 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale
May 29, 2026Modern recommendation systems predominantly train retrieval and ranking as separate models despite both increasingly relying on large transformers encoding the same user behavior data, duplicating parameters, compute, and serving cost. Prior work unifies the model architecture but not the full pipeline: input formats, training procedures, and serving stacks remain fragmented across stages. We present UniPinRec, which achieves full-stack unification of retrieval and ranking at Pinterest: one input format, one model, one training stage, deployed within existing serving infrastructure. A shared transformer encodes the user action sequence into candidate-independent representations that branch into retrieval (ANN dot-product) and ranking (cross-attention) via task-specific heads. Three ideas make this work: (1) Masked Action Modeling (MAM) eliminates interleaving, enabling weight sharing without doubling context length; (2) Blended training examples pair action sequences with feedview impression slates to satisfy both objectives jointly; (3) Cross-stage KV cache sharing reuses user-history computation from retrieval for ranking, reducing total FLOPs versus serving two independent models. Deployed in the Pinterest core surfaces, UniPinRec delivers approximately +1% online engagement lift while cutting end-to-end serving latency by 11.1% and lifting QPS by 63.6%. To our knowledge, this is the first full-stack unification of retrieval and ranking, covering inputs, model, training and serving, deployed in a production recommendation system.
RepoMirage: Probing Repository Context Reasoning in Code Agents with Perturbations
May 25, 2026Code agents are currently having skillful performance on repository-level software engineering benchmarks, but it remains unclear whether success on end-to-end tasks such as issue resolution truly reflects repository context reasoning, the ability to identify the task-relevant information across multiple files and reason over the relations among them. To investigate this question, we introduce RepoMirage, a two-stage evaluation suite built on SWE-Bench Verified that adopts perturbation as a diagnostic tool to increase the demand for context reasoning by transforming how the repository is exposed. First, RepoMirage-Perturb applies three types of semantics-preserving repository-level perturbations, revealing a clear performance drop when correct solving requires broader context access. RepoMirage-Extend further turns perturbation-targeted structural bottlenecks into explicit tasks beyond issue resolution, where the average performance declines from 66.8% in the original setting to 25.3%, indicating a significant deficiency in repository context reasoning. Further trajectory analysis reveals an exploration drift, where agents access broader repository context but fail to turn it into effective structure information. Motivated by this observation, we propose RepoAnchor, a structure-first prototype workflow that separates repository exploration from downstream problem solving, and show that explicit structural scaffolding yields notable gains. These results uncover an previously overlooked gap in repository context reasoning for code agents and suggest that stronger structure-aware methods are potential to improve them.
JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
Jan 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard paradigm for reasoning in Large Language Models. However, optimizing solely for final-answer correctness often drives models into aimless, verbose exploration, where they rely on exhaustive trial-and-error tactics rather than structured planning to reach solutions. While heuristic constraints like length penalties can reduce verbosity, they often truncate essential reasoning steps, creating a difficult trade-off between efficiency and verification. In this paper, we argue that discriminative capability is a prerequisite for efficient generation: by learning to distinguish valid solutions, a model can internalize a guidance signal that prunes the search space. We propose JudgeRLVR, a two-stage judge-then-generate paradigm. In the first stage, we train the model to judge solution responses with verifiable answers. In the second stage, we fine-tune the same model with vanilla generating RLVR initialized from the judge. Compared to Vanilla RLVR using the same math-domain training data, JudgeRLVR achieves a better quality--efficiency trade-off for Qwen3-30B-A3B: on in-domain math, it delivers about +3.7 points average accuracy gain with -42\% average generation length; on out-of-domain benchmarks, it delivers about +4.5 points average accuracy improvement, demonstrating enhanced generalization.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Will AI Trade? A Computational Inversion of the No-Trade Theorem
Dec 17, 2025Classic no-trade theorems attribute trade to heterogeneous beliefs. We re-examine this conclusion for AI agents, asking if trade can arise from computational limitations, under common beliefs. We model agents' bounded computational rationality within an unfolding game framework, where computational power determines the complexity of its strategy. Our central finding inverts the classic paradigm: a stable no-trade outcome (Nash equilibrium) is reached only when "almost rational" agents have slightly different computational power. Paradoxically, when agents possess identical power, they may fail to converge to equilibrium, resulting in persistent strategic adjustments that constitute a form of trade. This instability is exacerbated if agents can strategically under-utilize their computational resources, which eliminates any chance of equilibrium in Matching Pennies scenarios. Our results suggest that the inherent computational limitations of AI agents can lead to situations where equilibrium is not reached, creating a more lively and unpredictable trade environment than traditional models would predict.
SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model
Oct 14, 2025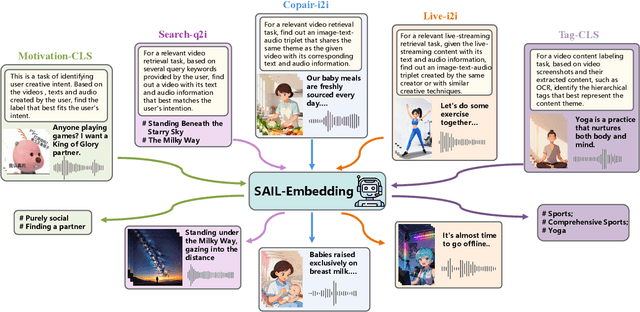

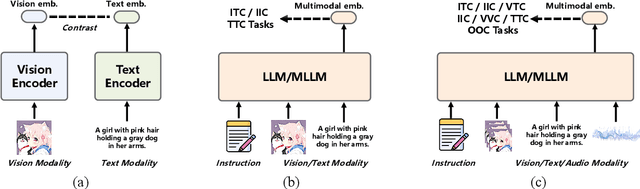
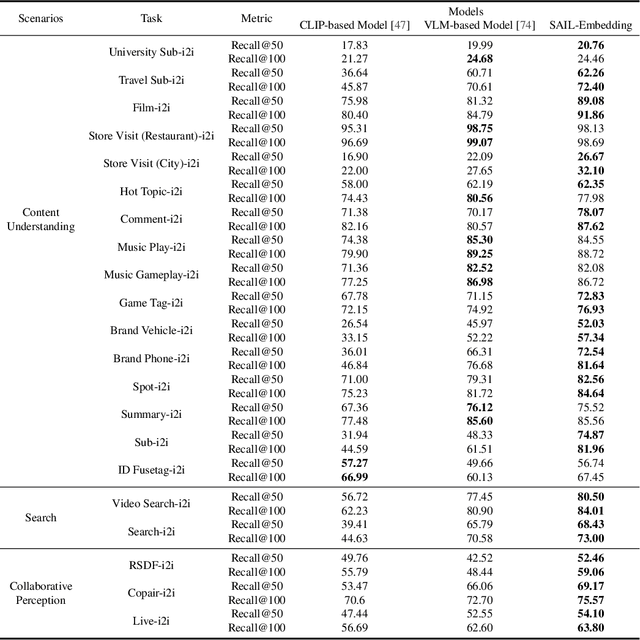
Multimodal embedding models aim to yield informative unified representations that empower diverse cross-modal tasks. Despite promising developments in the evolution from CLIP-based dual-tower architectures to large vision-language models, prior works still face unavoidable challenges in real-world applications and business scenarios, such as the limited modality support, unstable training mechanisms, and industrial domain gaps. In this work, we introduce SAIL-Embedding, an omni-modal embedding foundation model that addresses these issues through tailored training strategies and architectural design. In the optimization procedure, we propose a multi-stage training scheme to boost the multifaceted effectiveness of representation learning. Specifically, the content-aware progressive training aims to enhance the model's adaptability to diverse downstream tasks and master enriched cross-modal proficiency. The collaboration-aware recommendation enhancement training further adapts multimodal representations for recommendation scenarios by distilling knowledge from sequence-to-item and ID-to-item embeddings while mining user historical interests. Concurrently, we develop the stochastic specialization and dataset-driven pattern matching to strengthen model training flexibility and generalizability. Experimental results show that SAIL-Embedding achieves SOTA performance compared to other methods in different retrieval tasks. In online experiments across various real-world scenarios integrated with our model, we observe a significant increase in Lifetime (LT), which is a crucial indicator for the recommendation experience. For instance, the model delivers the 7-day LT gain of +0.158% and the 14-day LT gain of +0.144% in the Douyin-Selected scenario. For the Douyin feed rank model, the match features produced by SAIL-Embedding yield a +0.08% AUC gain.
IDA-Bench: Evaluating LLMs on Interactive Guided Data Analysis
May 23, 2025Large Language Models (LLMs) show promise as data analysis agents, but existing benchmarks overlook the iterative nature of the field, where experts' decisions evolve with deeper insights of the dataset. To address this, we introduce IDA-Bench, a novel benchmark evaluating LLM agents in multi-round interactive scenarios. Derived from complex Kaggle notebooks, tasks are presented as sequential natural language instructions by an LLM-simulated user. Agent performance is judged by comparing its final numerical output to the human-derived baseline. Initial results show that even state-of-the-art coding agents (like Claude-3.7-thinking) succeed on < 50% of the tasks, highlighting limitations not evident in single-turn tests. This work underscores the need to improve LLMs' multi-round capabilities for building more reliable data analysis agents, highlighting the necessity of achieving a balance between instruction following and reasoning.
V2I-Calib: A Novel Calibration Approach for Collaborative Vehicle and Infrastructure LiDAR Systems
Jul 14, 2024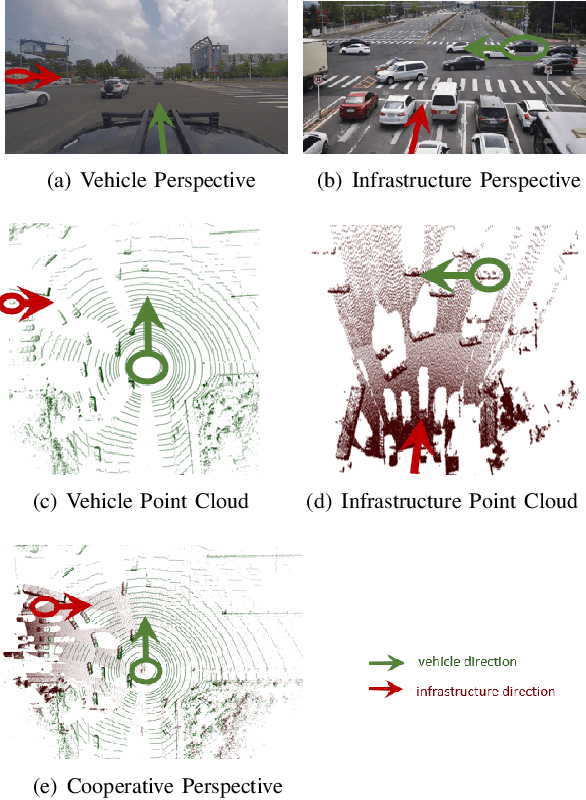
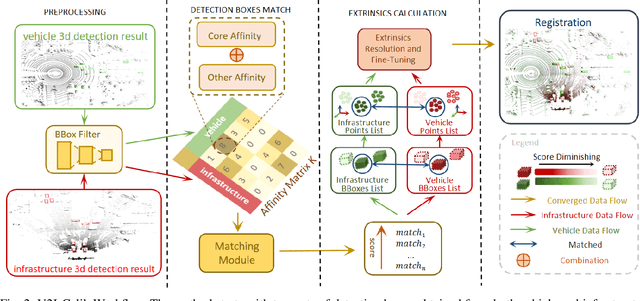
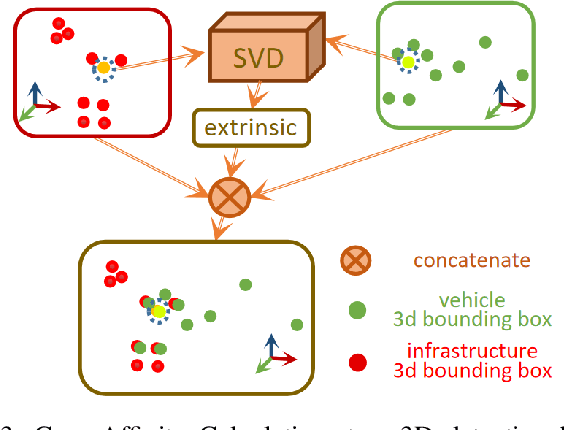
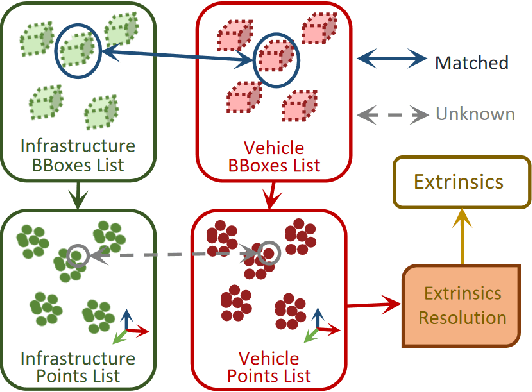
Cooperative vehicle and infrastructure LiDAR systems hold great potential, yet their implementation faces numerous challenges. Calibration of LiDAR systems across heterogeneous vehicle and infrastructure endpoints is a critical step to ensure the accuracy and consistency of perception system data, necessitating calibration methods that are real-time and stable. To this end, this paper introduces a novel calibration method for cooperative vehicle and road infrastructure LiDAR systems, which exploits spatial association information between detection boxes. The method centers around a novel Overall IoU metric that reflects the correlation of targets between vehicle and infrastructure, enabling real-time monitoring of calibration results. We search for common matching boxes between vehicle and infrastructure nodes by constructing an affinity matrix. Subsequently, these matching boxes undergo extrinsic parameter computation and optimization. Comparative and ablation experiments on the DAIR-V2X dataset confirm the superiority of our method. To better reflect the differences in calibration results, we have categorized the calibration tasks on the DAIR-V2X dataset based on their level of difficulty, enriching the dataset's utility for future research. Our project is available at https://github.com/MassimoQu/v2i-calib .
ReChorus2.0: A Modular and Task-Flexible Recommendation Library
May 28, 2024
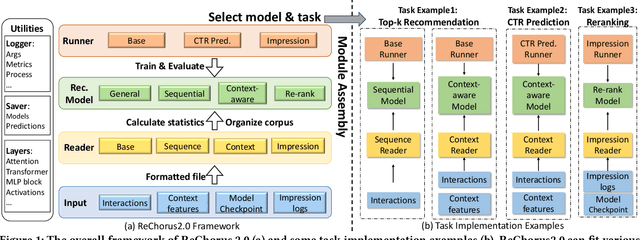
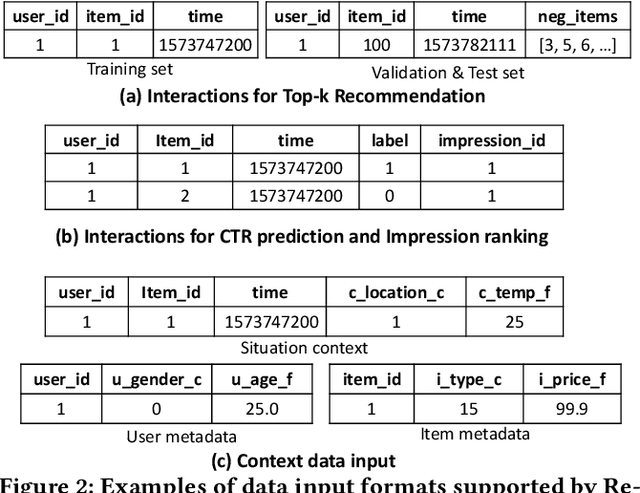

With the applications of recommendation systems rapidly expanding, an increasing number of studies have focused on every aspect of recommender systems with different data inputs, models, and task settings. Therefore, a flexible library is needed to help researchers implement the experimental strategies they require. Existing open libraries for recommendation scenarios have enabled reproducing various recommendation methods and provided standard implementations. However, these libraries often impose certain restrictions on data and seldom support the same model to perform different tasks and input formats, limiting users from customized explorations. To fill the gap, we propose ReChorus2.0, a modular and task-flexible library for recommendation researchers. Based on ReChorus, we upgrade the supported input formats, models, and training&evaluation strategies to help realize more recommendation tasks with more data types. The main contributions of ReChorus2.0 include: (1) Realization of complex and practical tasks, including reranking and CTR prediction tasks; (2) Inclusion of various context-aware and rerank recommenders; (3) Extension of existing and new models to support different tasks with the same models; (4) Support of highly-customized input with impression logs, negative items, or click labels, as well as user, item, and situation contexts. To summarize, ReChorus2.0 serves as a comprehensive and flexible library better aligning with the practical problems in the recommendation scenario and catering to more diverse research needs. The implementation and detailed tutorials of ReChorus2.0 can be found at https://github.com/THUwangcy/ReChorus.