 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Architecture Knowledge Transfer for Large-Scale Online User Response Prediction
Feb 02, 2026Deploying new architectures in large-scale user response prediction systems incurs high model switching costs due to expensive retraining on massive historical data and performance degradation under data retention constraints. Existing knowledge distillation methods struggle with architectural heterogeneity and the prohibitive cost of transferring large embedding tables. We propose CrossAdapt, a two-stage framework for efficient cross-architecture knowledge transfer. The offline stage enables rapid embedding transfer via dimension-adaptive projections without iterative training, combined with progressive network distillation and strategic sampling to reduce computational cost. The online stage introduces asymmetric co-distillation, where students update frequently while teachers update infrequently, together with a distribution-aware adaptation mechanism that dynamically balances historical knowledge preservation and fast adaptation to evolving data. Experiments on three public datasets show that CrossAdapt achieves 0.27-0.43% AUC improvements while reducing training time by 43-71%. Large-scale deployment on Tencent WeChat Channels (~10M daily samples) further demonstrates its effectiveness, significantly mitigating AUC degradation, LogLoss increase, and prediction bias compared to standard distillation baselines.
Augmenting Multi-Agent Communication with State Delta Trajectory
Jun 24, 2025Multi-agent techniques such as role playing or multi-turn debates have been shown to be effective in improving the performance of large language models (LLMs) in downstream tasks. Despite their differences in workflows, existing LLM-based multi-agent systems mostly use natural language for agent communication. While this is appealing for its simplicity and interpretability, it also introduces inevitable information loss as one model must down sample its continuous state vectors to concrete tokens before transferring them to the other model. Such losses are particularly significant when the information to transfer is not simple facts, but reasoning logics or abstractive thoughts. To tackle this problem, we propose a new communication protocol that transfers both natural language tokens and token-wise state transition trajectory from one agent to another. Particularly, compared to the actual state value, we find that the sequence of state changes in LLMs after generating each token can better reflect the information hidden behind the inference process, so we propose a State Delta Encoding (SDE) method to represent state transition trajectories. The experimental results show that multi-agent systems with SDE achieve SOTA performance compared to other communication protocols, particularly in tasks that involve complex reasoning. This shows the potential of communication augmentation for LLM-based multi-agent systems.
Intelligence Test
Feb 26, 2025How does intelligence emerge? We propose that intelligence is not a sudden gift or random occurrence, but rather a necessary trait for species to survive through Natural Selection. If a species passes the test of Natural Selection, it demonstrates the intelligence to survive in nature. Extending this perspective, we introduce Intelligence Test, a method to quantify the intelligence of any subject on any task. Like how species evolve by trial and error, Intelligence Test quantifies intelligence by the number of failed attempts before success. Fewer failures correspond to higher intelligence. When the expectation and variance of failure counts are both finite, it signals the achievement of an autonomous level of intelligence. Using Intelligence Test, we comprehensively evaluate existing AI systems. Our results show that while AI systems achieve a level of autonomy in simple tasks, they are still far from autonomous in more complex tasks, such as vision, search, recommendation, and language. While scaling model size might help, this would come at an astronomical cost. Projections suggest that achieving general autonomy would require unimaginable $10^{26}$ parameters. Even if Moore's Law continuously holds, such a parameter scale would take $70$ years. This staggering cost highlights the complexity of human tasks and the inadequacies of current AI. To further understand this phenomenon, we conduct a theoretical analysis. Our simulations suggest that human tasks possess a criticality property. As a result, autonomy requires a deep understanding of the task's underlying mechanisms. Current AI, however, does not fully grasp these mechanisms and instead relies on superficial mimicry, making it difficult to reach an autonomous level. We believe Intelligence Test can not only guide the future development of AI but also offer profound insights into the intelligence of humans ourselves.
AdaS&S: a One-Shot Supernet Approach for Automatic Embedding Size Search in Deep Recommender System
Nov 12, 2024



Deep Learning Recommendation Model(DLRM)s utilize the embedding layer to represent various categorical features. Traditional DLRMs adopt unified embedding size for all features, leading to suboptimal performance and redundant parameters. Thus, lots of Automatic Embedding size Search (AES) works focus on obtaining mixed embedding sizes with strong model performance. However, previous AES works can hardly address several challenges together: (1) The search results of embedding sizes are unstable; (2) Recommendation effect with AES results is unsatisfactory; (3) Memory cost of embeddings is uncontrollable. To address these challenges, we propose a novel one-shot AES framework called AdaS&S, in which a supernet encompassing various candidate embeddings is built and AES is performed as searching network architectures within it. Our framework contains two main stages: In the first stage, we decouple training parameters from searching embedding sizes, and propose the Adaptive Sampling method to yield a well-trained supernet, which further helps to produce stable AES results. In the second stage, to obtain embedding sizes that benefits the model effect, we design a reinforcement learning search process which utilizes the supernet trained previously. Meanwhile, to adapt searching to specific resource constraint, we introduce the resource competition penalty to balance the model effectiveness and memory cost of embeddings. We conduct extensive experiments on public datasets to show the superiority of AdaS&S. Our method could improve AUC by about 0.3% while saving about 20% of model parameters. Empirical analysis also shows that the stability of searching results in AdaS&S significantly exceeds other methods.
An Automatic and Cost-Efficient Peer-Review Framework for Language Generation Evaluation
Oct 16, 2024
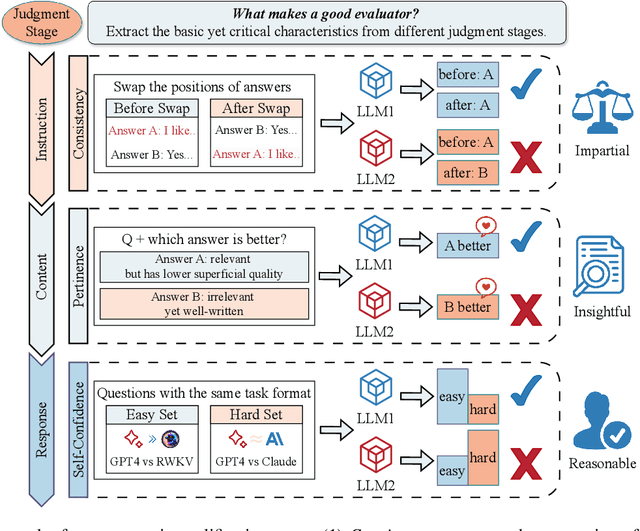

With the rapid development of large language models (LLMs), how to efficiently evaluate them has become an important research question. Existing evaluation methods often suffer from high costs, limited test formats, the need of human references, and systematic evaluation biases. To address these limitations, our study introduces the Auto-PRE, an automatic LLM evaluation framework based on peer review. In contrast to previous studies that rely on human annotations, Auto-PRE selects evaluator LLMs automatically based on their inherent traits including consistency, self-confidence, and pertinence. We conduct extensive experiments on three tasks: summary generation, non-factoid question-answering, and dialogue generation. Experimental results indicate our Auto-PRE achieves state-of-the-art performance at a lower cost. Moreover, our study highlights the impact of prompt strategies and evaluation formats on evaluation performance, offering guidance for method optimization in the future.
LeKUBE: A Legal Knowledge Update BEnchmark
Jul 19, 2024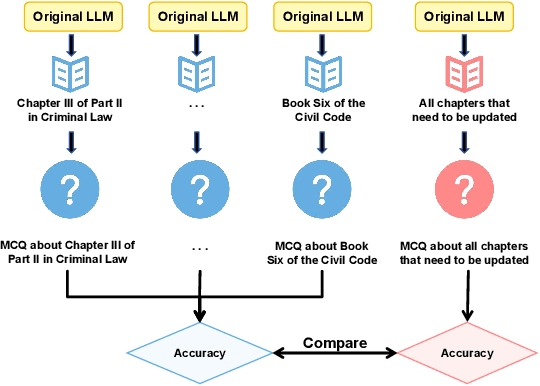
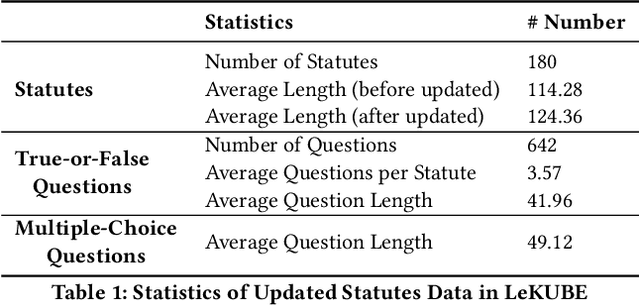
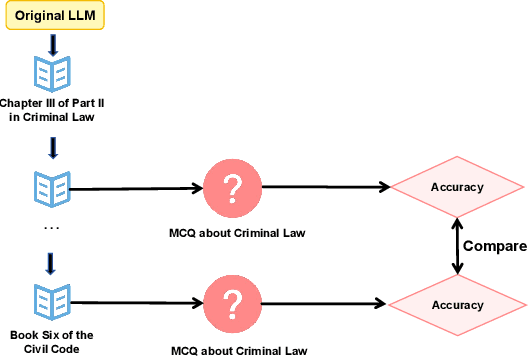
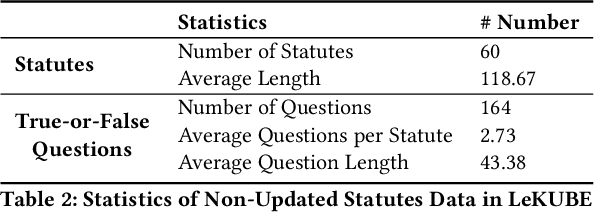
Recent advances in Large Language Models (LLMs) have significantly shaped the applications of AI in multiple fields, including the studies of legal intelligence. Trained on extensive legal texts, including statutes and legal documents, the legal LLMs can capture important legal knowledge/concepts effectively and provide important support for downstream legal applications such as legal consultancy. Yet, the dynamic nature of legal statutes and interpretations also poses new challenges to the use of LLMs in legal applications. Particularly, how to update the legal knowledge of LLMs effectively and efficiently has become an important research problem in practice. Existing benchmarks for evaluating knowledge update methods are mostly designed for the open domain and cannot address the specific challenges of the legal domain, such as the nuanced application of new legal knowledge, the complexity and lengthiness of legal regulations, and the intricate nature of legal reasoning. To address this gap, we introduce the Legal Knowledge Update BEnchmark, i.e. LeKUBE, which evaluates knowledge update methods for legal LLMs across five dimensions. Specifically, we categorize the needs of knowledge updates in the legal domain with the help of legal professionals, and then hire annotators from law schools to create synthetic updates to the Chinese Criminal and Civil Code as well as sets of questions of which the answers would change after the updates. Through a comprehensive evaluation of state-of-the-art knowledge update methods, we reveal a notable gap between existing knowledge update methods and the unique needs of the legal domain, emphasizing the need for further research and development of knowledge update mechanisms tailored for legal LLMs.
Prompt Refinement with Image Pivot for Text-to-Image Generation
Jun 28, 2024
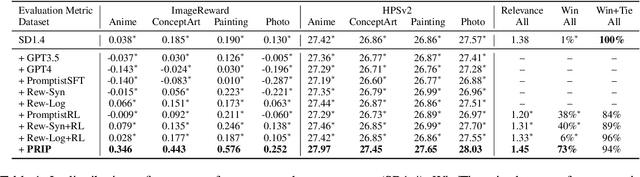
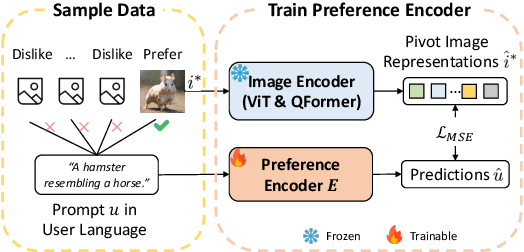
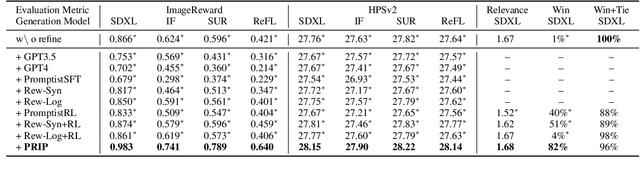
For text-to-image generation, automatically refining user-provided natural language prompts into the keyword-enriched prompts favored by systems is essential for the user experience. Such a prompt refinement process is analogous to translating the prompt from "user languages" into "system languages". However, the scarcity of such parallel corpora makes it difficult to train a prompt refinement model. Inspired by zero-shot machine translation techniques, we introduce Prompt Refinement with Image Pivot (PRIP). PRIP innovatively uses the latent representation of a user-preferred image as an intermediary "pivot" between the user and system languages. It decomposes the refinement process into two data-rich tasks: inferring representations of user-preferred images from user languages and subsequently translating image representations into system languages. Thus, it can leverage abundant data for training. Extensive experiments show that PRIP substantially outperforms a wide range of baselines and effectively transfers to unseen systems in a zero-shot manner.
ReChorus2.0: A Modular and Task-Flexible Recommendation Library
May 28, 2024
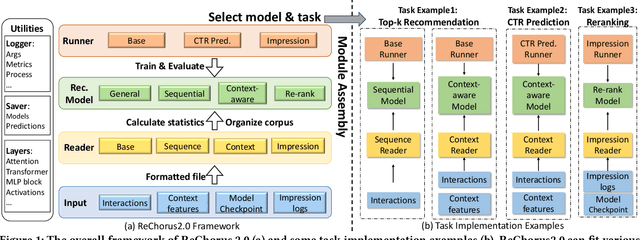
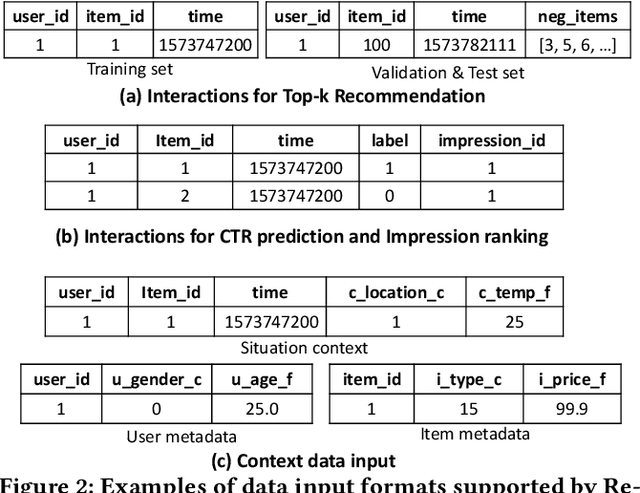

With the applications of recommendation systems rapidly expanding, an increasing number of studies have focused on every aspect of recommender systems with different data inputs, models, and task settings. Therefore, a flexible library is needed to help researchers implement the experimental strategies they require. Existing open libraries for recommendation scenarios have enabled reproducing various recommendation methods and provided standard implementations. However, these libraries often impose certain restrictions on data and seldom support the same model to perform different tasks and input formats, limiting users from customized explorations. To fill the gap, we propose ReChorus2.0, a modular and task-flexible library for recommendation researchers. Based on ReChorus, we upgrade the supported input formats, models, and training&evaluation strategies to help realize more recommendation tasks with more data types. The main contributions of ReChorus2.0 include: (1) Realization of complex and practical tasks, including reranking and CTR prediction tasks; (2) Inclusion of various context-aware and rerank recommenders; (3) Extension of existing and new models to support different tasks with the same models; (4) Support of highly-customized input with impression logs, negative items, or click labels, as well as user, item, and situation contexts. To summarize, ReChorus2.0 serves as a comprehensive and flexible library better aligning with the practical problems in the recommendation scenario and catering to more diverse research needs. The implementation and detailed tutorials of ReChorus2.0 can be found at https://github.com/THUwangcy/ReChorus.
Introducing EEG Analyses to Help Personal Music Preference Prediction
Apr 24, 2024Nowadays, personalized recommender systems play an increasingly important role in music scenarios in our daily life with the preference prediction ability. However, existing methods mainly rely on users' implicit feedback (e.g., click, dwell time) which ignores the detailed user experience. This paper introduces Electroencephalography (EEG) signals to personal music preferences as a basis for the personalized recommender system. To realize collection in daily life, we use a dry-electrodes portable device to collect data. We perform a user study where participants listen to music and record preferences and moods. Meanwhile, EEG signals are collected with a portable device. Analysis of the collected data indicates a significant relationship between music preference, mood, and EEG signals. Furthermore, we conduct experiments to predict personalized music preference with the features of EEG signals. Experiments show significant improvement in rating prediction and preference classification with the help of EEG. Our work demonstrates the possibility of introducing EEG signals in personal music preference with portable devices. Moreover, our approach is not restricted to the music scenario, and the EEG signals as explicit feedback can be used in personalized recommendation tasks.
Aiming at the Target: Filter Collaborative Information for Cross-Domain Recommendation
Mar 29, 2024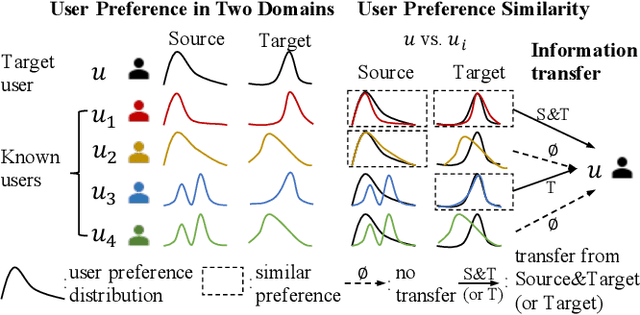
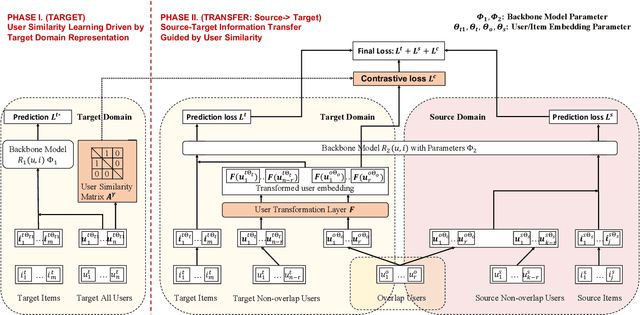
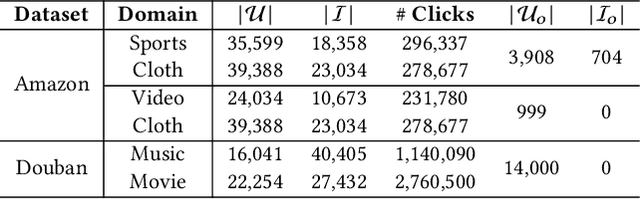
Cross-domain recommender (CDR) systems aim to enhance the performance of the target domain by utilizing data from other related domains. However, irrelevant information from the source domain may instead degrade target domain performance, which is known as the negative transfer problem. There have been some attempts to address this problem, mostly by designing adaptive representations for overlapped users. Whereas, representation adaptions solely rely on the expressive capacity of the CDR model, lacking explicit constraint to filter the irrelevant source-domain collaborative information for the target domain. In this paper, we propose a novel Collaborative information regularized User Transformation (CUT) framework to tackle the negative transfer problem by directly filtering users' collaborative information. In CUT, user similarity in the target domain is adopted as a constraint for user transformation learning to filter the user collaborative information from the source domain. CUT first learns user similarity relationships from the target domain. Then, source-target information transfer is guided by the user similarity, where we design a user transformation layer to learn target-domain user representations and a contrastive loss to supervise the user collaborative information transferred. The results show significant performance improvement of CUT compared with SOTA single and cross-domain methods. Further analysis of the target-domain results illustrates that CUT can effectively alleviate the negative transfer problem.