 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Dropout Methods and Experimental Verification in Recommendation
Paper and Code
Apr 05, 2022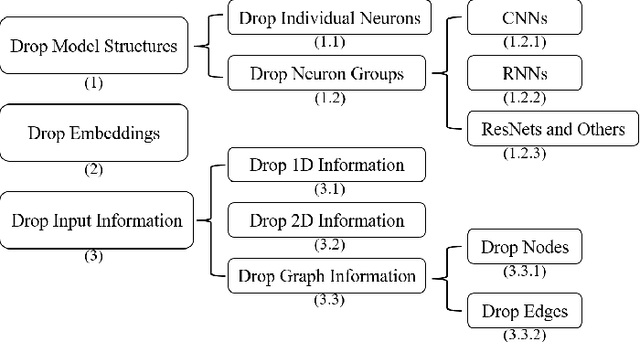
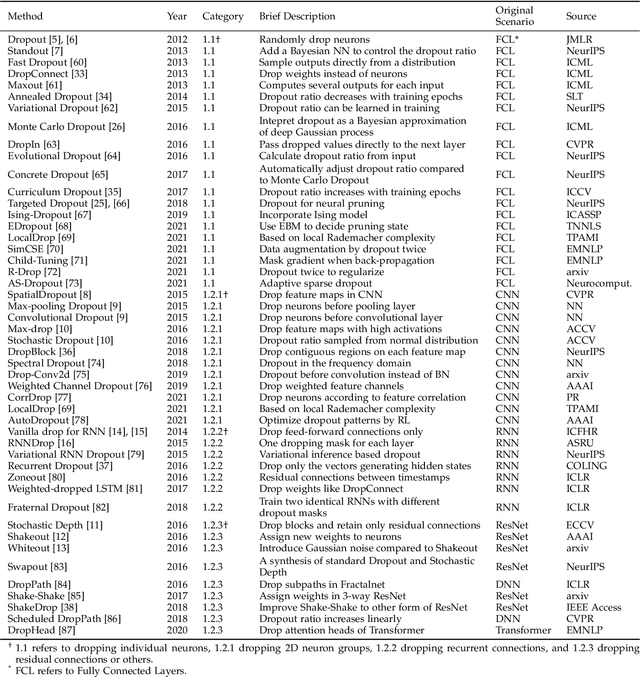
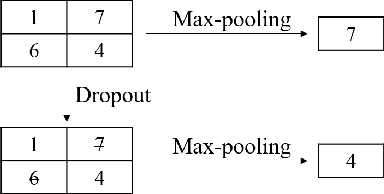
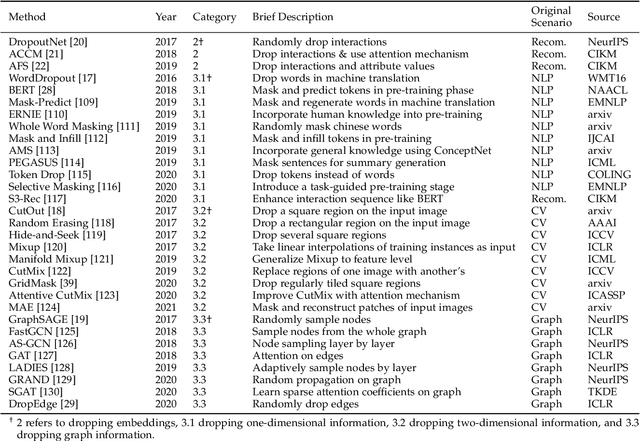
Overfitting is a common problem in machine learning, which means the model too closely fits the training data while performing poorly in the test data. Among various methods of coping with overfitting, dropout is one of the representative ways. From randomly dropping neurons to dropping neural structures, dropout has achieved great success in improving model performances. Although various dropout methods have been designed and widely applied in past years, their effectiveness, application scenarios, and contributions have not been comprehensively summarized and empirically compared by far. It is the right time to make a comprehensive survey. In this paper, we systematically review previous dropout methods and classify them into three major categories according to the stage where dropout operation is performed. Specifically, more than seventy dropout methods published in top AI conferences or journals (e.g., TKDE, KDD, TheWebConf, SIGIR) are involved. The designed taxonomy is easy to understand and capable of including new dropout methods. Then, we further discuss their application scenarios, connections, and contributions. To verify the effectiveness of distinct dropout methods, extensive experiments are conducted on recommendation scenarios with abundant heterogeneous information. Finally, we propose some open problems and potential research directions about dropout that worth to be further explored.