 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALLES: A Multi-agent LLMs-based Economic Sandbox with Consumer Preference Alignment
Mar 18, 2026In the real economy, modern decision-making is fundamentally challenged by high-dimensional, multimodal environments, which are further complicated by agent heterogeneity and combinatorial data sparsity. This paper introduces a Multi-Agent Large Language Model-based Economic Sandbox (MALLES), leveraging the inherent generalization capabilities of large-sacle models to establish a unified simulation framework applicable to cross-domain and cross-category scenarios. Central to our approach is a preference learning paradigm in which LLMs are economically aligned via post-training on extensive, heterogeneous transaction records across diverse product categories. This methodology enables the models to internalize and transfer latent consumer preference patterns, thereby mitigating the data sparsity issues prevalent in individual categories. To enhance simulation stability, we implement a mean-field mechanism designed to model the dynamic interactions between the product environment and customer populations, effectively stabilizing sampling processes within high-dimensional decision spaces. Furthermore, we propose a multi-agent discussion framework wherein specialized agents collaboratively process extensive product information. This architecture distributes cognitive load to alleviate single-agent attention bottlenecks and captures critical decision factors through structured dialogue. Experiments demonstrate that our framework achieves significant improvements in product selection accuracy, purchase quantity prediction, and simulation stability compared to existing economic and financial LLM simulation baselines. Our results substantiate the potential of large language models as a foundational pillar for high-fidelity, scalable decision simulation and latter analysis in the real economy based on foundational database.
Enhancing Affine Maximizer Auctions with Correlation-Aware Payment
Feb 10, 2026Affine Maximizer Auctions (AMAs), a generalized mechanism family from VCG, are widely used in automated mechanism design due to their inherent dominant-strategy incentive compatibility (DSIC) and individual rationality (IR). However, as the payment form is fixed, AMA's expressiveness is restricted, especially in distributions where bidders' valuations are correlated. In this paper, we propose Correlation-Aware AMA (CA-AMA), a novel framework that augments AMA with a new correlation-aware payment. We show that any CA-AMA preserves the DSIC property and formalize finding optimal CA-AMA as a constraint optimization problem subject to the IR constraint. Then, we theoretically characterize scenarios where classic AMAs can perform arbitrarily poorly compared to the optimal revenue, while the CA-AMA can reach the optimal revenue. For optimizing CA-AMA, we design a practical two-stage training algorithm. We derive that the target function's continuity and the generalization bound on the degree of deviation from strict IR. Finally, extensive experiments showcase that our algorithm can find an approximate optimal CA-AMA in various distributions with improved revenue and a low degree of violation of IR.
RL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
Ad Insertion in LLM-Generated Responses
Jan 27, 2026Sustainable monetization of Large Language Models (LLMs) remains a critical open challenge. Traditional search advertising, which relies on static keywords, fails to capture the fleeting, context-dependent user intents--the specific information, goods, or services a user seeks--embedded in conversational flows. Beyond the standard goal of social welfare maximization, effective LLM advertising imposes additional requirements on contextual coherence (ensuring ads align semantically with transient user intents) and computational efficiency (avoiding user interaction latency), as well as adherence to ethical and regulatory standards, including preserving privacy and ensuring explicit ad disclosure. Although various recent solutions have explored bidding on token-level and query-level, both categories of approaches generally fail to holistically satisfy this multifaceted set of constraints. We propose a practical framework that resolves these tensions through two decoupling strategies. First, we decouple ad insertion from response generation to ensure safety and explicit disclosure. Second, we decouple bidding from specific user queries by using ``genres'' (high-level semantic clusters) as a proxy. This allows advertisers to bid on stable categories rather than sensitive real-time response, reducing computational burden and privacy risks. We demonstrate that applying the VCG auction mechanism to this genre-based framework yields approximately dominant strategy incentive compatibility (DSIC) and individual rationality (IR), as well as approximately optimal social welfare, while maintaining high computational efficiency. Finally, we introduce an "LLM-as-a-Judge" metric to estimate contextual coherence. Our experiments show that this metric correlates strongly with human ratings (Spearman's $ρ\approx 0.66$), outperforming 80% of individual human evaluators.
Will AI Trade? A Computational Inversion of the No-Trade Theorem
Dec 17, 2025Classic no-trade theorems attribute trade to heterogeneous beliefs. We re-examine this conclusion for AI agents, asking if trade can arise from computational limitations, under common beliefs. We model agents' bounded computational rationality within an unfolding game framework, where computational power determines the complexity of its strategy. Our central finding inverts the classic paradigm: a stable no-trade outcome (Nash equilibrium) is reached only when "almost rational" agents have slightly different computational power. Paradoxically, when agents possess identical power, they may fail to converge to equilibrium, resulting in persistent strategic adjustments that constitute a form of trade. This instability is exacerbated if agents can strategically under-utilize their computational resources, which eliminates any chance of equilibrium in Matching Pennies scenarios. Our results suggest that the inherent computational limitations of AI agents can lead to situations where equilibrium is not reached, creating a more lively and unpredictable trade environment than traditional models would predict.
IDA-Bench: Evaluating LLMs on Interactive Guided Data Analysis
May 23, 2025Large Language Models (LLMs) show promise as data analysis agents, but existing benchmarks overlook the iterative nature of the field, where experts' decisions evolve with deeper insights of the dataset. To address this, we introduce IDA-Bench, a novel benchmark evaluating LLM agents in multi-round interactive scenarios. Derived from complex Kaggle notebooks, tasks are presented as sequential natural language instructions by an LLM-simulated user. Agent performance is judged by comparing its final numerical output to the human-derived baseline. Initial results show that even state-of-the-art coding agents (like Claude-3.7-thinking) succeed on < 50% of the tasks, highlighting limitations not evident in single-turn tests. This work underscores the need to improve LLMs' multi-round capabilities for building more reliable data analysis agents, highlighting the necessity of achieving a balance between instruction following and reasoning.
TinyAlign: Boosting Lightweight Vision-Language Models by Mitigating Modal Alignment Bottlenecks
May 19, 2025Lightweight Vision-Language Models (VLMs) are indispensable for resource-constrained applications. The prevailing approach to aligning vision and language models involves freezing both the vision encoder and the language model while training small connector modules. However, this strategy heavily depends on the intrinsic capabilities of the language model, which can be suboptimal for lightweight models with limited representational capacity. In this work, we investigate this alignment bottleneck through the lens of mutual information, demonstrating that the constrained capacity of the language model inherently limits the Effective Mutual Information (EMI) between multimodal inputs and outputs, thereby compromising alignment quality. To address this challenge, we propose TinyAlign, a novel framework inspired by Retrieval-Augmented Generation, which strategically retrieves relevant context from a memory bank to enrich multimodal inputs and enhance their alignment. Extensive empirical evaluations reveal that TinyAlign significantly reduces training loss, accelerates convergence, and enhances task performance. Remarkably, it allows models to achieve baseline-level performance with only 40\% of the fine-tuning data, highlighting exceptional data efficiency. Our work thus offers a practical pathway for developing more capable lightweight VLMs while introducing a fresh theoretical lens to better understand and address alignment bottlenecks in constrained multimodal systems.
Implementing Long Text Style Transfer with LLMs through Dual-Layered Sentence and Paragraph Structure Extraction and Mapping
May 11, 2025



This paper addresses the challenge in long-text style transfer using zero-shot learning of large language models (LLMs), proposing a hierarchical framework that combines sentence-level stylistic adaptation with paragraph-level structural coherence. We argue that in the process of effective paragraph-style transfer, to preserve the consistency of original syntactic and semantic information, it is essential to perform style transfer not only at the sentence level but also to incorporate paragraph-level semantic considerations, while ensuring structural coherence across inter-sentential relationships. Our proposed framework, ZeroStylus, operates through two systematic phases: hierarchical template acquisition from reference texts and template-guided generation with multi-granular matching. The framework dynamically constructs sentence and paragraph template repositories, enabling context-aware transformations while preserving inter-sentence logical relationships. Experimental evaluations demonstrate significant improvements over baseline methods, with structured rewriting achieving 6.90 average score compared to 6.70 for direct prompting approaches in tri-axial metrics assessing style consistency, content preservation, and expression quality. Ablation studies validate the necessity of both template hierarchies during style transfer, showing higher content preservation win rate against sentence-only approaches through paragraph-level structural encoding, as well as direct prompting method through sentence-level pattern extraction and matching. The results establish new capabilities for coherent long-text style transfer without requiring parallel corpora or LLM fine-tuning.
Survey on Strategic Mining in Blockchain: A Reinforcement Learning Approach
Feb 25, 2025Strategic mining attacks, such as selfish mining, exploit blockchain consensus protocols by deviating from honest behavior to maximize rewards. Markov Decision Process (MDP) analysis faces scalability challenges in modern digital economics, including blockchain. To address these limitations, reinforcement learning (RL) provides a scalable alternative, enabling adaptive strategy optimization in complex dynamic environments. In this survey, we examine RL's role in strategic mining analysis, comparing it to MDP-based approaches. We begin by reviewing foundational MDP models and their limitations, before exploring RL frameworks that can learn near-optimal strategies across various protocols. Building on this analysis, we compare RL techniques and their effectiveness in deriving security thresholds, such as the minimum attacker power required for profitable attacks. Expanding the discussion further, we classify consensus protocols and propose open challenges, such as multi-agent dynamics and real-world validation. This survey highlights the potential of reinforcement learning (RL) to address the challenges of selfish mining, including protocol design, threat detection, and security analysis, while offering a strategic roadmap for researchers in decentralized systems and AI-driven analytics.
Large-Scale Contextual Market Equilibrium Computation through Deep Learning
Jun 11, 2024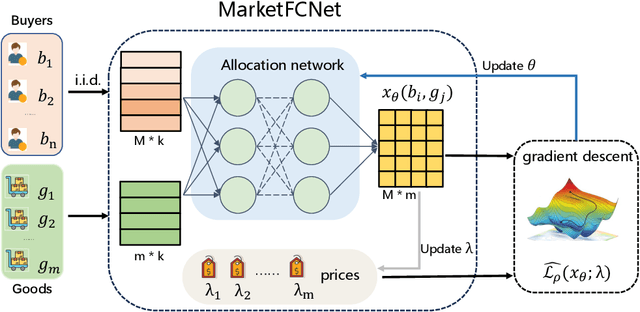
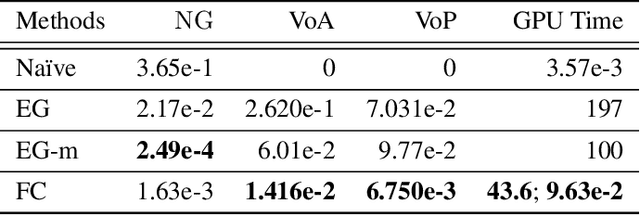
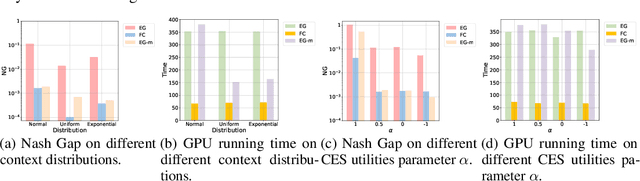
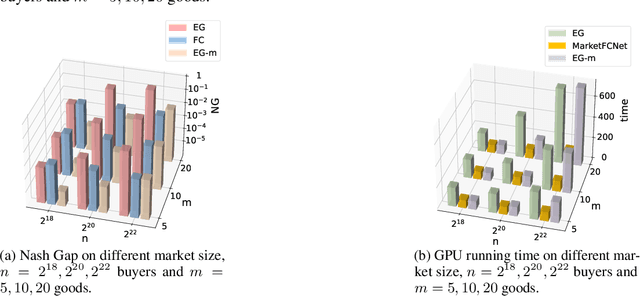
Market equilibrium is one of the most fundamental solution concepts in economics and social optimization analysis. Existing works on market equilibrium computation primarily focus on settings with a relatively small number of buyers. Motivated by this, our paper investigates the computation of market equilibrium in scenarios with a large-scale buyer population, where buyers and goods are represented by their contexts. Building on this realistic and generalized contextual market model, we introduce MarketFCNet, a deep learning-based method for approximating market equilibrium. We start by parameterizing the allocation of each good to each buyer using a neural network, which depends solely on the context of the buyer and the good. Next, we propose an efficient method to estimate the loss function of the training algorithm unbiasedly, enabling us to optimize the network parameters through gradient descent. To evaluate the approximated solution, we introduce a metric called Nash Gap, which quantifies the deviation of the given allocation and price pair from the market equilibrium. Experimental results indicate that MarketFCNet delivers competitive performance and significantly lower running times compared to existing methods as the market scale expands, demonstrating the potential of deep learning-based methods to accelerate the approximation of large-scale contextual market equilibrium.