 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreetDesignAI: A Multi-Persona Evaluation System for Inclusive Infrastructure Design
Jan 22, 2026Designing inclusive cycling infrastructure requires balancing competing needs of diverse user groups, yet designers often struggle to anticipate how different cyclists experience the same street. We investigate how persona-based multi-agent evaluation can support inclusive design by making experiential conflicts explicit. We present StreetDesignAI, an interactive system that enables designers to (1) ground evaluation in street context through imagery and map data, (2) receive parallel feedback from cyclist personas spanning confident to cautious users, and (3) iteratively modify designs while surfacing conflicts across perspectives. A within-subjects study with 26 transportation professionals demonstrates that structured multi-perspective feedback significantly improves designers' understanding of diverse user perspectives, ability to identify persona needs, and confidence in translating them into design decisions, with higher satisfaction and stronger intention for professional adoption. Qualitative findings reveal how conflict surfacing transforms design exploration from single-perspective optimization toward deliberate trade-off reasoning. We discuss implications for AI tools that scaffold inclusive design through disagreement as an interaction primitive.
Persona-aware and Explainable Bikeability Assessment: A Vision-Language Model Approach
Jan 07, 2026Bikeability assessment is essential for advancing sustainable urban transportation and creating cyclist-friendly cities, and it requires incorporating users' perceptions of safety and comfort. Yet existing perception-based bikeability assessment approaches face key limitations in capturing the complexity of road environments and adequately accounting for heterogeneity in subjective user perceptions. This paper proposes a persona-aware Vision-Language Model framework for bikeability assessment with three novel contributions: (i) theory-grounded persona conditioning based on established cyclist typology that generates persona-specific explanations via chain-of-thought reasoning; (ii) multi-granularity supervised fine-tuning that combines scarce expert-annotated reasoning with abundant user ratings for joint prediction and explainable assessment; and (iii) AI-enabled data augmentation that creates controlled paired data to isolate infrastructure variable impacts. To test and validate this framework, we developed a panoramic image-based crowdsourcing system and collected 12,400 persona-conditioned assessments from 427 cyclists. Experiment results show that the proposed framework offers competitive bikeability rating prediction while uniquely enabling explainable factor attribution.
Beyond Full Label: Single-Point Prompt for Infrared Small Target Label Generation
Aug 15, 2024



In this work, we make the first attempt to construct a learning-based single-point annotation paradigm for infrared small target label generation (IRSTLG). Our intuition is that label generation requires just one more point prompt than target detection: IRSTLG can be regarded as an infrared small target detection (IRSTD) task with the target location hint. Based on this insight, we introduce an energy double guided single-point prompt (EDGSP) framework, which adeptly transforms the target detection network into a refined label generation method. Specifically, the proposed EDGSP includes: 1) target energy initialization (TEI) to create a foundational outline for sufficient shape evolution of pseudo label, 2) double prompt embedding (DPE) for rapid localization of interested regions and reinforcement of individual differences to avoid label adhesion, and 3) bounding box-based matching (BBM) to eliminate false alarms. Experimental results show that pseudo labels generated by three baselines equipped with EDGSP achieve 100% object-level probability of detection (Pd) and 0% false-alarm rate (Fa) on SIRST, NUDT-SIRST, and IRSTD-1k datasets, with a pixel-level intersection over union (IoU) improvement of 13.28% over state-of-the-art label generation methods. Additionally, the downstream detection task reveals that our centroid-annotated pseudo labels surpass full labels, even with coarse single-point annotations, it still achieves 99.5% performance of full labeling.
DestripeCycleGAN: Stripe Simulation CycleGAN for Unsupervised Infrared Image Destriping
Feb 14, 2024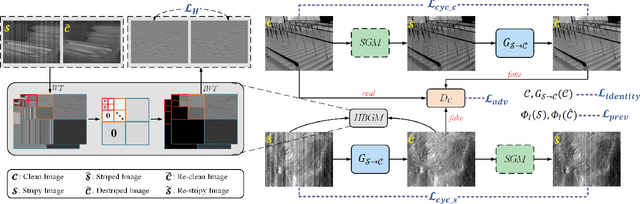
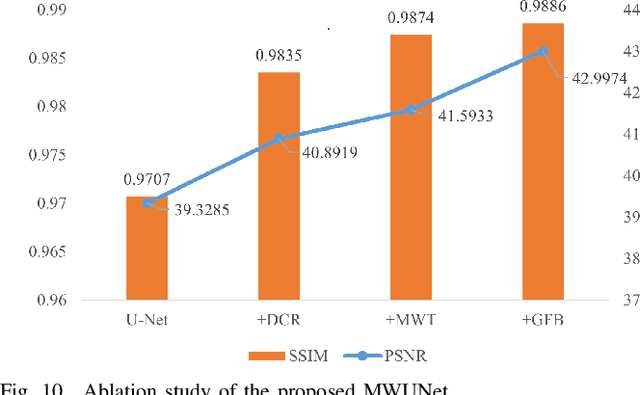

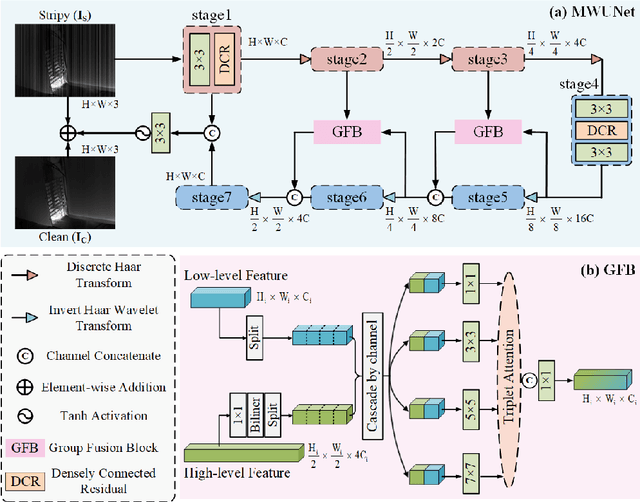
CycleGAN has been proven to be an advanced approach for unsupervised image restoration. This framework consists of two generators: a denoising one for inference and an auxiliary one for modeling noise to fulfill cycle-consistency constraints. However, when applied to the infrared destriping task, it becomes challenging for the vanilla auxiliary generator to consistently produce vertical noise under unsupervised constraints. This poses a threat to the effectiveness of the cycle-consistency loss, leading to stripe noise residual in the denoised image. To address the above issue, we present a novel framework for single-frame infrared image destriping, named DestripeCycleGAN. In this model, the conventional auxiliary generator is replaced with a priori stripe generation model (SGM) to introduce vertical stripe noise in the clean data, and the gradient map is employed to re-establish cycle-consistency. Meanwhile, a Haar wavelet background guidance module (HBGM) has been designed to minimize the divergence of background details between the different domains. To preserve vertical edges, a multi-level wavelet U-Net (MWUNet) is proposed as the denoising generator, which utilizes the Haar wavelet transform as the sampler to decline directional information loss. Moreover, it incorporates the group fusion block (GFB) into skip connections to fuse the multi-scale features and build the context of long-distance dependencies. Extensive experiments on real and synthetic data demonstrate that our DestripeCycleGAN surpasses the state-of-the-art methods in terms of visual quality and quantitative evaluation. Our code will be made public at https://github.com/0wuji/DestripeCycleGAN.
SCTransNet: Spatial-channel Cross Transformer Network for Infrared Small Target Detection
Feb 01, 2024



Infrared small target detection (IRSTD) has recently benefitted greatly from U-shaped neural models. However, largely overlooking effective global information modeling, existing techniques struggle when the target has high similarities with the background. We present a Spatial-channel Cross Transformer Network (SCTransNet) that leverages spatial-channel cross transformer blocks (SCTBs) on top of long-range skip connections to address the aforementioned challenge. In the proposed SCTBs, the outputs of all encoders are interacted with cross transformer to generate mixed features, which are redistributed to all decoders to effectively reinforce semantic differences between the target and clutter at full scales. Specifically, SCTB contains the following two key elements: (a) spatial-embedded single-head channel-cross attention (SSCA) for exchanging local spatial features and full-level global channel information to eliminate ambiguity among the encoders and facilitate high-level semantic associations of the images, and (b) a complementary feed-forward network (CFN) for enhancing the feature discriminability via a multi-scale strategy and cross-spatial-channel information interaction to promote beneficial information transfer. Our SCTransNet effectively encodes the semantic differences between targets and backgrounds to boost its internal representation for detecting small infrared targets accurately. Extensive experiments on three public datasets, NUDT-SIRST, NUAA-SIRST, and IRSTD-1k, demonstrate that the proposed SCTransNet outperforms existing IRSTD methods. Our code will be made public at https://github.com/xdFai.
ARCNet: An Asymmetric Residual Wavelet Column Correction Network for Infrared Image Destriping
Jan 28, 2024



Infrared image destriping seeks to restore high-quality content from degraded images. Recent works mainly address this task by leveraging prior knowledge to separate stripe noise from the degraded image. However, constructing a robust decoupling model for that purpose remains challenging, especially when significant similarities exist between the stripe noise and vertical background structure. Addressing that, we introduce Asymmetric Residual wavelet Column correction Network (ARCNet) for image destriping, aiming to consistently preserve spatially precise high-resolution representations. Our neural model leverages a novel downsampler, residual haar discrete wavelet transform (RHDWT), stripe directional prior knowledge and data-driven learning to induce a model with enriched feature representation of stripe noise and background. In our technique, the inverse wavelet transform is replaced by transposed convolution for feature upsampling, which can suppress noise crosstalk and encourage the network to focus on robust image reconstruction. After each sampling, a proposed column non-uniformity correction module (CNCM) is leveraged by our method to enhance column uniformity, spatial correlation, and global self-dependence between each layer component. CNCM can establish structural characteristics of stripe noise and utilize contextual information at long-range dependencies to distinguish stripes with varying intensities and distributions. Extensive experiments on synthetic data, real data, and infrared small target detection tasks show that the proposed method outperforms state-of-the-art single-image destriping methods both visually and quantitatively by a considerable margin. Our code will be made publicly available at \url{https://github.com/xdFai}.
A Hierarchical Destroy and Repair Approach for Solving Very Large-Scale Travelling Salesman Problem
Aug 09, 2023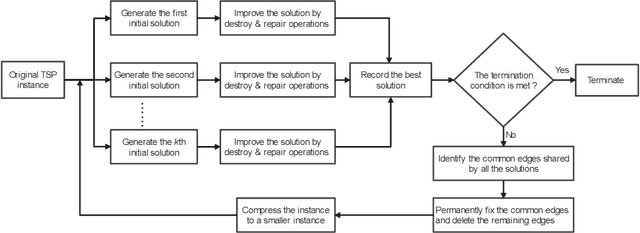
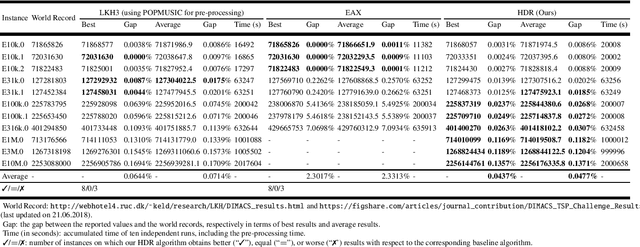
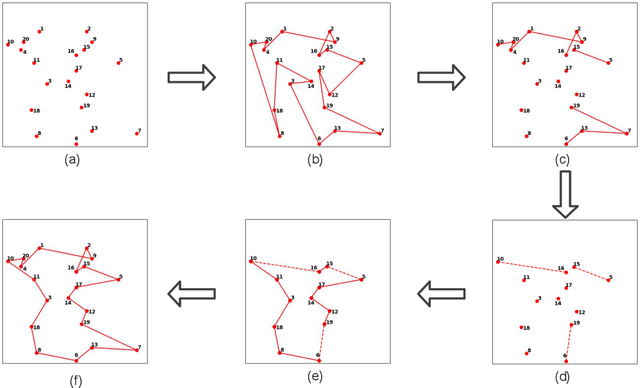
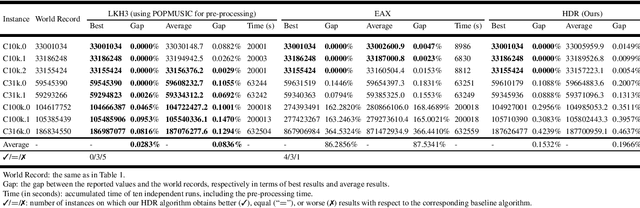
For prohibitively large-scale Travelling Salesman Problems (TSPs), existing algorithms face big challenges in terms of both computational efficiency and solution quality. To address this issue, we propose a hierarchical destroy-and-repair (HDR) approach, which attempts to improve an initial solution by applying a series of carefully designed destroy-and-repair operations. A key innovative concept is the hierarchical search framework, which recursively fixes partial edges and compresses the input instance into a small-scale TSP under some equivalence guarantee. This neat search framework is able to deliver highly competitive solutions within a reasonable time. Fair comparisons based on nineteen famous large-scale instances (with 10,000 to 10,000,000 cities) show that HDR is highly competitive against existing state-of-the-art TSP algorithms, in terms of both efficiency and solution quality. Notably, on two large instances with 3,162,278 and 10,000,000 cities, HDR breaks the world records (i.e., best-known results regardless of computation time), which were previously achieved by LKH and its variants, while HDR is completely independent of LKH. Finally, ablation studies are performed to certify the importance and validity of the hierarchical search framework.
Coordinated Dynamic Bidding in Repeated Second-Price Auctions with Budgets
Jun 13, 2023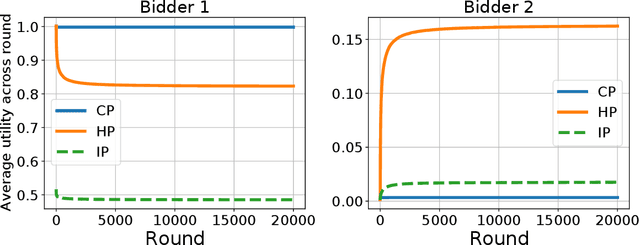
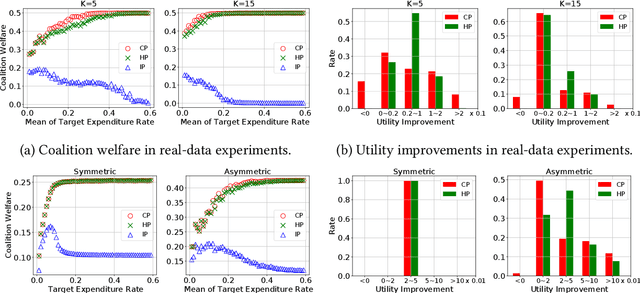
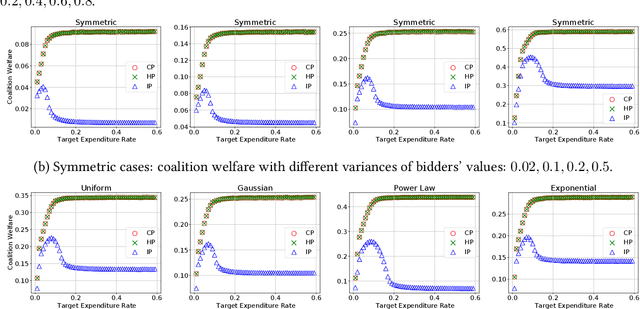
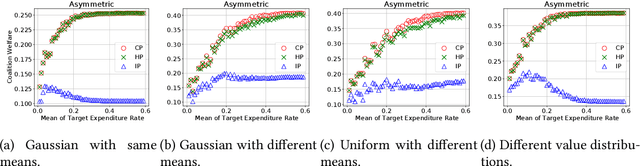
In online ad markets, a rising number of advertisers are employing bidding agencies to participate in ad auctions. These agencies are specialized in designing online algorithms and bidding on behalf of their clients. Typically, an agency usually has information on multiple advertisers, so she can potentially coordinate bids to help her clients achieve higher utilities than those under independent bidding. In this paper, we study coordinated online bidding algorithms in repeated second-price auctions with budgets. We propose algorithms that guarantee every client a higher utility than the best she can get under independent bidding. We show that these algorithms achieve maximal coalition welfare and discuss bidders' incentives to misreport their budgets, in symmetric cases. Our proofs combine the techniques of online learning and equilibrium analysis, overcoming the difficulty of competing with a multi-dimensional benchmark. The performance of our algorithms is further evaluated by experiments on both synthetic and real data. To the best of our knowledge, we are the first to consider bidder coordination in online repeated auctions with constraints.
Examining spatial heterogeneity of ridesourcing demand determinants with explainable machine learning
Sep 16, 2022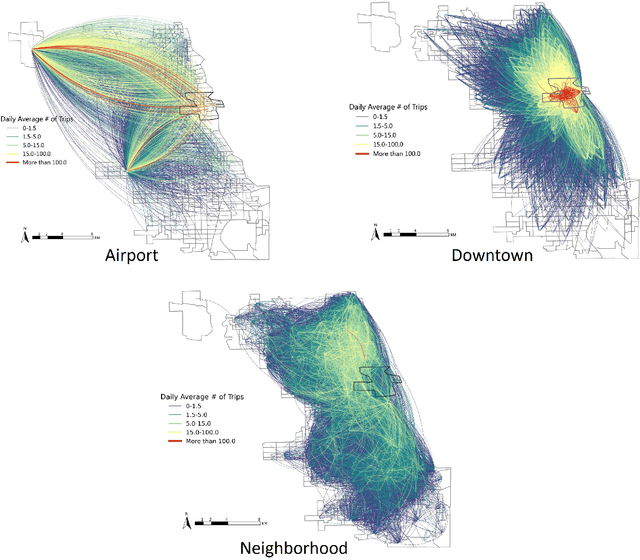

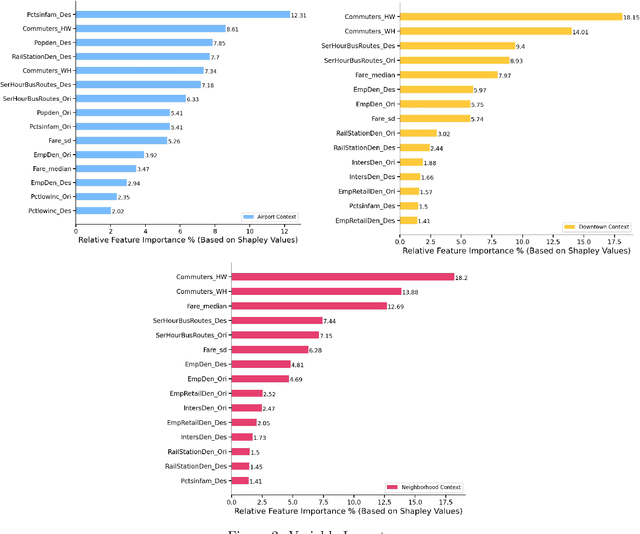

The growing significance of ridesourcing services in recent years suggests a need to examine the key determinants of ridesourcing demand. However, little is known regarding the nonlinear effects and spatial heterogeneity of ridesourcing demand determinants. This study applies an explainable-machine-learning-based analytical framework to identify the key factors that shape ridesourcing demand and to explore their nonlinear associations across various spatial contexts (airport, downtown, and neighborhood). We use the ridesourcing-trip data in Chicago for empirical analysis. The results reveal that the importance of built environment varies across spatial contexts, and it collectively contributes the largest importance in predicting ridesourcing demand for airport trips. Additionally, the nonlinear effects of built environment on ridesourcing demand show strong spatial variations. Ridesourcing demand is usually most responsive to the built environment changes for downtown trips, followed by neighborhood trips and airport trips. These findings offer transportation professionals nuanced insights for managing ridesourcing services.
On the Convergence of Fictitious Play: A Decomposition Approach
May 03, 2022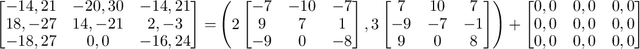
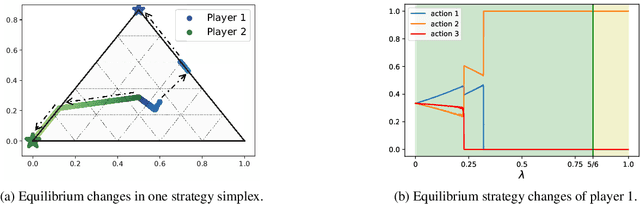
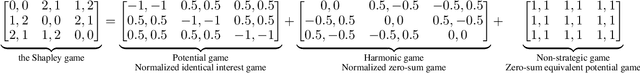

Fictitious play (FP) is one of the most fundamental game-theoretical learning frameworks for computing Nash equilibrium in $n$-player games, which builds the foundation for modern multi-agent learning algorithms. Although FP has provable convergence guarantees on zero-sum games and potential games, many real-world problems are often a mixture of both and the convergence property of FP has not been fully studied yet. In this paper, we extend the convergence results of FP to the combinations of such games and beyond. Specifically, we derive new conditions for FP to converge by leveraging game decomposition techniques. We further develop a linear relationship unifying cooperation and competition in the sense that these two classes of games are mutually transferable. Finally, we analyze a non-convergent example of FP, the Shapley game, and develop sufficient conditions for FP to converge.