 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Consistent Video Geometry Estimation
May 28, 2026This work presents ViGeo, a feed-forward foundation model for recovering spatially dense and temporally consistent geometry from video sequences. Built upon a plain transformer architecture without task-specific architectural modifications, ViGeo supports streaming, full-sequence, and long-video inference within a unified model. The key design is dynamic chunking attention, which exposes the model to both bidirectional and causal temporal contexts during training and allows it to adapt its attention pattern at test time without retraining. To improve supervision quality, we further introduce a completion-based data refinement framework. This framework trains a video depth completion teacher that conditions on sparse and noisy annotations and exploits video/multi-view context to produce dense, temporally coherent, and geometrically reliable training targets. Beyond depth and point maps, ViGeo also predicts surface normals within the same framework. Trained solely on public datasets, ViGeo achieves state-of-the-art performance across online, offline, and long-video depth estimation, surface normal estimation, and video point map estimation.
R3DP: Real-Time 3D-Aware Policy for Embodied Manipulation
Mar 15, 2026Embodied manipulation requires accurate 3D understanding of objects and their spatial relations to plan and execute contact-rich actions. While large-scale 3D vision models provide strong priors, their computational cost incurs prohibitive latency for real-time control. We propose Real-time 3D-aware Policy (R3DP), which integrates powerful 3D priors into manipulation policies without sacrificing real-time performance. A core innovation of R3DP is the asynchronous fast-slow collaboration module, which seamlessly integrates large-scale 3D priors into the policy without compromising real-time performance. The system maintains real-time efficiency by querying the pre-trained slow system (VGGT) only on sparse key frames, while simultaneously employing a lightweight Temporal Feature Prediction Network (TFPNet) to predict features for all intermediate frames. By leveraging historical data to exploit temporal correlations, TFPNet explicitly improves task success rates through consistent feature estimation. Additionally, to enable more effective multi-view fusion, we introduce a Multi-View Feature Fuser (MVFF) that aggregates features across views by explicitly incorporating camera intrinsics and extrinsics. R3DP offers a plug-and-play solution for integrating large models into real-time inference systems. We evaluate R3DP against multiple baselines across different visual configurations. R3DP effectively harnesses large-scale 3D priors to achieve superior results, outperforming single-view and multi-view DP by 32.9% and 51.4% in average success rate, respectively. Furthermore, by decoupling heavy 3D reasoning from policy execution, R3DP achieves a 44.8% reduction in inference time compared to a naive DP+VGGT integration.
SurfSplat: Conquering Feedforward 2D Gaussian Splatting with Surface Continuity Priors
Feb 03, 2026Reconstructing 3D scenes from sparse images remains a challenging task due to the difficulty of recovering accurate geometry and texture without optimization. Recent approaches leverage generalizable models to generate 3D scenes using 3D Gaussian Splatting (3DGS) primitive. However, they often fail to produce continuous surfaces and instead yield discrete, color-biased point clouds that appear plausible at normal resolution but reveal severe artifacts under close-up views. To address this issue, we present SurfSplat, a feedforward framework based on 2D Gaussian Splatting (2DGS) primitive, which provides stronger anisotropy and higher geometric precision. By incorporating a surface continuity prior and a forced alpha blending strategy, SurfSplat reconstructs coherent geometry together with faithful textures. Furthermore, we introduce High-Resolution Rendering Consistency (HRRC), a new evaluation metric designed to evaluate high-resolution reconstruction quality. Extensive experiments on RealEstate10K, DL3DV, and ScanNet demonstrate that SurfSplat consistently outperforms prior methods on both standard metrics and HRRC, establishing a robust solution for high-fidelity 3D reconstruction from sparse inputs. Project page: https://hebing-sjtu.github.io/SurfSplat-website/
POLAR: A Portrait OLAT Dataset and Generative Framework for Illumination-Aware Face Modeling
Dec 16, 2025Face relighting aims to synthesize realistic portraits under novel illumination while preserving identity and geometry. However, progress remains constrained by the limited availability of large-scale, physically consistent illumination data. To address this, we introduce POLAR, a large-scale and physically calibrated One-Light-at-a-Time (OLAT) dataset containing over 200 subjects captured under 156 lighting directions, multiple views, and diverse expressions. Building upon POLAR, we develop a flow-based generative model POLARNet that predicts per-light OLAT responses from a single portrait, capturing fine-grained and direction-aware illumination effects while preserving facial identity. Unlike diffusion or background-conditioned methods that rely on statistical or contextual cues, our formulation models illumination as a continuous, physically interpretable transformation between lighting states, enabling scalable and controllable relighting. Together, POLAR and POLARNet form a unified illumination learning framework that links real data, generative synthesis, and physically grounded relighting, establishing a self-sustaining "chicken-and-egg" cycle for scalable and reproducible portrait illumination. Our project page: https://rex0191.github.io/POLAR/.
MoRE: 3D Visual Geometry Reconstruction Meets Mixture-of-Experts
Oct 31, 2025Recent advances in language and vision have demonstrated that scaling up model capacity consistently improves performance across diverse tasks. In 3D visual geometry reconstruction, large-scale training has likewise proven effective for learning versatile representations. However, further scaling of 3D models is challenging due to the complexity of geometric supervision and the diversity of 3D data. To overcome these limitations, we propose MoRE, a dense 3D visual foundation model based on a Mixture-of-Experts (MoE) architecture that dynamically routes features to task-specific experts, allowing them to specialize in complementary data aspects and enhance both scalability and adaptability. Aiming to improve robustness under real-world conditions, MoRE incorporates a confidence-based depth refinement module that stabilizes and refines geometric estimation. In addition, it integrates dense semantic features with globally aligned 3D backbone representations for high-fidelity surface normal prediction. MoRE is further optimized with tailored loss functions to ensure robust learning across diverse inputs and multiple geometric tasks. Extensive experiments demonstrate that MoRE achieves state-of-the-art performance across multiple benchmarks and supports effective downstream applications without extra computation.
MARS: Mesh AutoRegressive Model for 3D Shape Detailization
Feb 17, 2025

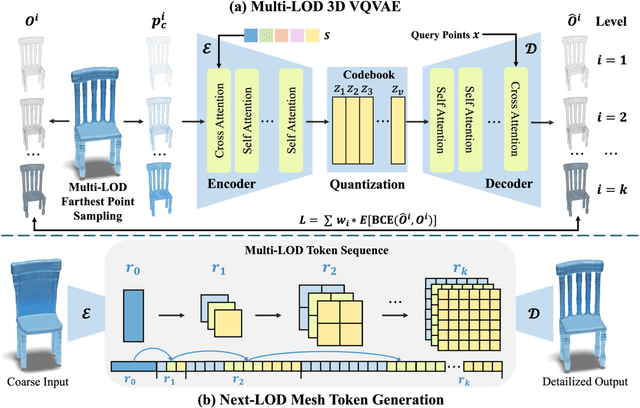

State-of-the-art methods for mesh detailization predominantly utilize Generative Adversarial Networks (GANs) to generate detailed meshes from coarse ones. These methods typically learn a specific style code for each category or similar categories without enforcing geometry supervision across different Levels of Detail (LODs). Consequently, such methods often fail to generalize across a broader range of categories and cannot ensure shape consistency throughout the detailization process. In this paper, we introduce MARS, a novel approach for 3D shape detailization. Our method capitalizes on a novel multi-LOD, multi-category mesh representation to learn shape-consistent mesh representations in latent space across different LODs. We further propose a mesh autoregressive model capable of generating such latent representations through next-LOD token prediction. This approach significantly enhances the realism of the generated shapes. Extensive experiments conducted on the challenging 3D Shape Detailization benchmark demonstrate that our proposed MARS model achieves state-of-the-art performance, surpassing existing methods in both qualitative and quantitative assessments. Notably, the model's capability to generate fine-grained details while preserving the overall shape integrity is particularly commendable.
AniSDF: Fused-Granularity Neural Surfaces with Anisotropic Encoding for High-Fidelity 3D Reconstruction
Oct 02, 2024Neural radiance fields have recently revolutionized novel-view synthesis and achieved high-fidelity renderings. However, these methods sacrifice the geometry for the rendering quality, limiting their further applications including relighting and deformation. How to synthesize photo-realistic rendering while reconstructing accurate geometry remains an unsolved problem. In this work, we present AniSDF, a novel approach that learns fused-granularity neural surfaces with physics-based encoding for high-fidelity 3D reconstruction. Different from previous neural surfaces, our fused-granularity geometry structure balances the overall structures and fine geometric details, producing accurate geometry reconstruction. To disambiguate geometry from reflective appearance, we introduce blended radiance fields to model diffuse and specularity following the anisotropic spherical Gaussian encoding, a physics-based rendering pipeline. With these designs, AniSDF can reconstruct objects with complex structures and produce high-quality renderings. Furthermore, our method is a unified model that does not require complex hyperparameter tuning for specific objects. Extensive experiments demonstrate that our method boosts the quality of SDF-based methods by a great scale in both geometry reconstruction and novel-view synthesis.
Multi-times Monte Carlo Rendering for Inter-reflection Reconstruction
Jul 08, 2024Inverse rendering methods have achieved remarkable performance in reconstructing high-fidelity 3D objects with disentangled geometries, materials, and environmental light. However, they still face huge challenges in reflective surface reconstruction. Although recent methods model the light trace to learn specularity, the ignorance of indirect illumination makes it hard to handle inter-reflections among multiple smooth objects. In this work, we propose Ref-MC2 that introduces the multi-time Monte Carlo sampling which comprehensively computes the environmental illumination and meanwhile considers the reflective light from object surfaces. To address the computation challenge as the times of Monte Carlo sampling grow, we propose a specularity-adaptive sampling strategy, significantly reducing the computational complexity. Besides the computational resource, higher geometry accuracy is also required because geometric errors accumulate multiple times. Therefore, we further introduce a reflection-aware surface model to initialize the geometry and refine it during inverse rendering. We construct a challenging dataset containing scenes with multiple objects and inter-reflections. Experiments show that our method outperforms other inverse rendering methods on various object groups. We also show downstream applications, e.g., relighting and material editing, to illustrate the disentanglement ability of our method.
A Comparative Study of Perceptual Quality Metrics for Audio-driven Talking Head Videos
Mar 11, 2024The rapid advancement of Artificial Intelligence Generated Content (AIGC) technology has propelled audio-driven talking head generation, gaining considerable research attention for practical applications. However, performance evaluation research lags behind the development of talking head generation techniques. Existing literature relies on heuristic quantitative metrics without human validation, hindering accurate progress assessment. To address this gap, we collect talking head videos generated from four generative methods and conduct controlled psychophysical experiments on visual quality, lip-audio synchronization, and head movement naturalness. Our experiments validate consistency between model predictions and human annotations, identifying metrics that align better with human opinions than widely-used measures. We believe our work will facilitate performance evaluation and model development, providing insights into AIGC in a broader context. Code and data will be made available at https://github.com/zwx8981/ADTH-QA.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023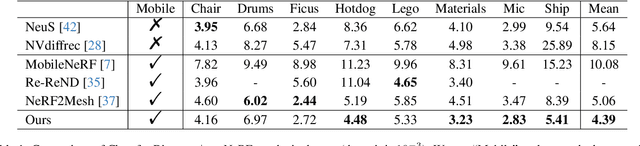
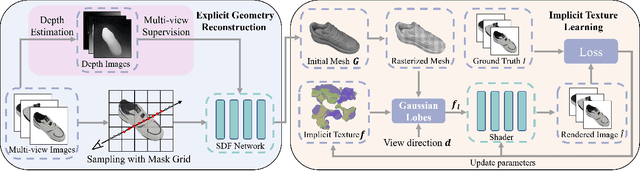
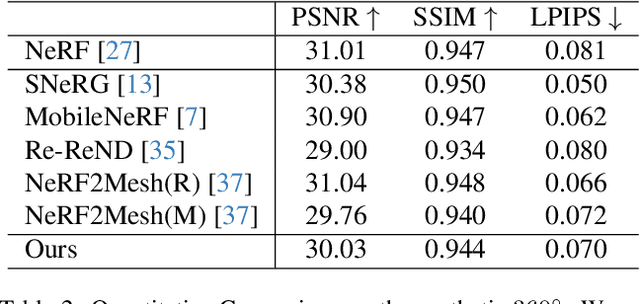
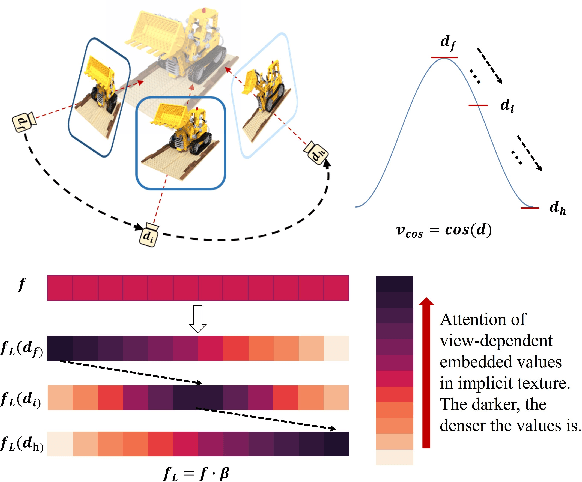
Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.