 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey on algorithms for Nash equilibria in finite normal-form games
Dec 18, 2023Nash equilibrium is one of the most influential solution concepts in game theory. With the development of computer science and artificial intelligence, there is an increasing demand on Nash equilibrium computation, especially for Internet economics and multi-agent learning. This paper reviews various algorithms computing the Nash equilibrium and its approximation solutions in finite normal-form games from both theoretical and empirical perspectives. For the theoretical part, we classify algorithms in the literature and present basic ideas on algorithm design and analysis. For the empirical part, we present a comprehensive comparison on the algorithms in the literature over different kinds of games. Based on these results, we provide practical suggestions on implementations and uses of these algorithms. Finally, we present a series of open problems from both theoretical and practical considerations.
No-regret Learning in Repeated First-Price Auctions with Budget Constraints
May 29, 2022
Recently the online advertising market has exhibited a gradual shift from second-price auctions to first-price auctions. Although there has been a line of works concerning online bidding strategies in first-price auctions, it still remains open how to handle budget constraints in the problem. In the present paper, we initiate the study for a buyer with budgets to learn online bidding strategies in repeated first-price auctions. We propose an RL-based bidding algorithm against the optimal non-anticipating strategy under stationary competition. Our algorithm obtains $\widetilde O(\sqrt T)$-regret if the bids are all revealed at the end of each round. With the restriction that the buyer only sees the winning bid after each round, our modified algorithm obtains $\widetilde O(T^{\frac{7}{12}})$-regret by techniques developed from survival analysis. Our analysis extends to the more general scenario where the buyer has any bounded instantaneous utility function with regrets of the same order.
Cooperative Multi-Agent Transfer Learning with Level-Adaptive Credit Assignment
Jun 03, 2021
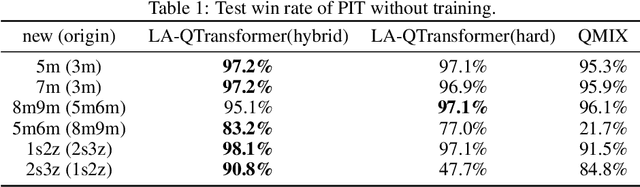
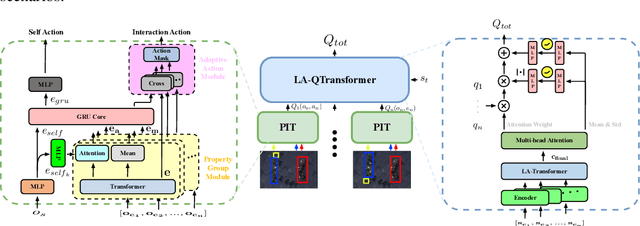
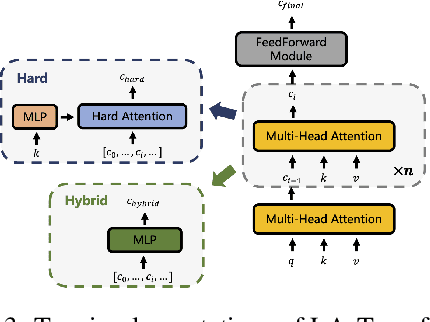
Extending transfer learning to cooperative multi-agent reinforcement learning (MARL) has recently received much attention. In contrast to the single-agent setting, the coordination indispensable in cooperative MARL constrains each agent's policy. However, existing transfer methods focus exclusively on agent policy and ignores coordination knowledge. We propose a new architecture that realizes robust coordination knowledge transfer through appropriate decomposition of the overall coordination into several coordination patterns. We use a novel mixing network named level-adaptive QTransformer (LA-QTransformer) to realize agent coordination that considers credit assignment, with appropriate coordination patterns for different agents realized by a novel level-adaptive Transformer (LA-Transformer) dedicated to the transfer of coordination knowledge. In addition, we use a novel agent network named Population Invariant agent with Transformer (PIT) to realize the coordination transfer in more varieties of scenarios. Extensive experiments in StarCraft II micro-management show that LA-QTransformer together with PIT achieves superior performance compared with state-of-the-art baselines.