 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Retoucher for Text-To-Image Generation
Jan 08, 2026Text-to-image (T2I) diffusion models such as SDXL and FLUX have achieved impressive photorealism, yet small-scale distortions remain pervasive in limbs, face, text and so on. Existing refinement approaches either perform costly iterative re-generation or rely on vision-language models (VLMs) with weak spatial grounding, leading to semantic drift and unreliable local edits. To close this gap, we propose Agentic Retoucher, a hierarchical decision-driven framework that reformulates post-generation correction as a human-like perception-reasoning-action loop. Specifically, we design (1) a perception agent that learns contextual saliency for fine-grained distortion localization under text-image consistency cues, (2) a reasoning agent that performs human-aligned inferential diagnosis via progressive preference alignment, and (3) an action agent that adaptively plans localized inpainting guided by user preference. This design integrates perceptual evidence, linguistic reasoning, and controllable correction into a unified, self-corrective decision process. To enable fine-grained supervision and quantitative evaluation, we further construct GenBlemish-27K, a dataset of 6K T2I images with 27K annotated artifact regions across 12 categories. Extensive experiments demonstrate that Agentic Retoucher consistently outperforms state-of-the-art methods in perceptual quality, distortion localization and human preference alignment, establishing a new paradigm for self-corrective and perceptually reliable T2I generation.
Controllable Image Colorization with Instance-aware Texts and Masks
May 13, 2025Recently, the application of deep learning in image colorization has received widespread attention. The maturation of diffusion models has further advanced the development of image colorization models. However, current mainstream image colorization models still face issues such as color bleeding and color binding errors, and cannot colorize images at the instance level. In this paper, we propose a diffusion-based colorization method MT-Color to achieve precise instance-aware colorization with use-provided guidance. To tackle color bleeding issue, we design a pixel-level mask attention mechanism that integrates latent features and conditional gray image features through cross-attention. We use segmentation masks to construct cross-attention masks, preventing pixel information from exchanging between different instances. We also introduce an instance mask and text guidance module that extracts instance masks and text representations of each instance, which are then fused with latent features through self-attention, utilizing instance masks to form self-attention masks to prevent instance texts from guiding the colorization of other areas, thus mitigating color binding errors. Furthermore, we apply a multi-instance sampling strategy, which involves sampling each instance region separately and then fusing the results. Additionally, we have created a specialized dataset for instance-level colorization tasks, GPT-color, by leveraging large visual language models on existing image datasets. Qualitative and quantitative experiments show that our model and dataset outperform previous methods and datasets.
FineVQ: Fine-Grained User Generated Content Video Quality Assessment
Dec 26, 2024



The rapid growth of user-generated content (UGC) videos has produced an urgent need for effective video quality assessment (VQA) algorithms to monitor video quality and guide optimization and recommendation procedures. However, current VQA models generally only give an overall rating for a UGC video, which lacks fine-grained labels for serving video processing and recommendation applications. To address the challenges and promote the development of UGC videos, we establish the first large-scale Fine-grained Video quality assessment Database, termed FineVD, which comprises 6104 UGC videos with fine-grained quality scores and descriptions across multiple dimensions. Based on this database, we propose a Fine-grained Video Quality assessment (FineVQ) model to learn the fine-grained quality of UGC videos, with the capabilities of quality rating, quality scoring, and quality attribution. Extensive experimental results demonstrate that our proposed FineVQ can produce fine-grained video-quality results and achieve state-of-the-art performance on FineVD and other commonly used UGC-VQA datasets. Both Both FineVD and FineVQ will be made publicly available.
F-Bench: Rethinking Human Preference Evaluation Metrics for Benchmarking Face Generation, Customization, and Restoration
Dec 17, 2024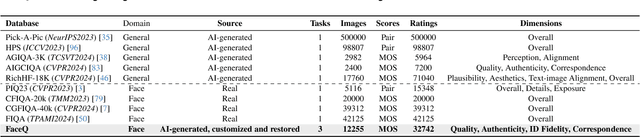



Artificial intelligence generative models exhibit remarkable capabilities in content creation, particularly in face image generation, customization, and restoration. However, current AI-generated faces (AIGFs) often fall short of human preferences due to unique distortions, unrealistic details, and unexpected identity shifts, underscoring the need for a comprehensive quality evaluation framework for AIGFs. To address this need, we introduce FaceQ, a large-scale, comprehensive database of AI-generated Face images with fine-grained Quality annotations reflecting human preferences. The FaceQ database comprises 12,255 images generated by 29 models across three tasks: (1) face generation, (2) face customization, and (3) face restoration. It includes 32,742 mean opinion scores (MOSs) from 180 annotators, assessed across multiple dimensions: quality, authenticity, identity (ID) fidelity, and text-image correspondence. Using the FaceQ database, we establish F-Bench, a benchmark for comparing and evaluating face generation, customization, and restoration models, highlighting strengths and weaknesses across various prompts and evaluation dimensions. Additionally, we assess the performance of existing image quality assessment (IQA), face quality assessment (FQA), AI-generated content image quality assessment (AIGCIQA), and preference evaluation metrics, manifesting that these standard metrics are relatively ineffective in evaluating authenticity, ID fidelity, and text-image correspondence. The FaceQ database will be publicly available upon publication.
Rate-Perception Optimized Preprocessing for Video Coding
Jan 25, 2023In the past decades, lots of progress have been done in the video compression field including traditional video codec and learning-based video codec. However, few studies focus on using preprocessing techniques to improve the rate-distortion performance. In this paper, we propose a rate-perception optimized preprocessing (RPP) method. We first introduce an adaptive Discrete Cosine Transform loss function which can save the bitrate and keep essential high frequency components as well. Furthermore, we also combine several state-of-the-art techniques from low-level vision fields into our approach, such as the high-order degradation model, efficient lightweight network design, and Image Quality Assessment model. By jointly using these powerful techniques, our RPP approach can achieve on average, 16.27% bitrate saving with different video encoders like AVC, HEVC, and VVC under multiple quality metrics. In the deployment stage, our RPP method is very simple and efficient which is not required any changes in the setting of video encoding, streaming, and decoding. Each input frame only needs to make a single pass through RPP before sending into video encoders. In addition, in our subjective visual quality test, 87% of users think videos with RPP are better or equal to videos by only using the codec to compress, while these videos with RPP save about 12% bitrate on average. Our RPP framework has been integrated into the production environment of our video transcoding services which serve millions of users every day.
Quality-Constant Per-Shot Encoding by Two-Pass Learning-based Rate Factor Prediction
Aug 23, 2022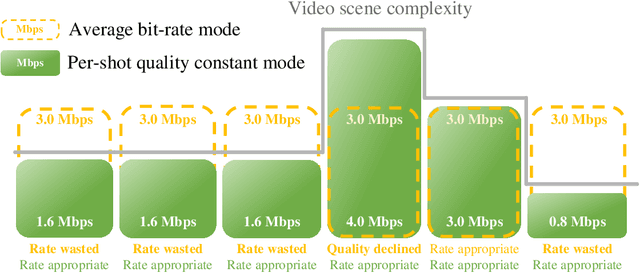

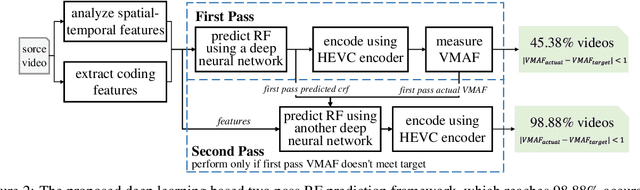
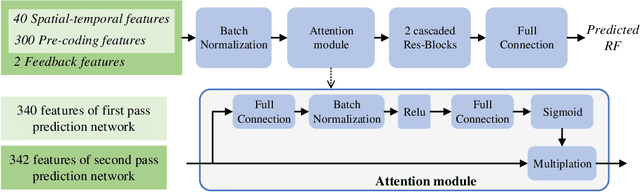
Providing quality-constant streams can simultaneously guarantee user experience and prevent wasting bit-rate. In this paper, we propose a novel deep learning based two-pass encoder parameter prediction framework to decide rate factor (RF), with which encoder can output streams with constant quality. For each one-shot segment in a video, the proposed method firstly extracts spatial, temporal and pre-coding features by an ultra fast pre-process. Based on these features, a RF parameter is predicted by a deep neural network. Video encoder uses the RF to compress segment as the first encoding pass. Then VMAF quality of the first pass encoding is measured. If the quality doesn't meet target, a second pass RF prediction and encoding will be performed. With the help of first pass predicted RF and corresponding actual quality as feedback, the second pass prediction will be highly accurate. Experiments show the proposed method requires only 1.55 times encoding complexity on average, meanwhile the accuracy, that the compressed video's actual VMAF is within $\pm1$ around the target VMAF, reaches 98.88%.
Content Adaptive and Error Propagation Aware Deep Video Compression
Mar 25, 2020
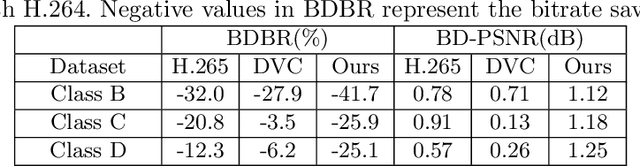

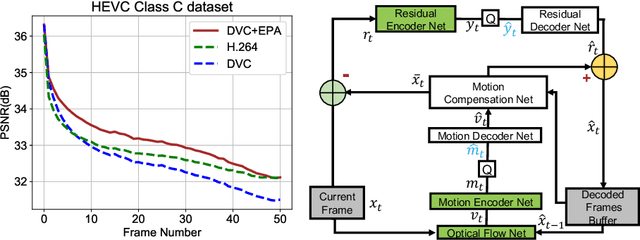
Recently, learning based video compression methods attract increasing attention. However, the previous works suffer from error propagation due to the accumulation of reconstructed error in inter predictive coding. Meanwhile, the previous learning based video codecs are also not adaptive to different video contents. To address these two problems, we propose a content adaptive and error propagation aware video compression system. Specifically, our method employs a joint training strategy by considering the compression performance of multiple consecutive frames instead of a single frame. Based on the learned long-term temporal information, our approach effectively alleviates error propagation in reconstructed frames. More importantly, instead of using the hand-crafted coding modes in the traditional compression systems, we design an online encoder updating scheme in our system. The proposed approach updates the parameters for encoder according to the rate-distortion criterion but keeps the decoder unchanged in the inference stage. Therefore, the encoder is adaptive to different video contents and achieves better compression performance by reducing the domain gap between the training and testing datasets. Our method is simple yet effective and outperforms the state-of-the-art learning based video codecs on benchmark datasets without increasing the model size or decreasing the decoding speed.
DVC: An End-to-end Deep Video Compression Framework
Nov 30, 2018

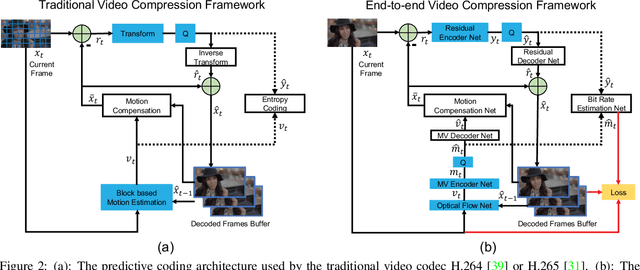
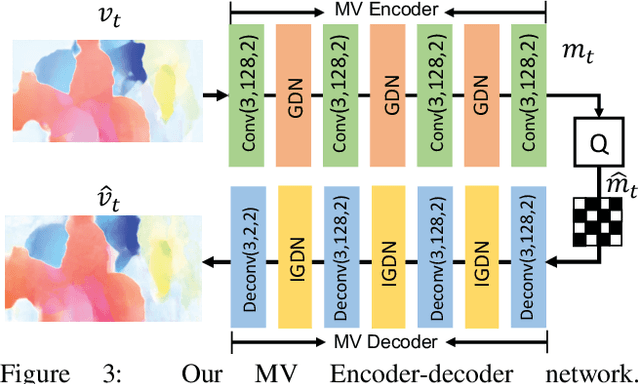
Conventional video compression approaches use the predictive coding architecture and encode the corresponding motion information and residual information. In this paper, taking advantage of both classical architecture in the conventional video compression method and the powerful non-linear representation ability of neural networks, we propose the first end-to-end video compression deep model that jointly optimizes all the components for video compression. Specifically, learning based optical flow estimation is utilized to obtain the motion information and reconstruct the current frames. Then we employ two auto-encoder style neural networks to compress the corresponding motion and residual information. All the modules are jointly learned through a single loss function, in which they collaborate with each other by considering the trade-off between reducing the number of compression bits and improving quality of the decoded video. Experimental results show that the proposed approach outperforms the widely used video coding standard H.264 in terms of PSNR and be even on par with the latest standard H.265 in terms of MS-SSIM. Code will be publicly available upon acceptance.