 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Contextual Market Equilibrium Computation through Deep Learning
Jun 11, 2024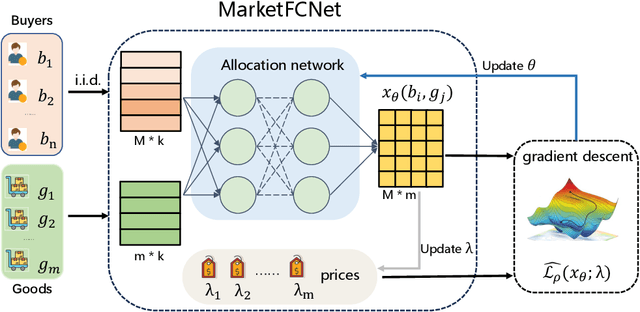
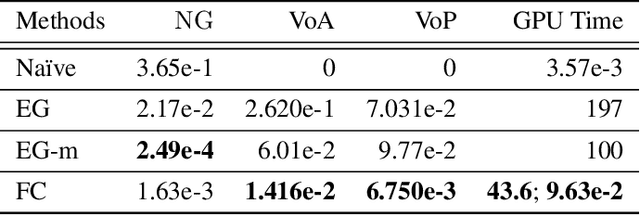
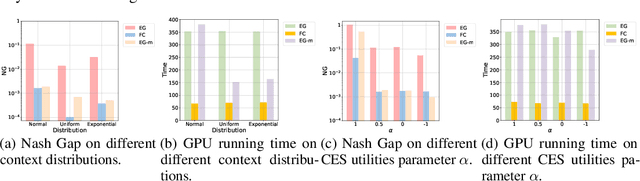
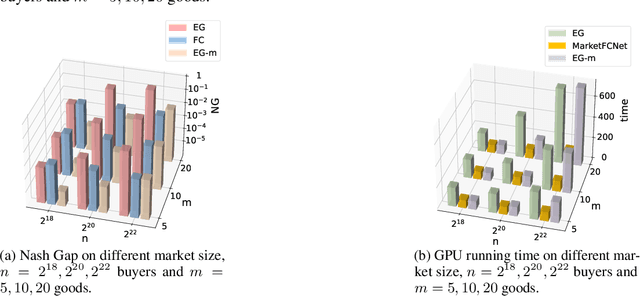
Market equilibrium is one of the most fundamental solution concepts in economics and social optimization analysis. Existing works on market equilibrium computation primarily focus on settings with a relatively small number of buyers. Motivated by this, our paper investigates the computation of market equilibrium in scenarios with a large-scale buyer population, where buyers and goods are represented by their contexts. Building on this realistic and generalized contextual market model, we introduce MarketFCNet, a deep learning-based method for approximating market equilibrium. We start by parameterizing the allocation of each good to each buyer using a neural network, which depends solely on the context of the buyer and the good. Next, we propose an efficient method to estimate the loss function of the training algorithm unbiasedly, enabling us to optimize the network parameters through gradient descent. To evaluate the approximated solution, we introduce a metric called Nash Gap, which quantifies the deviation of the given allocation and price pair from the market equilibrium. Experimental results indicate that MarketFCNet delivers competitive performance and significantly lower running times compared to existing methods as the market scale expands, demonstrating the potential of deep learning-based methods to accelerate the approximation of large-scale contextual market equilibrium.
Scalable Virtual Valuations Combinatorial Auction Design by Combining Zeroth-Order and First-Order Optimization Method
Feb 19, 2024Automated auction design seeks to discover empirically high-revenue and incentive-compatible mechanisms using machine learning. Ensuring dominant strategy incentive compatibility (DSIC) is crucial, and the most effective approach is to confine the mechanism to Affine Maximizer Auctions (AMAs). Nevertheless, existing AMA-based approaches encounter challenges such as scalability issues (arising from combinatorial candidate allocations) and the non-differentiability of revenue. In this paper, to achieve a scalable AMA-based method, we further restrict the auction mechanism to Virtual Valuations Combinatorial Auctions (VVCAs), a subset of AMAs with significantly fewer parameters. Initially, we employ a parallelizable dynamic programming algorithm to compute the winning allocation of a VVCA. Subsequently, we propose a novel optimization method that combines both zeroth-order and first-order techniques to optimize the VVCA parameters. Extensive experiments demonstrate the efficacy and scalability of our proposed approach, termed Zeroth-order and First-order Optimization of VVCAs (ZFO-VVCA), particularly when applied to large-scale auctions.
A survey on algorithms for Nash equilibria in finite normal-form games
Dec 18, 2023Nash equilibrium is one of the most influential solution concepts in game theory. With the development of computer science and artificial intelligence, there is an increasing demand on Nash equilibrium computation, especially for Internet economics and multi-agent learning. This paper reviews various algorithms computing the Nash equilibrium and its approximation solutions in finite normal-form games from both theoretical and empirical perspectives. For the theoretical part, we classify algorithms in the literature and present basic ideas on algorithm design and analysis. For the empirical part, we present a comprehensive comparison on the algorithms in the literature over different kinds of games. Based on these results, we provide practical suggestions on implementations and uses of these algorithms. Finally, we present a series of open problems from both theoretical and practical considerations.
Coordinated Dynamic Bidding in Repeated Second-Price Auctions with Budgets
Jun 13, 2023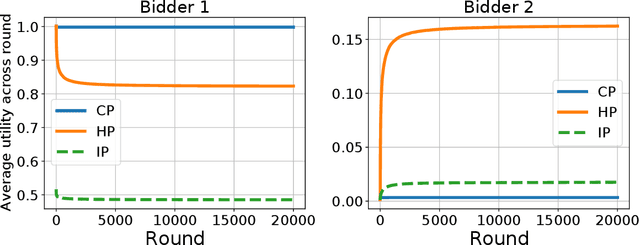
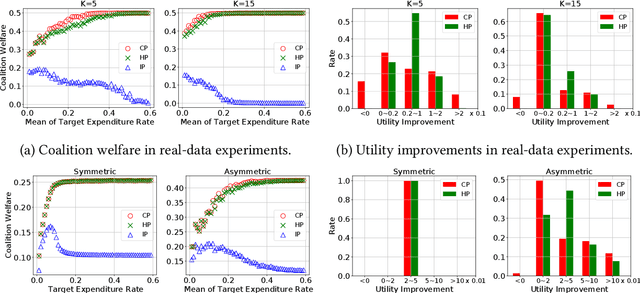
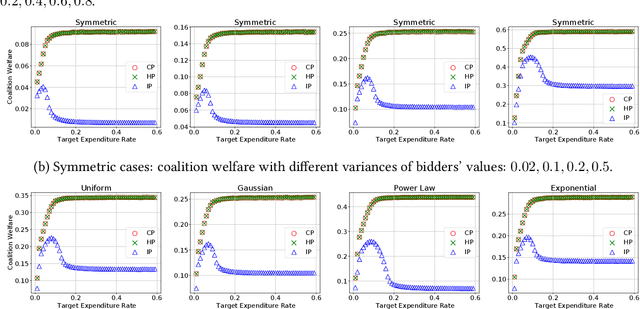
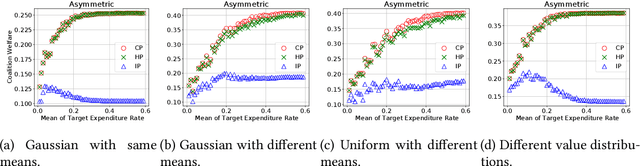
In online ad markets, a rising number of advertisers are employing bidding agencies to participate in ad auctions. These agencies are specialized in designing online algorithms and bidding on behalf of their clients. Typically, an agency usually has information on multiple advertisers, so she can potentially coordinate bids to help her clients achieve higher utilities than those under independent bidding. In this paper, we study coordinated online bidding algorithms in repeated second-price auctions with budgets. We propose algorithms that guarantee every client a higher utility than the best she can get under independent bidding. We show that these algorithms achieve maximal coalition welfare and discuss bidders' incentives to misreport their budgets, in symmetric cases. Our proofs combine the techniques of online learning and equilibrium analysis, overcoming the difficulty of competing with a multi-dimensional benchmark. The performance of our algorithms is further evaluated by experiments on both synthetic and real data. To the best of our knowledge, we are the first to consider bidder coordination in online repeated auctions with constraints.
A Scalable Neural Network for DSIC Affine Maximizer Auction Design
May 20, 2023Automated auction design aims to find empirically high-revenue mechanisms through machine learning. Existing works on multi item auction scenarios can be roughly divided into RegretNet-like and affine maximizer auctions (AMAs) approaches. However, the former cannot strictly ensure dominant strategy incentive compatibility (DSIC), while the latter faces scalability issue due to the large number of allocation candidates. To address these limitations, we propose AMenuNet, a scalable neural network that constructs the AMA parameters (even including the allocation menu) from bidder and item representations. AMenuNet is always DSIC and individually rational (IR) due to the properties of AMAs, and it enhances scalability by generating candidate allocations through a neural network. Additionally, AMenuNet is permutation equivariant, and its number of parameters is independent of auction scale. We conduct extensive experiments to demonstrate that AMenuNet outperforms strong baselines in both contextual and non-contextual multi-item auctions, scales well to larger auctions, generalizes well to different settings, and identifies useful deterministic allocations. Overall, our proposed approach offers an effective solution to automated DSIC auction design, with improved scalability and strong revenue performance in various settings.
Are Equivariant Equilibrium Approximators Beneficial?
Jan 27, 2023Recently, remarkable progress has been made by approximating Nash equilibrium (NE), correlated equilibrium (CE), and coarse correlated equilibrium (CCE) through function approximation that trains a neural network to predict equilibria from game representations. Furthermore, equivariant architectures are widely adopted in designing such equilibrium approximators in normal-form games. In this paper, we theoretically characterize benefits and limitations of equivariant equilibrium approximators. For the benefits, we show that they enjoy better generalizability than general ones and can achieve better approximations when the payoff distribution is permutation-invariant. For the limitations, we discuss their drawbacks in terms of equilibrium selection and social welfare. Together, our results help to understand the role of equivariance in equilibrium approximators.
A Context-Integrated Transformer-Based Neural Network for Auction Design
Jan 29, 2022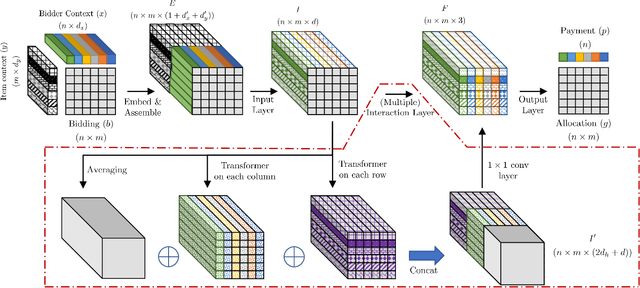
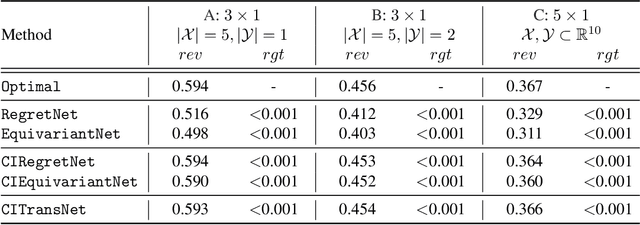

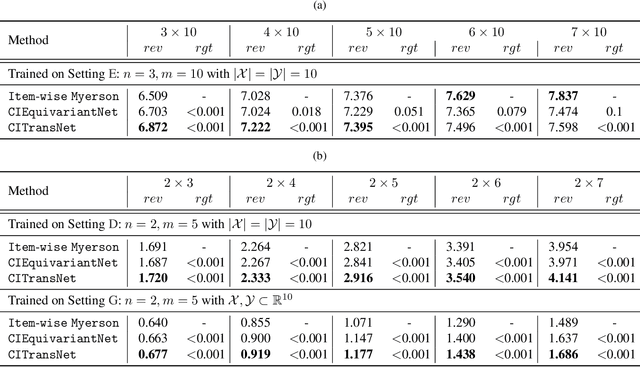
One of the central problems in auction design is developing an incentive-compatible mechanism that maximizes the auctioneer's expected revenue. While theoretical approaches have encountered bottlenecks in multi-item auctions, recently, there has been much progress on finding the optimal mechanism through deep learning. However, these works either focus on a fixed set of bidders and items, or restrict the auction to be symmetric. In this work, we overcome such limitations by factoring \emph{public} contextual information of bidders and items into the auction learning framework. We propose $\mathtt{CITransNet}$, a context-integrated transformer-based neural network for optimal auction design, which maintains permutation-equivariance over bids and contexts while being able to find asymmetric solutions. We show by extensive experiments that $\mathtt{CITransNet}$ can recover the known optimal solutions in single-item settings, outperform strong baselines in multi-item auctions, and generalize well to cases other than those in training.
Learning to Compute Approximate Nash Equilibrium for Normal-form Games
Aug 17, 2021
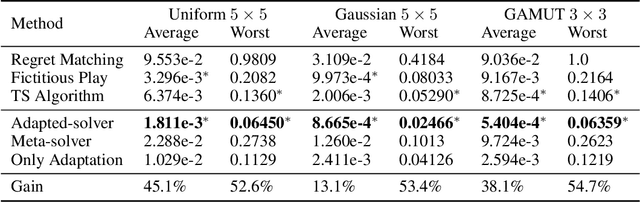


In this paper, we propose a general meta learning approach to computing approximate Nash equilibrium for finite $n$-player normal-form games. Unlike existing solutions that approximate or learn a Nash equilibrium from scratch for each of the games, our meta solver directly constructs a mapping from a game utility matrix to a joint strategy profile. The mapping is parameterized and learned in a self-supervised fashion by a proposed Nash equilibrium approximation metric without ground truth data informing any Nash equilibrium. As such, it can immediately predict the joint strategy profile that approximates a Nash equilibrium for any unseen new game under the same game distribution. Moreover, the meta-solver can be further fine-tuned and adaptive to a new game if iteration updates are allowed. We theoretically prove that our meta-solver is not affected by the non-smoothness of exact Nash equilibrium solutions, and derive a sample complexity bound to demonstrate its generalization ability across normal-form games. Experimental results demonstrate its substantial approximation power against other strong baselines in both adaptive and non-adaptive cases.
Role-Wise Data Augmentation for Knowledge Distillation
Apr 19, 2020
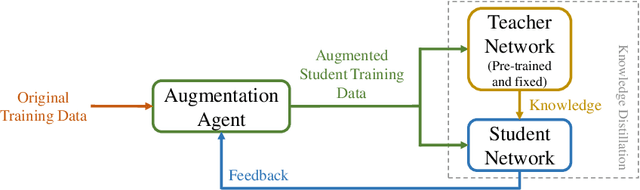
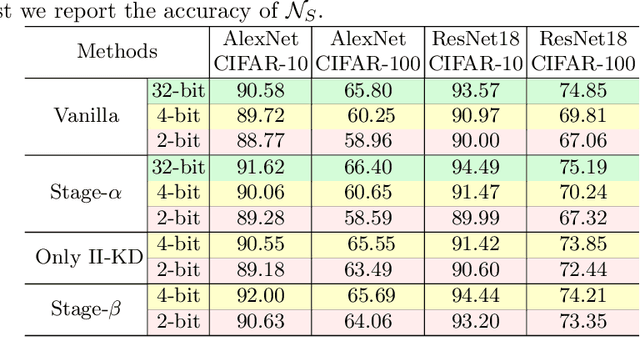

Knowledge Distillation (KD) is a common method for transferring the ``knowledge'' learned by one machine learning model (the \textit{teacher}) into another model (the \textit{student}), where typically, the teacher has a greater capacity (e.g., more parameters or higher bit-widths). To our knowledge, existing methods overlook the fact that although the student absorbs extra knowledge from the teacher, both models share the same input data -- and this data is the only medium by which the teacher's knowledge can be demonstrated. Due to the difference in model capacities, the student may not benefit fully from the same data points on which the teacher is trained. On the other hand, a human teacher may demonstrate a piece of knowledge with individualized examples adapted to a particular student, for instance, in terms of her cultural background and interests. Inspired by this behavior, we design data augmentation agents with distinct roles to facilitate knowledge distillation. Our data augmentation agents generate distinct training data for the teacher and student, respectively. We find empirically that specially tailored data points enable the teacher's knowledge to be demonstrated more effectively to the student. We compare our approach with existing KD methods on training popular neural architectures and demonstrate that role-wise data augmentation improves the effectiveness of KD over strong prior approaches. The code for reproducing our results can be found at https://github.com/bigaidream-projects/role-kd
Explainable Knowledge Graph-based Recommendation via Deep Reinforcement Learning
Jun 22, 2019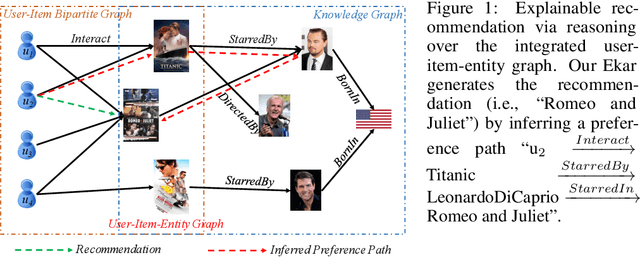

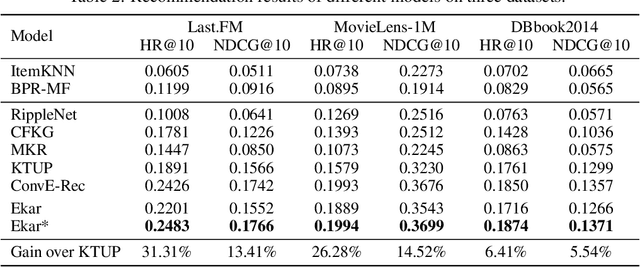
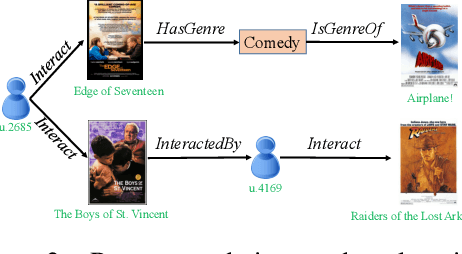
This paper studies recommender systems with knowledge graphs, which can effectively address the problems of data sparsity and cold start. Recently, a variety of methods have been developed for this problem, which generally try to learn effective representations of users and items and then match items to users according to their representations. Though these methods have been shown quite effective, they lack good explanations, which are critical to recommender systems. In this paper, we take a different path and propose generating recommendations by finding meaningful paths from users to items. Specifically, we formulate the problem as a sequential decision process, where the target user is defined as the initial state, and the walks on the graphs are defined as actions. We shape the rewards according to existing state-of-the-art methods and then train a policy function with policy gradient methods. Experimental results on three real-world datasets show that our proposed method not only provides effective recommendations but also offers good explanations.