 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIAFormer: Voxel-Image Alignment Transformer for High-Fidelity Voxel Refinement
Jan 21, 2026We propose VIAFormer, a Voxel-Image Alignment Transformer model designed for Multi-view Conditioned Voxel Refinement--the task of repairing incomplete noisy voxels using calibrated multi-view images as guidance. Its effectiveness stems from a synergistic design: an Image Index that provides explicit 3D spatial grounding for 2D image tokens, a Correctional Flow objective that learns a direct voxel-refinement trajectory, and a Hybrid Stream Transformer that enables robust cross-modal fusion. Experiments show that VIAFormer establishes a new state of the art in correcting both severe synthetic corruptions and realistic artifacts on the voxel shape obtained from powerful Vision Foundation Models. Beyond benchmarking, we demonstrate VIAFormer as a practical and reliable bridge in real-world 3D creation pipelines, paving the way for voxel-based methods to thrive in large-model, big-data wave.
LoG3D: Ultra-High-Resolution 3D Shape Modeling via Local-to-Global Partitioning
Nov 18, 2025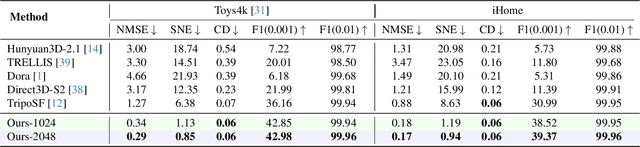
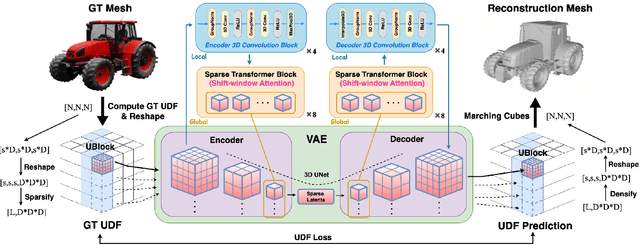
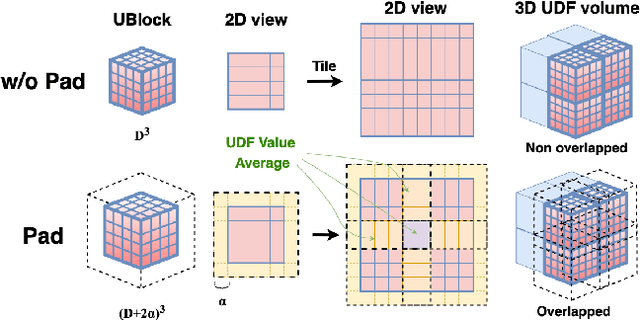
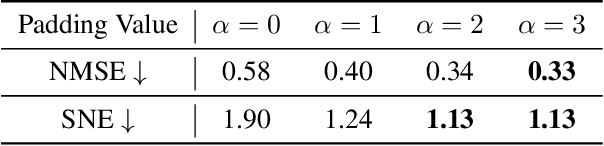
Generating high-fidelity 3D contents remains a fundamental challenge due to the complexity of representing arbitrary topologies-such as open surfaces and intricate internal structures-while preserving geometric details. Prevailing methods based on signed distance fields (SDFs) are hampered by costly watertight preprocessing and struggle with non-manifold geometries, while point-cloud representations often suffer from sampling artifacts and surface discontinuities. To overcome these limitations, we propose a novel 3D variational autoencoder (VAE) framework built upon unsigned distance fields (UDFs)-a more robust and computationally efficient representation that naturally handles complex and incomplete shapes. Our core innovation is a local-to-global (LoG) architecture that processes the UDF by partitioning it into uniform subvolumes, termed UBlocks. This architecture couples 3D convolutions for capturing local detail with sparse transformers for enforcing global coherence. A Pad-Average strategy further ensures smooth transitions at subvolume boundaries during reconstruction. This modular design enables seamless scaling to ultra-high resolutions up to $2048^3$-a regime previously unattainable for 3D VAEs. Experiments demonstrate state-of-the-art performance in both reconstruction accuracy and generative quality, yielding superior surface smoothness and geometric flexibility.
MoRE: 3D Visual Geometry Reconstruction Meets Mixture-of-Experts
Oct 31, 2025Recent advances in language and vision have demonstrated that scaling up model capacity consistently improves performance across diverse tasks. In 3D visual geometry reconstruction, large-scale training has likewise proven effective for learning versatile representations. However, further scaling of 3D models is challenging due to the complexity of geometric supervision and the diversity of 3D data. To overcome these limitations, we propose MoRE, a dense 3D visual foundation model based on a Mixture-of-Experts (MoE) architecture that dynamically routes features to task-specific experts, allowing them to specialize in complementary data aspects and enhance both scalability and adaptability. Aiming to improve robustness under real-world conditions, MoRE incorporates a confidence-based depth refinement module that stabilizes and refines geometric estimation. In addition, it integrates dense semantic features with globally aligned 3D backbone representations for high-fidelity surface normal prediction. MoRE is further optimized with tailored loss functions to ensure robust learning across diverse inputs and multiple geometric tasks. Extensive experiments demonstrate that MoRE achieves state-of-the-art performance across multiple benchmarks and supports effective downstream applications without extra computation.
StableIntrinsic: Detail-preserving One-step Diffusion Model for Multi-view Material Estimation
Aug 27, 2025



Recovering material information from images has been extensively studied in computer graphics and vision. Recent works in material estimation leverage diffusion model showing promising results. However, these diffusion-based methods adopt a multi-step denoising strategy, which is time-consuming for each estimation. Such stochastic inference also conflicts with the deterministic material estimation task, leading to a high variance estimated results. In this paper, we introduce StableIntrinsic, a one-step diffusion model for multi-view material estimation that can produce high-quality material parameters with low variance. To address the overly-smoothing problem in one-step diffusion, StableIntrinsic applies losses in pixel space, with each loss designed based on the properties of the material. Additionally, StableIntrinsic introduces a Detail Injection Network (DIN) to eliminate the detail loss caused by VAE encoding, while further enhancing the sharpness of material prediction results. The experimental results indicate that our method surpasses the current state-of-the-art techniques by achieving a $9.9\%$ improvement in the Peak Signal-to-Noise Ratio (PSNR) of albedo, and by reducing the Mean Square Error (MSE) for metallic and roughness by $44.4\%$ and $60.0\%$, respectively.
GlossyGS: Inverse Rendering of Glossy Objects with 3D Gaussian Splatting
Oct 17, 2024

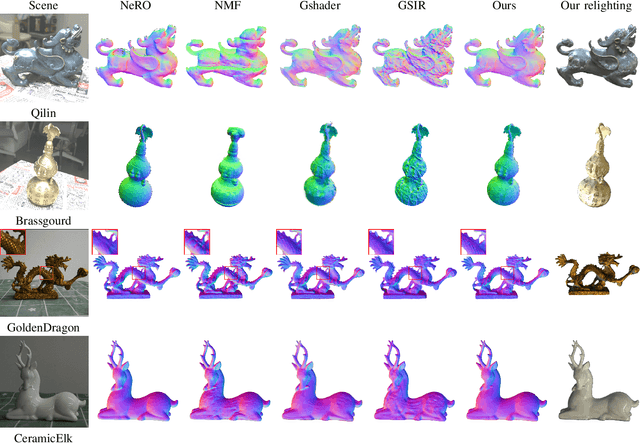
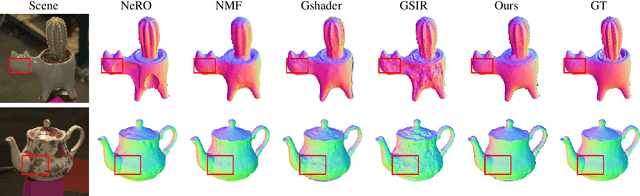
Reconstructing objects from posed images is a crucial and complex task in computer graphics and computer vision. While NeRF-based neural reconstruction methods have exhibited impressive reconstruction ability, they tend to be time-comsuming. Recent strategies have adopted 3D Gaussian Splatting (3D-GS) for inverse rendering, which have led to quick and effective outcomes. However, these techniques generally have difficulty in producing believable geometries and materials for glossy objects, a challenge that stems from the inherent ambiguities of inverse rendering. To address this, we introduce GlossyGS, an innovative 3D-GS-based inverse rendering framework that aims to precisely reconstruct the geometry and materials of glossy objects by integrating material priors. The key idea is the use of micro-facet geometry segmentation prior, which helps to reduce the intrinsic ambiguities and improve the decomposition of geometries and materials. Additionally, we introduce a normal map prefiltering strategy to more accurately simulate the normal distribution of reflective surfaces. These strategies are integrated into a hybrid geometry and material representation that employs both explicit and implicit methods to depict glossy objects. We demonstrate through quantitative analysis and qualitative visualization that the proposed method is effective to reconstruct high-fidelity geometries and materials of glossy objects, and performs favorably against state-of-the-arts.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023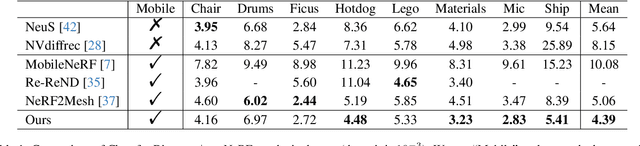
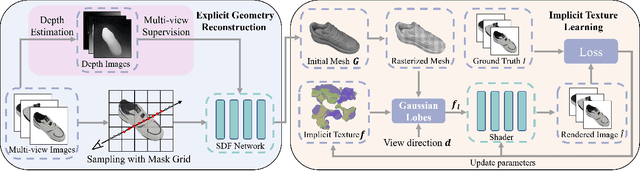
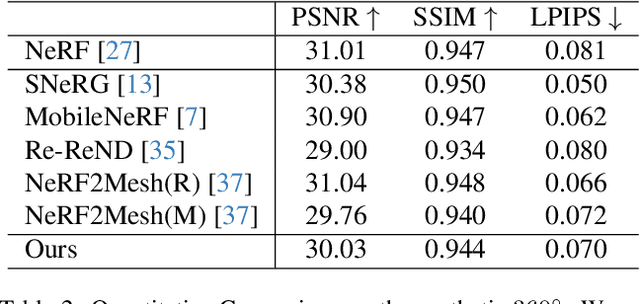
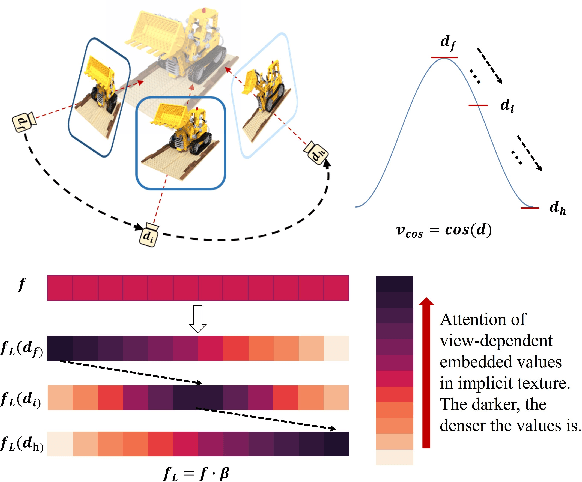
Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
ITEM3D: Illumination-Aware Directional Texture Editing for 3D Models
Sep 27, 2023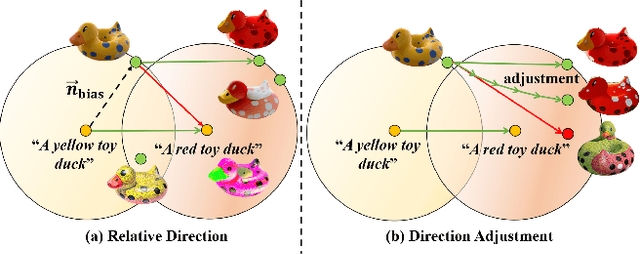

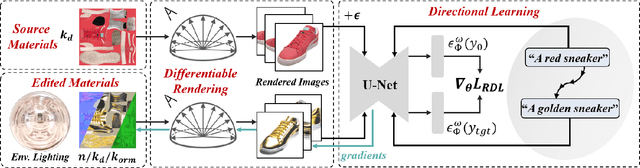

Texture editing is a crucial task in 3D modeling that allows users to automatically manipulate the surface materials of 3D models. However, the inherent complexity of 3D models and the ambiguous text description lead to the challenge in this task. To address this challenge, we propose ITEM3D, an illumination-aware model for automatic 3D object editing according to the text prompts. Leveraging the diffusion models and the differentiable rendering, ITEM3D takes the rendered images as the bridge of text and 3D representation, and further optimizes the disentangled texture and environment map. Previous methods adopt the absolute editing direction namely score distillation sampling (SDS) as the optimization objective, which unfortunately results in the noisy appearance and text inconsistency. To solve the problem caused by the ambiguous text, we introduce a relative editing direction, an optimization objective defined by the noise difference between the source and target texts, to release the semantic ambiguity between the texts and images. Additionally, we gradually adjust the direction during optimization to further address the unexpected deviation in the texture domain. Qualitative and quantitative experiments show that our ITEM3D outperforms the state-of-the-art methods on various 3D objects. We also perform text-guided relighting to show explicit control over lighting.
Single-Image 3D Face Reconstruction under Perspective Projection
May 09, 2022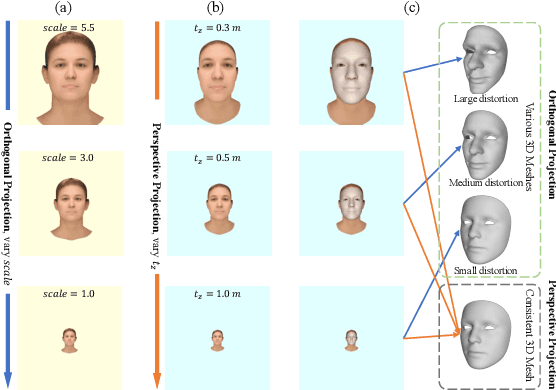
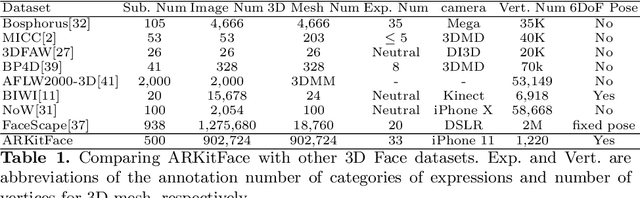
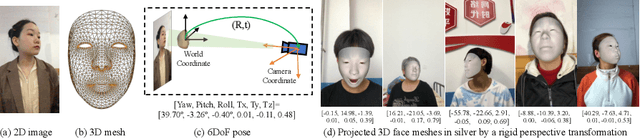

In 3D face reconstruction, orthogonal projection has been widely employed to substitute perspective projection to simplify the fitting process. This approximation performs well when the distance between camera and face is far enough. However, in some scenarios that the face is very close to camera or moving along the camera axis, the methods suffer from the inaccurate reconstruction and unstable temporal fitting due to the distortion under the perspective projection. In this paper, we aim to address the problem of single-image 3D face reconstruction under perspective projection. Specifically, a deep neural network, Perspective Network (PerspNet), is proposed to simultaneously reconstruct 3D face shape in canonical space and learn the correspondence between 2D pixels and 3D points, by which the 6DoF (6 Degrees of Freedom) face pose can be estimated to represent perspective projection. Besides, we contribute a large ARKitFace dataset to enable the training and evaluation of 3D face reconstruction solutions under the scenarios of perspective projection, which has 902,724 2D facial images with ground-truth 3D face mesh and annotated 6DoF pose parameters. Experimental results show that our approach outperforms current state-of-the-art methods by a significant margin.
MVP-Human Dataset for 3D Human Avatar Reconstruction from Unconstrained Frames
Apr 24, 2022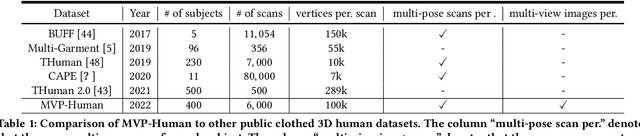
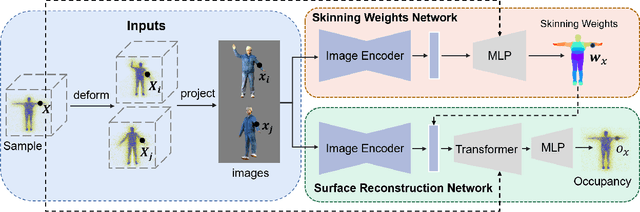
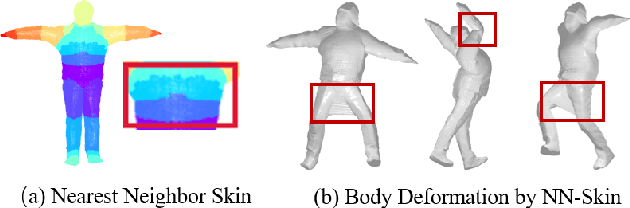
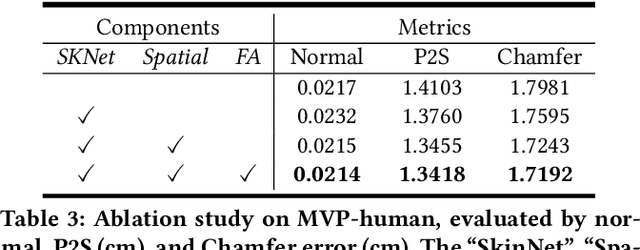
In this paper, we consider a novel problem of reconstructing a 3D human avatar from multiple unconstrained frames, independent of assumptions on camera calibration, capture space, and constrained actions. The problem should be addressed by a framework that takes multiple unconstrained images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass. To this end, we present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner, by which the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. To enable the training and testing of the new framework, we contribute a large-scale dataset, MVP-Human (Multi-View and multi-Pose 3D Human), which contains 400 subjects, each of which has 15 scans in different poses and 8-view images for each pose, providing 6,000 3D scans and 48,000 images in total. Overall, benefits from the specific network architecture and the diverse data, the trained model enables 3D avatar reconstruction from unconstrained frames and achieves state-of-the-art performance.
Pixel-Face: A Large-Scale, High-Resolution Benchmark for 3D Face Reconstruction
Sep 03, 2020
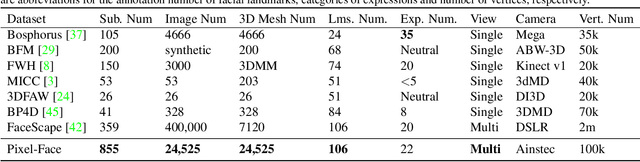
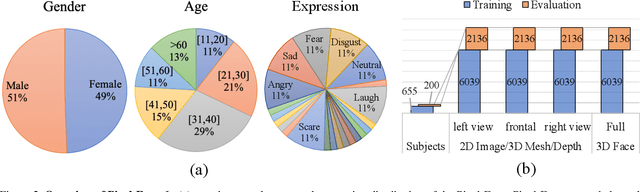

3D face reconstruction is a fundamental task that can facilitate numerous applications such as robust facial analysis and augmented reality. It is also a challenging task due to the lack of high-quality datasets that can fuel current deep learning-based methods. However, existing datasets are limited in quantity, realisticity and diversity. To circumvent these hurdles, we introduce Pixel-Face, a large-scale, high-resolution and diverse 3D face dataset with massive annotations. Specifically, Pixel-Face contains 855 subjects aging from 18 to 80. Each subject has more than 20 samples with various expressions. Each sample is composed of high-resolution multi-view RGB images and 3D meshes with various expressions. Moreover, we collect precise landmarks annotation and 3D registration result for each data. To demonstrate the advantages of Pixel-Face, we re-parameterize the 3D Morphable Model (3DMM) into Pixel-3DM using the collected data. We show that the obtained Pixel-3DM is better in modeling a wide range of face shapes and expressions. We also carefully benchmark existing 3D face reconstruction methods on our dataset. Moreover, Pixel-Face serves as an effective training source. We observe that the performance of current face reconstruction models significantly improves both on existing benchmarks and Pixel-Face after being fine-tuned using our newly collected data. Extensive experiments demonstrate the effectiveness of Pixel-3DM and the usefulness of Pixel-Face.