 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-LiveAct: Towards Hour-Scale Real-Time Human Animation with Neighbor Forcing and ConvKV Memory
Mar 12, 2026Autoregressive (AR) diffusion models offer a promising framework for sequential generation tasks such as video synthesis by combining diffusion modeling with causal inference. Although they support streaming generation, existing AR diffusion methods struggle to scale efficiently. In this paper, we identify two key challenges in hour-scale real-time human animation. First, most forcing strategies propagate sample-level representations with mismatched diffusion states, causing inconsistent learning signals and unstable convergence. Second, historical representations grow unbounded and lack structure, preventing effective reuse of cached states and severely limiting inference efficiency. To address these challenges, we propose Neighbor Forcing, a diffusion-step-consistent AR formulation that propagates temporally adjacent frames as latent neighbors under the same noise condition. This design provides a distribution-aligned and stable learning signal while preserving drifting throughout the AR chain. Building upon this, we introduce a structured ConvKV memory mechanism that compresses the keys and values in causal attention into a fixed-length representation, enabling constant-memory inference and truly infinite video generation without relying on short-term motion-frame memory. Extensive experiments demonstrate that our approach significantly improves training convergence, hour-scale generation quality, and inference efficiency compared to existing AR diffusion methods. Numerically, LiveAct enables hour-scale real-time human animation and supports 20 FPS real-time streaming inference on as few as two NVIDIA H100 or H200 GPUs. Quantitative results demonstrate that our method attains state-of-the-art performance in lip-sync accuracy, human animation quality, and emotional expressiveness, with the lowest inference cost.
CLOT: Closed-Loop Global Motion Tracking for Whole-Body Humanoid Teleoperation
Feb 13, 2026Long-horizon whole-body humanoid teleoperation remains challenging due to accumulated global pose drift, particularly on full-sized humanoids. Although recent learning-based tracking methods enable agile and coordinated motions, they typically operate in the robot's local frame and neglect global pose feedback, leading to drift and instability during extended execution. In this work, we present CLOT, a real-time whole-body humanoid teleoperation system that achieves closed-loop global motion tracking via high-frequency localization feedback. CLOT synchronizes operator and robot poses in a closed loop, enabling drift-free human-to-humanoid mimicry over long timehorizons. However, directly imposing global tracking rewards in reinforcement learning, often results in aggressive and brittle corrections. To address this, we propose a data-driven randomization strategy that decouples observation trajectories from reward evaluation, enabling smooth and stable global corrections. We further regularize the policy with an adversarial motion prior to suppress unnatural behaviors. To support CLOT, we collect 20 hours of carefully curated human motion data for training the humanoid teleoperation policy. We design a transformer-based policy and train it for over 1300 GPU hours. The policy is deployed on a full-sized humanoid with 31 DoF (excluding hands). Both simulation and real-world experiments verify high-dynamic motion, high-precision tracking, and strong robustness in sim-to-real humanoid teleoperation. Motion data, demos and code can be found in our website.
Stabilizing Diffusion Posterior Sampling by Noise--Frequency Continuation
Jan 30, 2026Diffusion posterior sampling solves inverse problems by combining a pretrained diffusion prior with measurement-consistency guidance, but it often fails to recover fine details because measurement terms are applied in a manner that is weakly coupled to the diffusion noise level. At high noise, data-consistency gradients computed from inaccurate estimates can be geometrically incongruent with the posterior geometry, inducing early-step drift, spurious high-frequency artifacts, plus sensitivity to schedules and ill-conditioned operators. To address these concerns, we propose a noise--frequency Continuation framework that constructs a continuous family of intermediate posteriors whose likelihood enforces measurement consistency only within a noise-dependent frequency band. This principle is instantiated with a stabilized posterior sampler that combines a diffusion predictor, band-limited likelihood guidance, and a multi-resolution consistency strategy that aggressively commits reliable coarse corrections while conservatively adopting high-frequency details only when they become identifiable. Across super-resolution, inpainting, and deblurring, our method achieves state-of-the-art performance and improves motion deblurring PSNR by up to 5 dB over strong baselines.
Fine-Grained Human Pose Editing Assessment via Layer-Selective MLLMs
Jan 15, 2026Text-guided human pose editing has gained significant traction in AIGC applications. However,it remains plagued by structural anomalies and generative artifacts. Existing evaluation metrics often isolate authenticity detection from quality assessment, failing to provide fine-grained insights into pose-specific inconsistencies. To address these limitations, we introduce HPE-Bench, a specialized benchmark comprising 1,700 standardized samples from 17 state-of-the-art editing models, offering both authenticity labels and multi-dimensional quality scores. Furthermore, we propose a unified framework based on layer-selective multimodal large language models (MLLMs). By employing contrastive LoRA tuning and a novel layer sensitivity analysis (LSA) mechanism, we identify the optimal feature layer for pose evaluation. Our framework achieves superior performance in both authenticity detection and multi-dimensional quality regression, effectively bridging the gap between forensic detection and quality assessment.
SingingBot: An Avatar-Driven System for Robotic Face Singing Performance
Jan 05, 2026Equipping robotic faces with singing capabilities is crucial for empathetic Human-Robot Interaction. However, existing robotic face driving research primarily focuses on conversations or mimicking static expressions, struggling to meet the high demands for continuous emotional expression and coherence in singing. To address this, we propose a novel avatar-driven framework for appealing robotic singing. We first leverage portrait video generation models embedded with extensive human priors to synthesize vivid singing avatars, providing reliable expression and emotion guidance. Subsequently, these facial features are transferred to the robot via semantic-oriented mapping functions that span a wide expression space. Furthermore, to quantitatively evaluate the emotional richness of robotic singing, we propose the Emotion Dynamic Range metric to measure the emotional breadth within the Valence-Arousal space, revealing that a broad emotional spectrum is crucial for appealing performances. Comprehensive experiments prove that our method achieves rich emotional expressions while maintaining lip-audio synchronization, significantly outperforming existing approaches.
POLAR: A Portrait OLAT Dataset and Generative Framework for Illumination-Aware Face Modeling
Dec 16, 2025Face relighting aims to synthesize realistic portraits under novel illumination while preserving identity and geometry. However, progress remains constrained by the limited availability of large-scale, physically consistent illumination data. To address this, we introduce POLAR, a large-scale and physically calibrated One-Light-at-a-Time (OLAT) dataset containing over 200 subjects captured under 156 lighting directions, multiple views, and diverse expressions. Building upon POLAR, we develop a flow-based generative model POLARNet that predicts per-light OLAT responses from a single portrait, capturing fine-grained and direction-aware illumination effects while preserving facial identity. Unlike diffusion or background-conditioned methods that rely on statistical or contextual cues, our formulation models illumination as a continuous, physically interpretable transformation between lighting states, enabling scalable and controllable relighting. Together, POLAR and POLARNet form a unified illumination learning framework that links real data, generative synthesis, and physically grounded relighting, establishing a self-sustaining "chicken-and-egg" cycle for scalable and reproducible portrait illumination. Our project page: https://rex0191.github.io/POLAR/.
MoRE: 3D Visual Geometry Reconstruction Meets Mixture-of-Experts
Oct 31, 2025Recent advances in language and vision have demonstrated that scaling up model capacity consistently improves performance across diverse tasks. In 3D visual geometry reconstruction, large-scale training has likewise proven effective for learning versatile representations. However, further scaling of 3D models is challenging due to the complexity of geometric supervision and the diversity of 3D data. To overcome these limitations, we propose MoRE, a dense 3D visual foundation model based on a Mixture-of-Experts (MoE) architecture that dynamically routes features to task-specific experts, allowing them to specialize in complementary data aspects and enhance both scalability and adaptability. Aiming to improve robustness under real-world conditions, MoRE incorporates a confidence-based depth refinement module that stabilizes and refines geometric estimation. In addition, it integrates dense semantic features with globally aligned 3D backbone representations for high-fidelity surface normal prediction. MoRE is further optimized with tailored loss functions to ensure robust learning across diverse inputs and multiple geometric tasks. Extensive experiments demonstrate that MoRE achieves state-of-the-art performance across multiple benchmarks and supports effective downstream applications without extra computation.
Perceiving and Acting in First-Person: A Dataset and Benchmark for Egocentric Human-Object-Human Interactions
Aug 06, 2025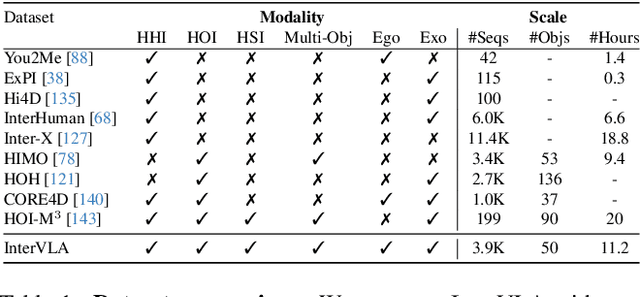

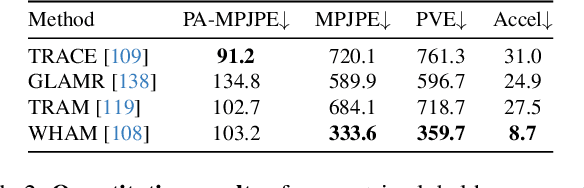

Learning action models from real-world human-centric interaction datasets is important towards building general-purpose intelligent assistants with efficiency. However, most existing datasets only offer specialist interaction category and ignore that AI assistants perceive and act based on first-person acquisition. We urge that both the generalist interaction knowledge and egocentric modality are indispensable. In this paper, we embed the manual-assisted task into a vision-language-action framework, where the assistant provides services to the instructor following egocentric vision and commands. With our hybrid RGB-MoCap system, pairs of assistants and instructors engage with multiple objects and the scene following GPT-generated scripts. Under this setting, we accomplish InterVLA, the first large-scale human-object-human interaction dataset with 11.4 hours and 1.2M frames of multimodal data, spanning 2 egocentric and 5 exocentric videos, accurate human/object motions and verbal commands. Furthermore, we establish novel benchmarks on egocentric human motion estimation, interaction synthesis, and interaction prediction with comprehensive analysis. We believe that our InterVLA testbed and the benchmarks will foster future works on building AI agents in the physical world.
MARS: Mesh AutoRegressive Model for 3D Shape Detailization
Feb 17, 2025

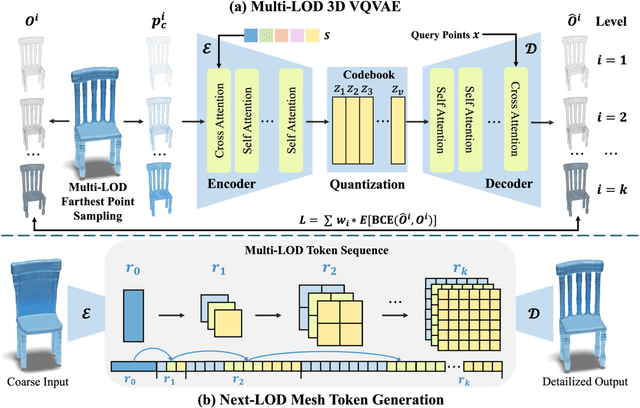

State-of-the-art methods for mesh detailization predominantly utilize Generative Adversarial Networks (GANs) to generate detailed meshes from coarse ones. These methods typically learn a specific style code for each category or similar categories without enforcing geometry supervision across different Levels of Detail (LODs). Consequently, such methods often fail to generalize across a broader range of categories and cannot ensure shape consistency throughout the detailization process. In this paper, we introduce MARS, a novel approach for 3D shape detailization. Our method capitalizes on a novel multi-LOD, multi-category mesh representation to learn shape-consistent mesh representations in latent space across different LODs. We further propose a mesh autoregressive model capable of generating such latent representations through next-LOD token prediction. This approach significantly enhances the realism of the generated shapes. Extensive experiments conducted on the challenging 3D Shape Detailization benchmark demonstrate that our proposed MARS model achieves state-of-the-art performance, surpassing existing methods in both qualitative and quantitative assessments. Notably, the model's capability to generate fine-grained details while preserving the overall shape integrity is particularly commendable.
Disentangled Clothed Avatar Generation with Layered Representation
Jan 08, 2025



Clothed avatar generation has wide applications in virtual and augmented reality, filmmaking, and more. Previous methods have achieved success in generating diverse digital avatars, however, generating avatars with disentangled components (\eg, body, hair, and clothes) has long been a challenge. In this paper, we propose LayerAvatar, the first feed-forward diffusion-based method for generating component-disentangled clothed avatars. To achieve this, we first propose a layered UV feature plane representation, where components are distributed in different layers of the Gaussian-based UV feature plane with corresponding semantic labels. This representation supports high-resolution and real-time rendering, as well as expressive animation including controllable gestures and facial expressions. Based on the well-designed representation, we train a single-stage diffusion model and introduce constrain terms to address the severe occlusion problem of the innermost human body layer. Extensive experiments demonstrate the impressive performances of our method in generating disentangled clothed avatars, and we further explore its applications in component transfer. The project page is available at: https://olivia23333.github.io/LayerAvatar/