 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHint-Guided Diversified Policy Optimization for LLM Reasoning
Jun 02, 2026Recent developments in Large Language Models (LLMs) have showcased impressive reasoning capabilities, with Reinforcement Learning with Verifiable Rewards (RLVR) being a promising enhancement strategy. However, existing reward mechanisms are constrained to the outcome-level correctness and lack explicit signals to guide the model to consider diverse solutions. In contrast, human problem solving typically involves evaluating multiple potential approaches and selecting the most reliable solution, a cognitive process that current RLVR frameworks do not explicitly incentivize. Inspired by this, we propose Hint-Guided Diversified Policy Optimization (HDPO), allowing the model to first list all potential candidate solution outlines as hints and then select the most reliable one for further reasoning. HDPO comprises two stages of Cold Start for Structured Reasoning and Hint-Guided Diversified Reinforcement Learning to incentivize the model to generate diverse and reliable solutions following the ``propose-select-think'' trajectory. Experimental results show that HDPO effectively boosts LLM reasoning and enhances the diversity of candidate solutions as well as the LLM's ability to identify reliable solutions.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
Neural Functional Alignment Space: Brain-Referenced Representation of Artificial Neural Networks
Feb 28, 2026We propose the Neural Functional Alignment Space (NFAS), a brain-referenced representational framework for characterizing artificial neural networks on equal functional grounds. NFAS departs from conventional alignment approaches that rely on layer-wise features or task-specific activations by modeling the intrinsic dynamical evolution of stimulus representations across network depth. Specifically, we model layer-wise embeddings as a depth-wise dynamical trajectory and apply Dynamic Mode Decomposition (DMD) to extract the stable mode. This representation is then projected into a biologically anchored coordinate system defined by distributed neural responses. We also introduce the Signal-to-Noise Consistency Index (SNCI) to quantify cross-model consistency at the modality level. Across 45 pretrained models spanning vision, audio, and language, NFAS reveals structured organization within this brain-referenced space, including modality-specific clustering and cross-modal convergence in integrative cortical systems. Our findings suggest that representation dynamics provide a principled basis for
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
SPRMamba: Surgical Phase Recognition for Endoscopic Submucosal Dissection with Mamba
Sep 18, 2024



Endoscopic Submucosal Dissection (ESD) is a minimally invasive procedure initially designed for the treatment of early gastric cancer but is now widely used for various gastrointestinal lesions. Computer-assisted Surgery systems have played a crucial role in improving the precision and safety of ESD procedures, however, their effectiveness is limited by the accurate recognition of surgical phases. The intricate nature of ESD, with different lesion characteristics and tissue structures, presents challenges for real-time surgical phase recognition algorithms. Existing surgical phase recognition algorithms struggle to efficiently capture temporal contexts in video-based scenarios, leading to insufficient performance. To address these issues, we propose SPRMamba, a novel Mamba-based framework for ESD surgical phase recognition. SPRMamba leverages the strengths of Mamba for long-term temporal modeling while introducing the Scaled Residual TranMamba block to enhance the capture of fine-grained details, overcoming the limitations of traditional temporal models like Temporal Convolutional Networks and Transformers. Moreover, a Temporal Sample Strategy is introduced to accelerate the processing, which is essential for real-time phase recognition in clinical settings. Extensive testing on the ESD385 dataset and the cholecystectomy Cholec80 dataset demonstrates that SPRMamba surpasses existing state-of-the-art methods and exhibits greater robustness across various surgical phase recognition tasks.
ALSS-YOLO: An Adaptive Lightweight Channel Split and Shuffling Network for TIR Wildlife Detection in UAV Imagery
Sep 10, 2024
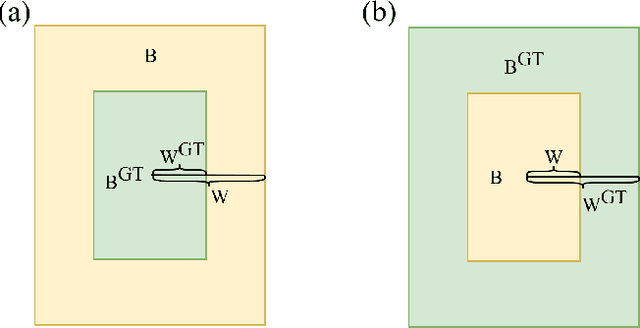
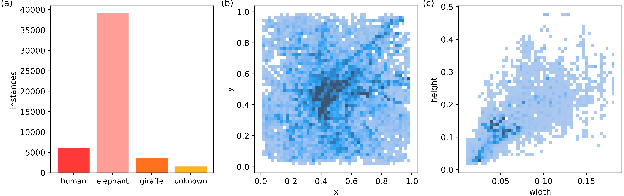
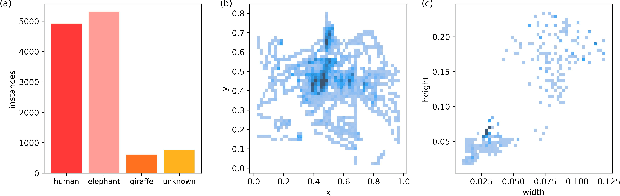
Unmanned aerial vehicles (UAVs) equipped with thermal infrared (TIR) cameras play a crucial role in combating nocturnal wildlife poaching. However, TIR images often face challenges such as jitter, and wildlife overlap, necessitating UAVs to possess the capability to identify blurred and overlapping small targets. Current traditional lightweight networks deployed on UAVs struggle to extract features from blurry small targets. To address this issue, we developed ALSS-YOLO, an efficient and lightweight detector optimized for TIR aerial images. Firstly, we propose a novel Adaptive Lightweight Channel Split and Shuffling (ALSS) module. This module employs an adaptive channel split strategy to optimize feature extraction and integrates a channel shuffling mechanism to enhance information exchange between channels. This improves the extraction of blurry features, crucial for handling jitter-induced blur and overlapping targets. Secondly, we developed a Lightweight Coordinate Attention (LCA) module that employs adaptive pooling and grouped convolution to integrate feature information across dimensions. This module ensures lightweight operation while maintaining high detection precision and robustness against jitter and target overlap. Additionally, we developed a single-channel focus module to aggregate the width and height information of each channel into four-dimensional channel fusion, which improves the feature representation efficiency of infrared images. Finally, we modify the localization loss function to emphasize the loss value associated with small objects to improve localization accuracy. Extensive experiments on the BIRDSAI and ISOD TIR UAV wildlife datasets show that ALSS-YOLO achieves state-of-the-art performance, Our code is openly available at https://github.com/helloworlder8/computer_vision.
CSST Strong Lensing Preparation: a Framework for Detecting Strong Lenses in the Multi-color Imaging Survey by the China Survey Space Telescope (CSST)
Apr 02, 2024Strong gravitational lensing is a powerful tool for investigating dark matter and dark energy properties. With the advent of large-scale sky surveys, we can discover strong lensing systems on an unprecedented scale, which requires efficient tools to extract them from billions of astronomical objects. The existing mainstream lens-finding tools are based on machine learning algorithms and applied to cut-out-centered galaxies. However, according to the design and survey strategy of optical surveys by CSST, preparing cutouts with multiple bands requires considerable efforts. To overcome these challenges, we have developed a framework based on a hierarchical visual Transformer with a sliding window technique to search for strong lensing systems within entire images. Moreover, given that multi-color images of strong lensing systems can provide insights into their physical characteristics, our framework is specifically crafted to identify strong lensing systems in images with any number of channels. As evaluated using CSST mock data based on an Semi-Analytic Model named CosmoDC2, our framework achieves precision and recall rates of 0.98 and 0.90, respectively. To evaluate the effectiveness of our method in real observations, we have applied it to a subset of images from the DESI Legacy Imaging Surveys and media images from Euclid Early Release Observations. 61 new strong lensing system candidates are discovered by our method. However, we also identified false positives arising primarily from the simplified galaxy morphology assumptions within the simulation. This underscores the practical limitations of our approach while simultaneously highlighting potential avenues for future improvements.
ITEM3D: Illumination-Aware Directional Texture Editing for 3D Models
Sep 27, 2023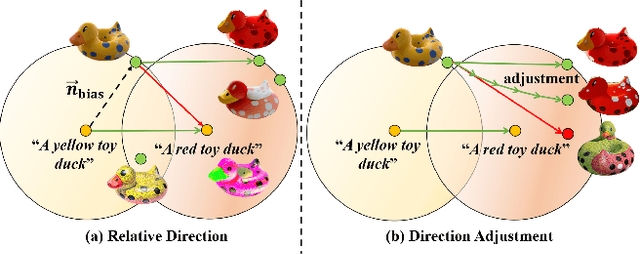

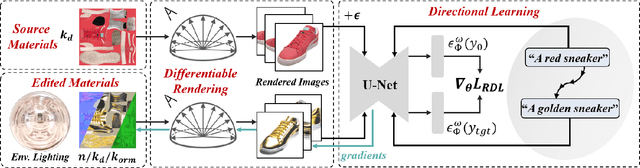

Texture editing is a crucial task in 3D modeling that allows users to automatically manipulate the surface materials of 3D models. However, the inherent complexity of 3D models and the ambiguous text description lead to the challenge in this task. To address this challenge, we propose ITEM3D, an illumination-aware model for automatic 3D object editing according to the text prompts. Leveraging the diffusion models and the differentiable rendering, ITEM3D takes the rendered images as the bridge of text and 3D representation, and further optimizes the disentangled texture and environment map. Previous methods adopt the absolute editing direction namely score distillation sampling (SDS) as the optimization objective, which unfortunately results in the noisy appearance and text inconsistency. To solve the problem caused by the ambiguous text, we introduce a relative editing direction, an optimization objective defined by the noise difference between the source and target texts, to release the semantic ambiguity between the texts and images. Additionally, we gradually adjust the direction during optimization to further address the unexpected deviation in the texture domain. Qualitative and quantitative experiments show that our ITEM3D outperforms the state-of-the-art methods on various 3D objects. We also perform text-guided relighting to show explicit control over lighting.
CAMP-Net: Context-Aware Multi-Prior Network for Accelerated MRI Reconstruction
Jun 20, 2023



Despite promising advances in deep learning-based MRI reconstruction methods, restoring high-frequency image details and textures remains a challenging problem for accelerated MRI. To tackle this challenge, we propose a novel context-aware multi-prior network (CAMP-Net) for MRI reconstruction. CAMP-Net leverages the complementary nature of multiple prior knowledge and explores data redundancy between adjacent slices in the hybrid domain to improve image quality. It incorporates three interleaved modules respectively for image enhancement, k-space restoration, and calibration consistency to jointly learn context-aware multiple priors in an end-to-end fashion. The image enhancement module learns a coil-combined image prior to suppress noise-like artifacts, while the k-space restoration module explores multi-coil k-space correlations to recover high-frequency details. The calibration consistency module embeds the known physical properties of MRI acquisition to ensure consistency of k-space correlations extracted from measurements and the artifact-free image intermediate. The resulting low- and high-frequency reconstructions are hierarchically aggregated in a frequency fusion module and iteratively refined to progressively reconstruct the final image. We evaluated the generalizability and robustness of our method on three large public datasets with various accelerations and sampling patterns. Comprehensive experiments demonstrate that CAMP-Net outperforms state-of-the-art methods in terms of reconstruction quality and quantitative $T_2$ mapping.
GANHead: Towards Generative Animatable Neural Head Avatars
Apr 08, 2023



To bring digital avatars into people's lives, it is highly demanded to efficiently generate complete, realistic, and animatable head avatars. This task is challenging, and it is difficult for existing methods to satisfy all the requirements at once. To achieve these goals, we propose GANHead (Generative Animatable Neural Head Avatar), a novel generative head model that takes advantages of both the fine-grained control over the explicit expression parameters and the realistic rendering results of implicit representations. Specifically, GANHead represents coarse geometry, fine-gained details and texture via three networks in canonical space to obtain the ability to generate complete and realistic head avatars. To achieve flexible animation, we define the deformation filed by standard linear blend skinning (LBS), with the learned continuous pose and expression bases and LBS weights. This allows the avatars to be directly animated by FLAME parameters and generalize well to unseen poses and expressions. Compared to state-of-the-art (SOTA) methods, GANHead achieves superior performance on head avatar generation and raw scan fitting.