FlexHB: a More Efficient and Flexible Framework for Hyperparameter Optimization
Feb 21, 2024Given a Hyperparameter Optimization(HPO) problem, how to design an algorithm to find optimal configurations efficiently? Bayesian Optimization(BO) and the multi-fidelity BO methods employ surrogate models to sample configurations based on history evaluations. More recent studies obtain better performance by integrating BO with HyperBand(HB), which accelerates evaluation by early stopping mechanism. However, these methods ignore the advantage of a suitable evaluation scheme over the default HyperBand, and the capability of BO is still constrained by skewed evaluation results. In this paper, we propose FlexHB, a new method pushing multi-fidelity BO to the limit as well as re-designing a framework for early stopping with Successive Halving(SH). Comprehensive study on FlexHB shows that (1) our fine-grained fidelity method considerably enhances the efficiency of searching optimal configurations, (2) our FlexBand framework (self-adaptive allocation of SH brackets, and global ranking of configurations in both current and past SH procedures) grants the algorithm with more flexibility and improves the anytime performance. Our method achieves superior efficiency and outperforms other methods on various HPO tasks. Empirical results demonstrate that FlexHB can achieve up to 6.9X and 11.1X speedups over the state-of-the-art MFES-HB and BOHB respectively.
A Survey on Dropout Methods and Experimental Verification in Recommendation
Apr 05, 2022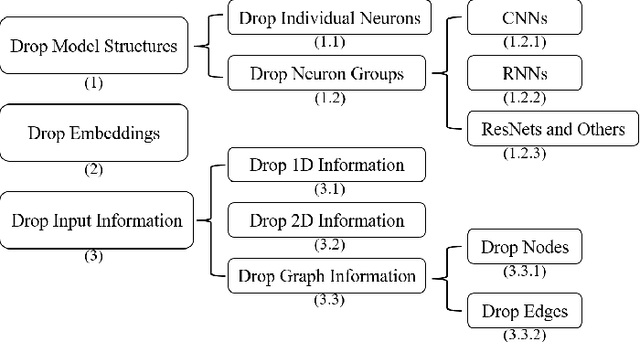
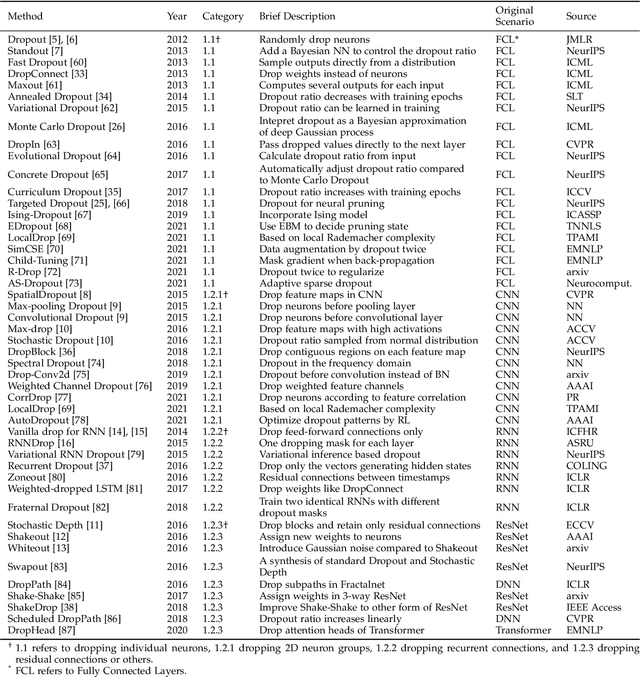
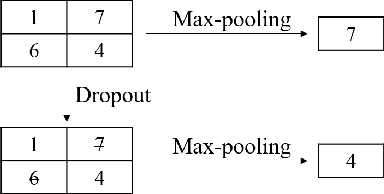
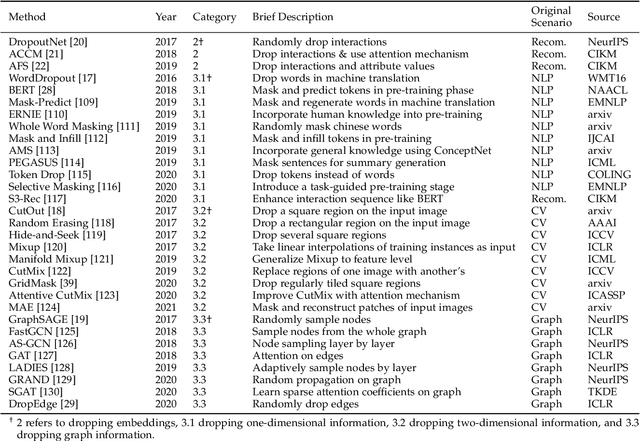
Overfitting is a common problem in machine learning, which means the model too closely fits the training data while performing poorly in the test data. Among various methods of coping with overfitting, dropout is one of the representative ways. From randomly dropping neurons to dropping neural structures, dropout has achieved great success in improving model performances. Although various dropout methods have been designed and widely applied in past years, their effectiveness, application scenarios, and contributions have not been comprehensively summarized and empirically compared by far. It is the right time to make a comprehensive survey. In this paper, we systematically review previous dropout methods and classify them into three major categories according to the stage where dropout operation is performed. Specifically, more than seventy dropout methods published in top AI conferences or journals (e.g., TKDE, KDD, TheWebConf, SIGIR) are involved. The designed taxonomy is easy to understand and capable of including new dropout methods. Then, we further discuss their application scenarios, connections, and contributions. To verify the effectiveness of distinct dropout methods, extensive experiments are conducted on recommendation scenarios with abundant heterogeneous information. Finally, we propose some open problems and potential research directions about dropout that worth to be further explored.
Distributed Equivalent Substitution Training for Large-Scale Recommender Systems
Sep 10, 2019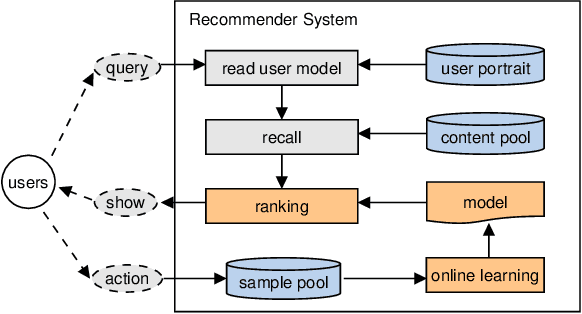
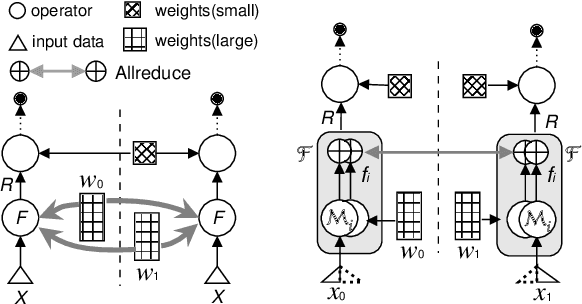
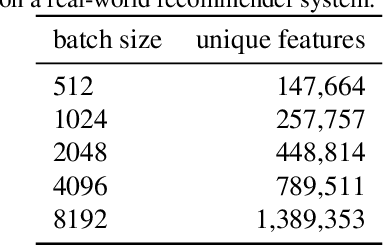
We present Distributed Equivalent Substitution (DES) training, a novel distributed training framework for recommender systems with large-scale dynamic sparse features. Our framework achieves faster convergence with less communication overhead and better computing resource utilization. DES strategy splits a weights-rich operator into sub-operators with co-located weights and aggregates partial results with much smaller communication cost to form a computationally equivalent substitution to the original operator. We show that for different types of models that recommender systems use, we can always find computational equivalent substitutions and splitting strategies for their weights-rich operators with theoretical communication load reduced ranging from 72.26% to 99.77%. We also present an implementation of DES that outperforms state-of-the-art recommender systems. Experiments show that our framework achieves up to 83% communication savings compared to other recommender systems, and can bring up to 4.5x improvement on throughput for deep models.
Neural Machine Translation with Key-Value Memory-Augmented Attention
Jun 29, 2018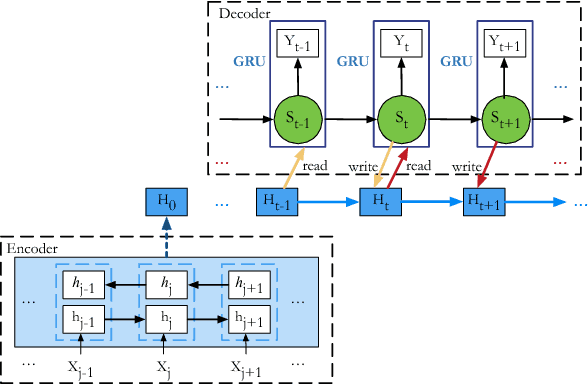
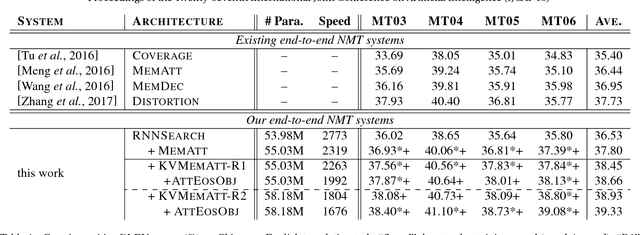
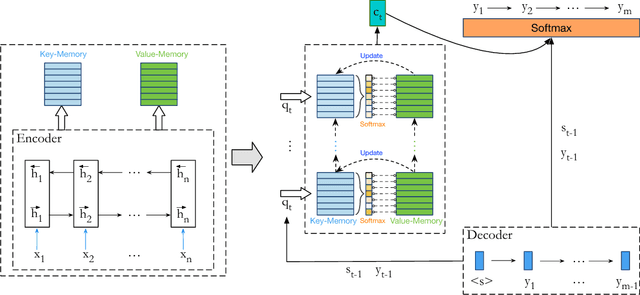
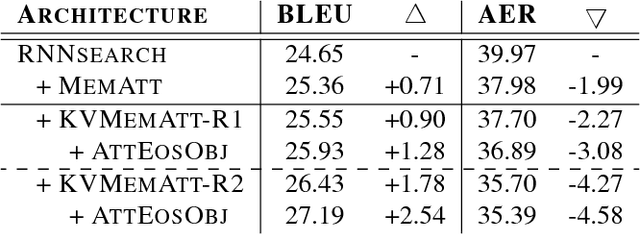
Although attention-based Neural Machine Translation (NMT) has achieved remarkable progress in recent years, it still suffers from issues of repeating and dropping translations. To alleviate these issues, we propose a novel key-value memory-augmented attention model for NMT, called KVMEMATT. Specifically, we maintain a timely updated keymemory to keep track of attention history and a fixed value-memory to store the representation of source sentence throughout the whole translation process. Via nontrivial transformations and iterative interactions between the two memories, the decoder focuses on more appropriate source word(s) for predicting the next target word at each decoding step, therefore can improve the adequacy of translations. Experimental results on Chinese=>English and WMT17 German<=>English translation tasks demonstrate the superiority of the proposed model.