 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey on algorithms for Nash equilibria in finite normal-form games
Dec 18, 2023Nash equilibrium is one of the most influential solution concepts in game theory. With the development of computer science and artificial intelligence, there is an increasing demand on Nash equilibrium computation, especially for Internet economics and multi-agent learning. This paper reviews various algorithms computing the Nash equilibrium and its approximation solutions in finite normal-form games from both theoretical and empirical perspectives. For the theoretical part, we classify algorithms in the literature and present basic ideas on algorithm design and analysis. For the empirical part, we present a comprehensive comparison on the algorithms in the literature over different kinds of games. Based on these results, we provide practical suggestions on implementations and uses of these algorithms. Finally, we present a series of open problems from both theoretical and practical considerations.
Ask more, know better: Reinforce-Learned Prompt Questions for Decision Making with Large Language Models
Oct 27, 2023Large language models (LLMs) demonstrate their promise in tackling complicated practical challenges by combining action-based policies with chain of thought (CoT) reasoning. Having high-quality prompts on hand, however, is vital to the framework's effectiveness. Currently, these prompts are handcrafted utilizing extensive human labor, resulting in CoT policies that frequently fail to generalize. Human intervention is also required in order to develop grounding functions that ensure low-level controllers appropriately process CoT reasoning. In this paper, we take the first step towards a fully integrated end-to-end framework for task-solving in real settings employing complicated reasoning. To that purpose, we offer a new leader-follower bilevel framework capable of learning to ask relevant questions (prompts) and subsequently undertaking reasoning to guide the learning of actions to be performed in an environment. A good prompt should make introspective revisions based on historical findings, leading the CoT to consider the anticipated goals. A prompt-generator policy has its own aim in our system, allowing it to adapt to the action policy and automatically root the CoT process towards outputs that lead to decisive, high-performing actions. Meanwhile, the action policy is learning how to use the CoT outputs to take specific actions. Our empirical data reveal that our system outperforms leading methods in agent learning benchmarks such as Overcooked and FourRoom.
Learning Risk-Averse Equilibria in Multi-Agent Systems
May 30, 2022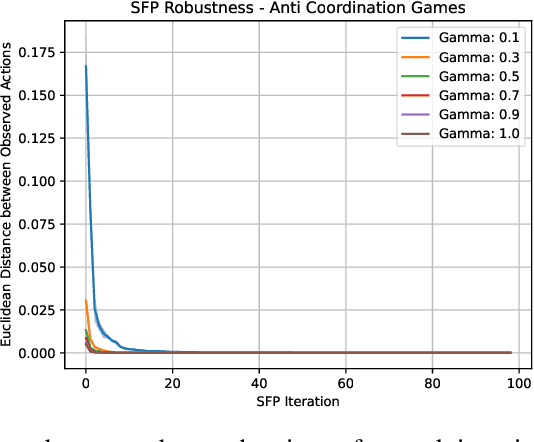
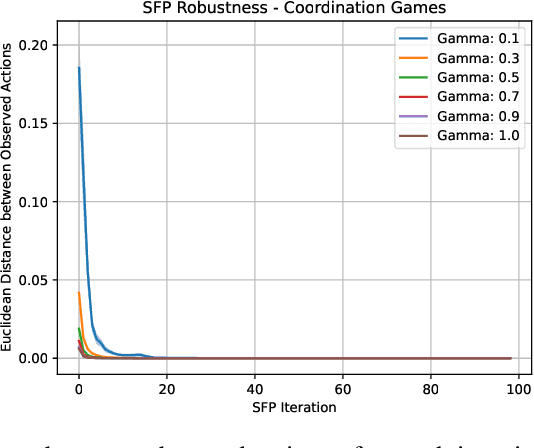
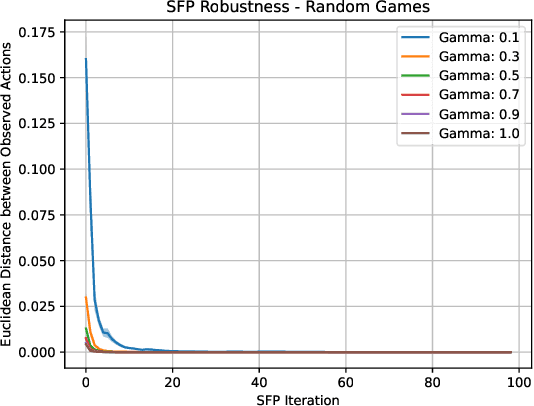
In multi-agent systems, intelligent agents are tasked with making decisions that have optimal outcomes when the actions of the other agents are as expected, whilst also being prepared for unexpected behaviour. In this work, we introduce a new risk-averse solution concept that allows the learner to accommodate unexpected actions by finding the minimum variance strategy given any level of expected return. We prove the existence of such a risk-averse equilibrium, and propose one fictitious-play type learning algorithm for smaller games that enjoys provable convergence guarantees in certain games classes (e.g., zero-sum or potential). Furthermore, we propose an approximation method for larger games based on iterative population-based training that generates a population of risk-averse agents. Empirically, our equilibrium is shown to be able to reduce the reward variance, specifically in the sense that off-equilibrium behaviour has a far smaller impact on our risk-averse agents in comparison to playing other equilibrium solutions. Importantly, we show that our population of agents that approximate a risk-averse equilibrium is particularly effective in the presence of unseen opposing populations, especially in the case of guaranteeing a minimal level of performance which is critical to safety-aware multi-agent systems.
Online Markov Decision Processes with Non-oblivious Strategic Adversary
Oct 08, 2021
We study a novel setting in Online Markov Decision Processes (OMDPs) where the loss function is chosen by a non-oblivious strategic adversary who follows a no-external regret algorithm. In this setting, we first demonstrate that MDP-Expert, an existing algorithm that works well with oblivious adversaries can still apply and achieve a policy regret bound of $\mathcal{O}(\sqrt{T \log(L)}+\tau^2\sqrt{ T \log(|A|)})$ where $L$ is the size of adversary's pure strategy set and $|A|$ denotes the size of agent's action space. Considering real-world games where the support size of a NE is small, we further propose a new algorithm: MDP-Online Oracle Expert (MDP-OOE), that achieves a policy regret bound of $\mathcal{O}(\sqrt{T\log(L)}+\tau^2\sqrt{ T k \log(k)})$ where $k$ depends only on the support size of the NE. MDP-OOE leverages the key benefit of Double Oracle in game theory and thus can solve games with prohibitively large action space. Finally, to better understand the learning dynamics of no-regret methods, under the same setting of no-external regret adversary in OMDPs, we introduce an algorithm that achieves last-round convergence result to a NE. To our best knowledge, this is first work leading to the last iteration result in OMDPs.
On the Complexity of Computing Markov Perfect Equilibrium in General-Sum Stochastic Games
Sep 04, 2021Similar to the role of Markov decision processes in reinforcement learning, Stochastic Games (SGs) lay the foundation for the study of multi-agent reinforcement learning (MARL) and sequential agent interactions. In this paper, we derive that computing an approximate Markov Perfect Equilibrium (MPE) in a finite-state discounted Stochastic Game within the exponential precision is \textbf{PPAD}-complete. We adopt a function with a polynomially bounded description in the strategy space to convert the MPE computation to a fixed-point problem, even though the stochastic game may demand an exponential number of pure strategies, in the number of states, for each agent. The completeness result follows the reduction of the fixed-point problem to {\sc End of the Line}. Our results indicate that finding an MPE in SGs is highly unlikely to be \textbf{NP}-hard unless \textbf{NP}=\textbf{co-NP}. Our work offers confidence for MARL research to study MPE computation on general-sum SGs and to develop fruitful algorithms as currently on zero-sum SGs.
Settling the Variance of Multi-Agent Policy Gradients
Aug 20, 2021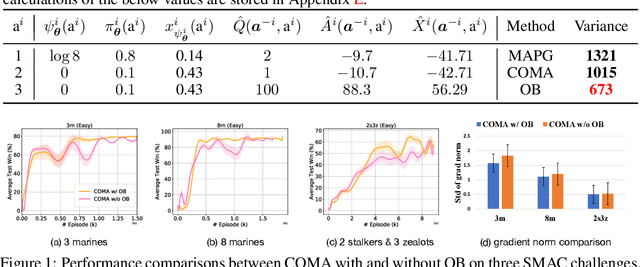
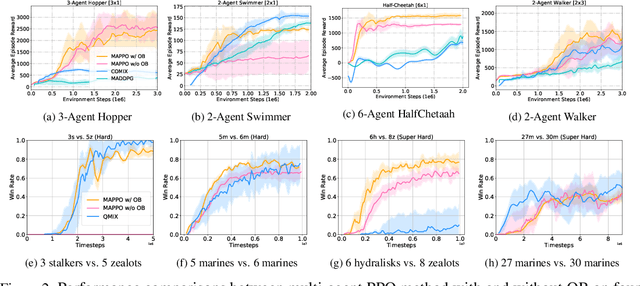

Policy gradient (PG) methods are popular reinforcement learning (RL) methods where a baseline is often applied to reduce the variance of gradient estimates. In multi-agent RL (MARL), although the PG theorem can be naturally extended, the effectiveness of multi-agent PG (MAPG) methods degrades as the variance of gradient estimates increases rapidly with the number of agents. In this paper, we offer a rigorous analysis of MAPG methods by, firstly, quantifying the contributions of the number of agents and agents' explorations to the variance of MAPG estimators. Based on this analysis, we derive the optimal baseline (OB) that achieves the minimal variance. In comparison to the OB, we measure the excess variance of existing MARL algorithms such as vanilla MAPG and COMA. Considering using deep neural networks, we also propose a surrogate version of OB, which can be seamlessly plugged into any existing PG methods in MARL. On benchmarks of Multi-Agent MuJoCo and StarCraft challenges, our OB technique effectively stabilises training and improves the performance of multi-agent PPO and COMA algorithms by a significant margin.
Online Double Oracle
Mar 16, 2021
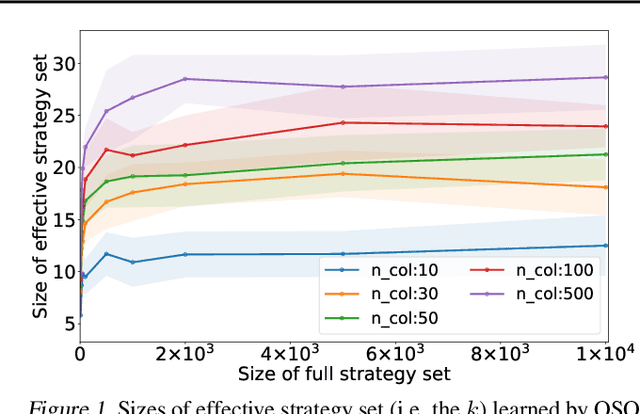
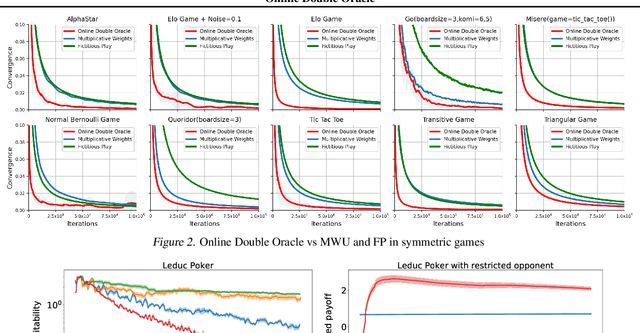
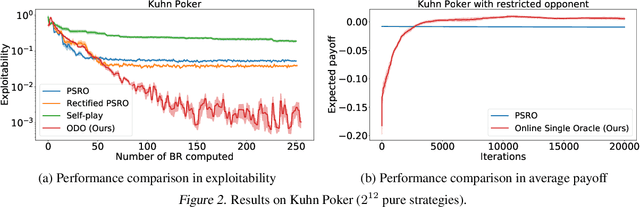
Solving strategic games whose action space is prohibitively large is a critical yet under-explored topic in economics, computer science and artificial intelligence. This paper proposes new learning algorithms in two-player zero-sum games where the number of pure strategies is huge or even infinite. Specifically, we combine no-regret analysis from online learning with double oracle methods from game theory. Our method -- \emph{Online Double Oracle (ODO)} -- achieves the regret bound of $\mathcal{O}(\sqrt{T k \log(k)})$ in self-play setting where $k$ is NOT the size of the game, but rather the size of \emph{effective strategy set} that is linearly dependent on the support size of the Nash equilibrium. On tens of different real-world games, including Leduc Poker that contains $3^{936}$ pure strategies, our methods outperform no-regret algorithms and double oracle methods by a large margin, both in convergence rate to Nash equilibrium and average payoff against strategic adversary.
Modelling Behavioural Diversity for Learning in Open-Ended Games
Mar 14, 2021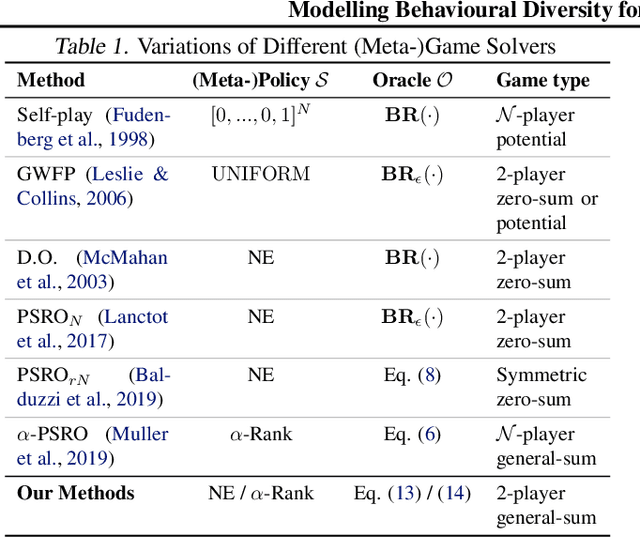

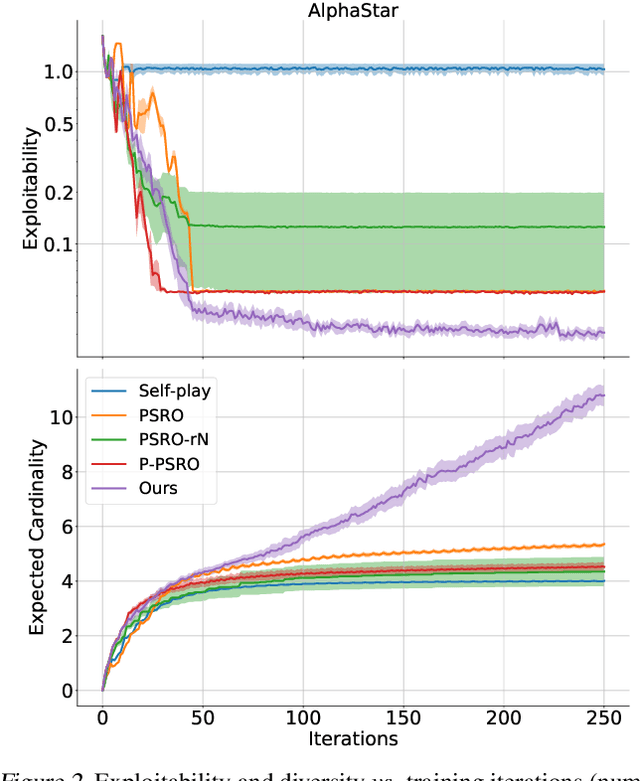
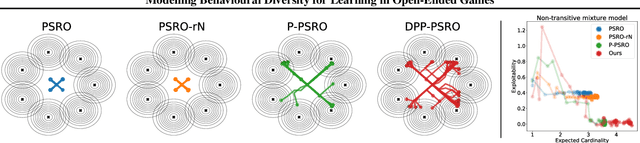
Promoting behavioural diversity is critical for solving games with non-transitive dynamics where strategic cycles exist, and there is no consistent winner (e.g., Rock-Paper-Scissors). Yet, there is a lack of rigorous treatment for defining diversity and constructing diversity-aware learning dynamics. In this work, we offer a geometric interpretation of behavioural diversity in games and introduce a novel diversity metric based on \emph{determinantal point processes} (DPP). By incorporating the diversity metric into best-response dynamics, we develop \emph{diverse fictitious play} and \emph{diverse policy-space response oracle} for solving normal-form games and open-ended games. We prove the uniqueness of the diverse best response and the convergence of our algorithms on two-player games. Importantly, we show that maximising the DPP-based diversity metric guarantees to enlarge the \emph{gamescape} -- convex polytopes spanned by agents' mixtures of strategies. To validate our diversity-aware solvers, we test on tens of games that show strong non-transitivity. Results suggest that our methods achieve much lower exploitability than state-of-the-art solvers by finding effective and diverse strategies.