 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring bidirectional bounds for minimax-training of Energy-based models
Jun 05, 2025Energy-based models (EBMs) estimate unnormalized densities in an elegant framework, but they are generally difficult to train. Recent work has linked EBMs to generative adversarial networks, by noting that they can be trained through a minimax game using a variational lower bound. To avoid the instabilities caused by minimizing a lower bound, we propose to instead work with bidirectional bounds, meaning that we maximize a lower bound and minimize an upper bound when training the EBM. We investigate four different bounds on the log-likelihood derived from different perspectives. We derive lower bounds based on the singular values of the generator Jacobian and on mutual information. To upper bound the negative log-likelihood, we consider a gradient penalty-like bound, as well as one based on diffusion processes. In all cases, we provide algorithms for evaluating the bounds. We compare the different bounds to investigate, the pros and cons of the different approaches. Finally, we demonstrate that the use of bidirectional bounds stabilizes EBM training and yields high-quality density estimation and sample generation.
* accepted to IJCV
Enhanced Deep Animation Video Interpolation
Jun 25, 2022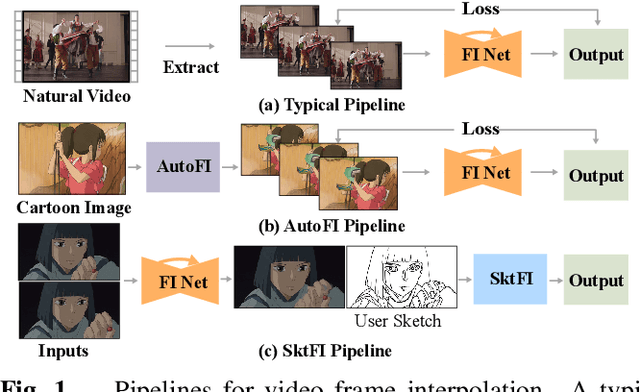

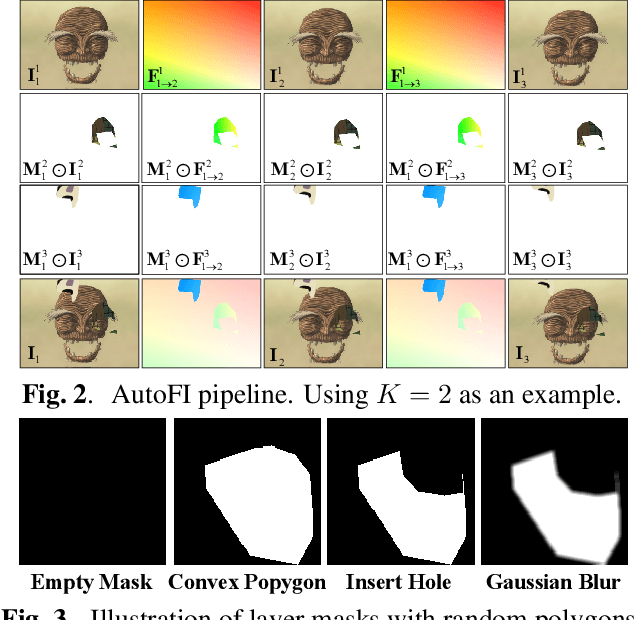
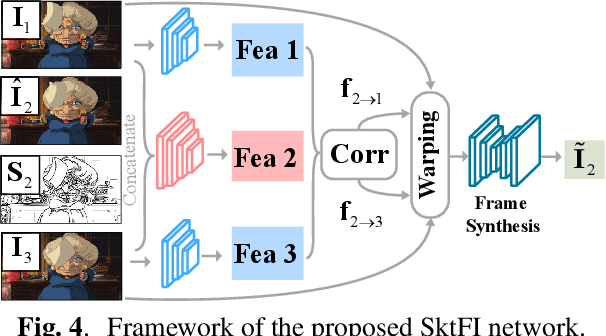
Existing learning-based frame interpolation algorithms extract consecutive frames from high-speed natural videos to train the model. Compared to natural videos, cartoon videos are usually in a low frame rate. Besides, the motion between consecutive cartoon frames is typically nonlinear, which breaks the linear motion assumption of interpolation algorithms. Thus, it is unsuitable for generating a training set directly from cartoon videos. For better adapting frame interpolation algorithms from nature video to animation video, we present AutoFI, a simple and effective method to automatically render training data for deep animation video interpolation. AutoFI takes a layered architecture to render synthetic data, which ensures the assumption of linear motion. Experimental results show that AutoFI performs favorably in training both DAIN and ANIN. However, most frame interpolation algorithms will still fail in error-prone areas, such as fast motion or large occlusion. Besides AutoFI, we also propose a plug-and-play sketch-based post-processing module, named SktFI, to refine the final results using user-provided sketches manually. With AutoFI and SktFI, the interpolated animation frames show high perceptual quality.
Perceptual Coding for Compressed Video Understanding: A New Framework and Benchmark
Feb 06, 2022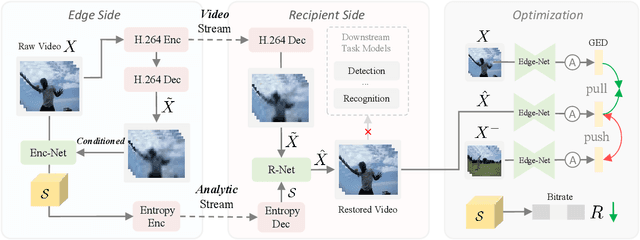
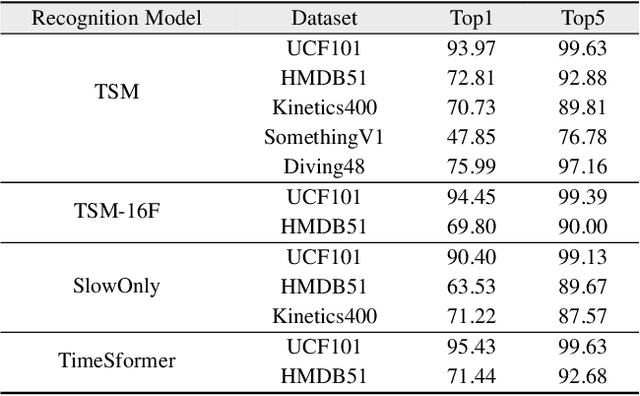
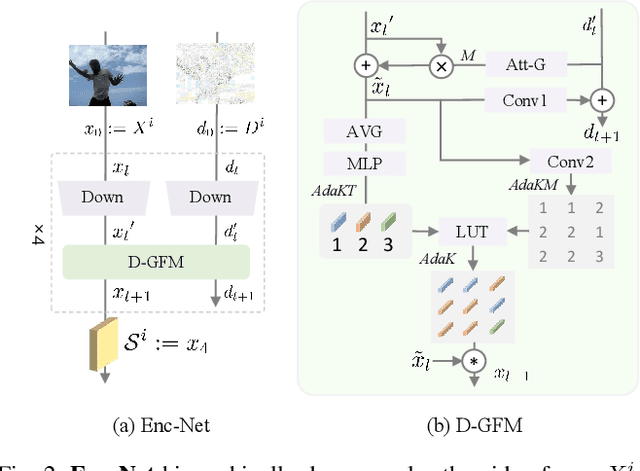
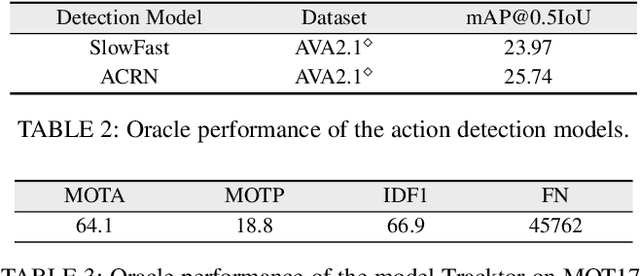
Most video understanding methods are learned on high-quality videos. However, in most real-world scenarios, the videos are first compressed before the transportation and then decompressed for understanding. The decompressed videos are degraded in terms of perceptual quality, which may degenerate the downstream tasks. To address this issue, we propose the first coding framework for compressed video understanding, where another learnable perceptual bitstream is introduced and simultaneously transported with the video bitstream. With the sophisticatedly designed optimization target and network architectures, this new stream largely boosts the perceptual quality of the decoded videos yet with a small bit cost. Our framework can enjoy the best of both two worlds, (1) highly efficient content-coding of industrial video codec and (2) flexible perceptual-coding of neural networks (NNs). Finally, we build a rigorous benchmark for compressed video understanding over four different compression levels, six large-scale datasets, and two popular tasks. The proposed Dual-bitstream Perceptual Video Coding framework Dual-PVC consistently demonstrates significantly stronger performances than the baseline codec under the same bitrate level.
Bounds all around: training energy-based models with bidirectional bounds
Nov 02, 2021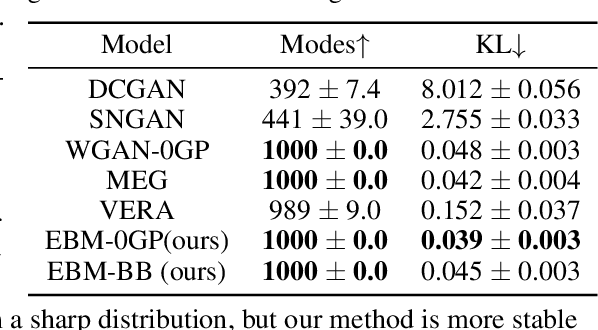
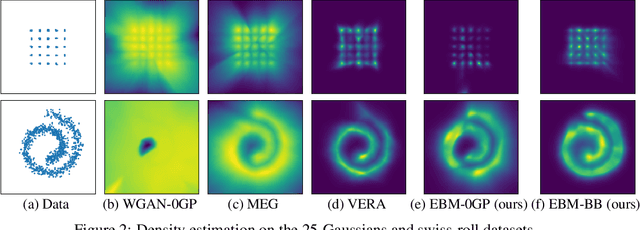
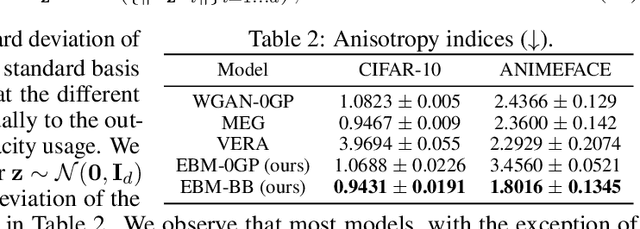
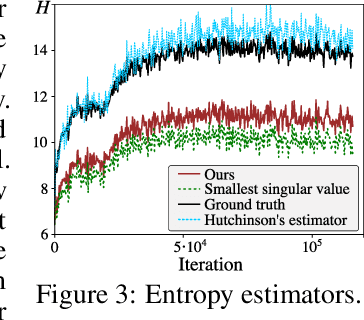
Energy-based models (EBMs) provide an elegant framework for density estimation, but they are notoriously difficult to train. Recent work has established links to generative adversarial networks, where the EBM is trained through a minimax game with a variational value function. We propose a bidirectional bound on the EBM log-likelihood, such that we maximize a lower bound and minimize an upper bound when solving the minimax game. We link one bound to a gradient penalty that stabilizes training, thereby providing grounding for best engineering practice. To evaluate the bounds we develop a new and efficient estimator of the Jacobi-determinant of the EBM generator. We demonstrate that these developments significantly stabilize training and yield high-quality density estimation and sample generation.
Self-Conditioned Probabilistic Learning of Video Rescaling
Aug 18, 2021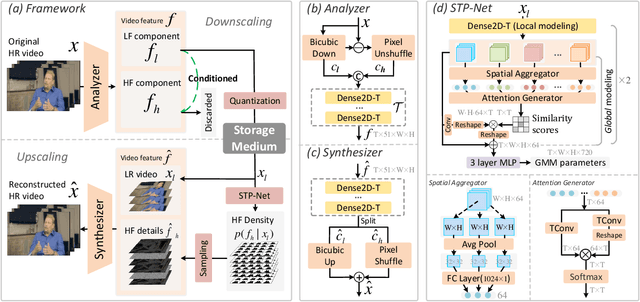
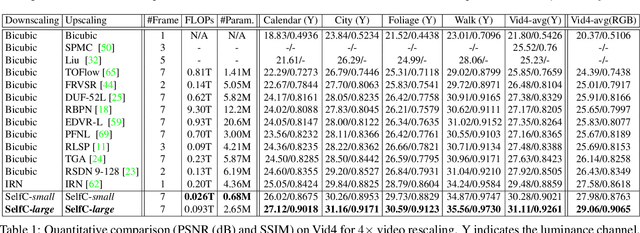
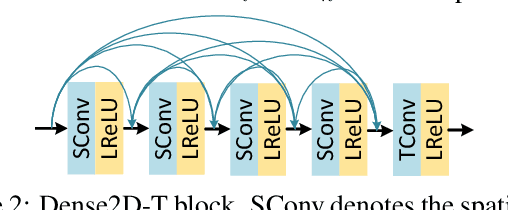

Bicubic downscaling is a prevalent technique used to reduce the video storage burden or to accelerate the downstream processing speed. However, the inverse upscaling step is non-trivial, and the downscaled video may also deteriorate the performance of downstream tasks. In this paper, we propose a self-conditioned probabilistic framework for video rescaling to learn the paired downscaling and upscaling procedures simultaneously. During the training, we decrease the entropy of the information lost in the downscaling by maximizing its probability conditioned on the strong spatial-temporal prior information within the downscaled video. After optimization, the downscaled video by our framework preserves more meaningful information, which is beneficial for both the upscaling step and the downstream tasks, e.g., video action recognition task. We further extend the framework to a lossy video compression system, in which a gradient estimator for non-differential industrial lossy codecs is proposed for the end-to-end training of the whole system. Extensive experimental results demonstrate the superiority of our approach on video rescaling, video compression, and efficient action recognition tasks.
Wood-leaf classification of tree point cloud based on intensity and geometrical information
Aug 02, 2021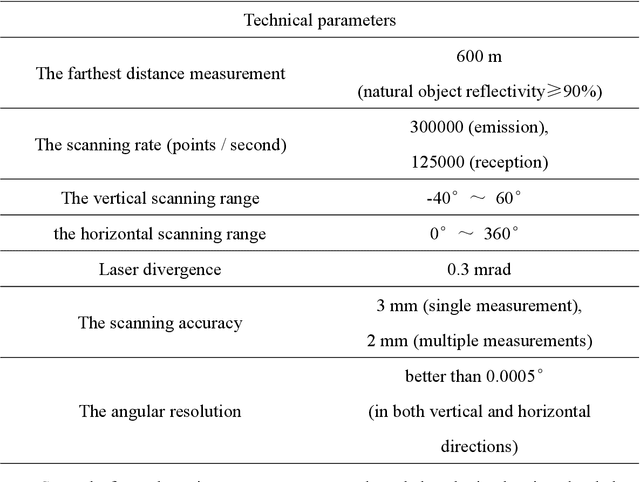

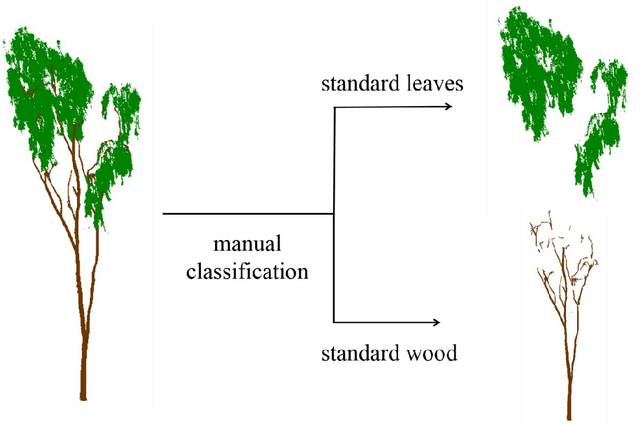
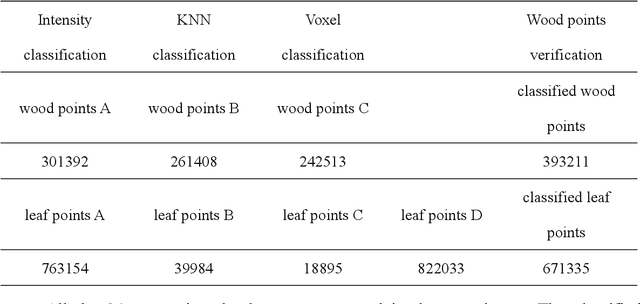
Terrestrial laser scanning (TLS) can obtain tree point cloud with high precision and high density. Efficient classification of wood points and leaf points is essential to study tree structural parameters and ecological characteristics. By using both the intensity and spatial information, a three-step classification and verification method was proposed to achieve automated wood-leaf classification. Tree point cloud was classified into wood points and leaf points by using intensity threshold, neighborhood density and voxelization successively. Experiment was carried in Haidian Park, Beijing, and 24 trees were scanned by using the RIEGL VZ-400 scanner. The tree point clouds were processed by using the proposed method, whose classification results were compared with the manual classification results which were used as standard results. To evaluate the classification accuracy, three indicators were used in the experiment, which are Overall Accuracy (OA), Kappa coefficient (Kappa) and Matthews correlation coefficient (MCC). The ranges of OA, Kappa and MCC of the proposed method are from 0.9167 to 0.9872, from 0.7276 to 0.9191, and from 0.7544 to 0.9211 respectively. The average values of OA, Kappa and MCC are 0.9550, 0.8547 and 0.8627 respectively. Time cost of wood-leaf classification was also recorded to evaluate the algorithm efficiency. The average processing time are 1.4 seconds per million points. The results showed that the proposed method performed well automatically and quickly on wood-leaf classification based on the experimental dataset.
EAN: Event Adaptive Network for Enhanced Action Recognition
Jul 22, 2021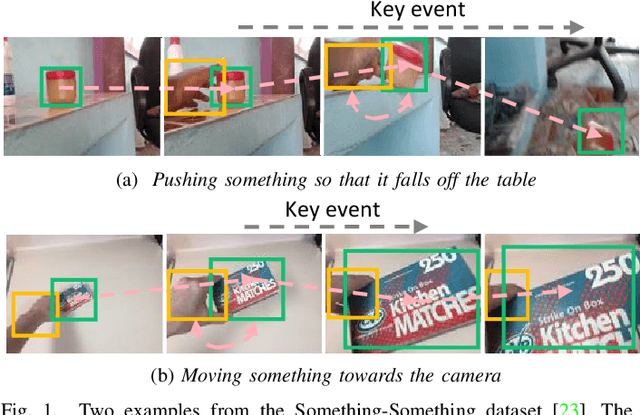
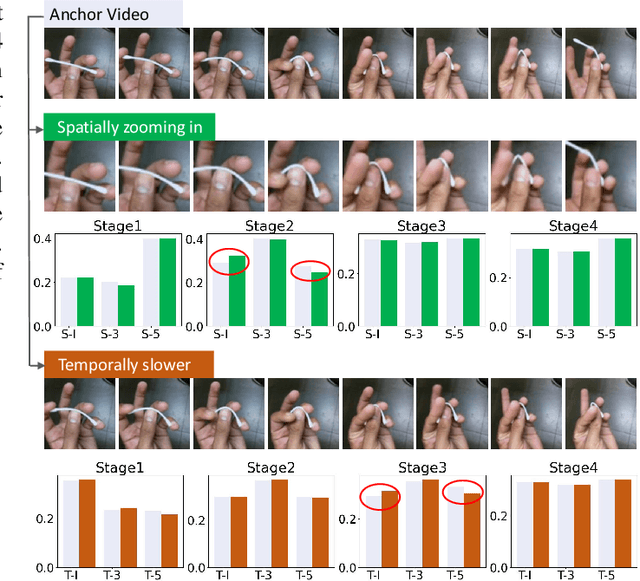
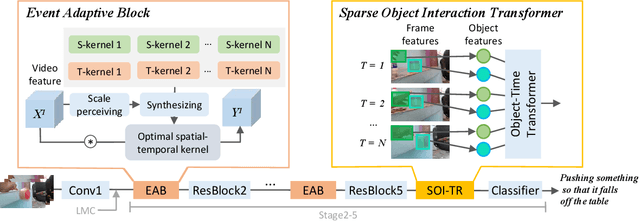
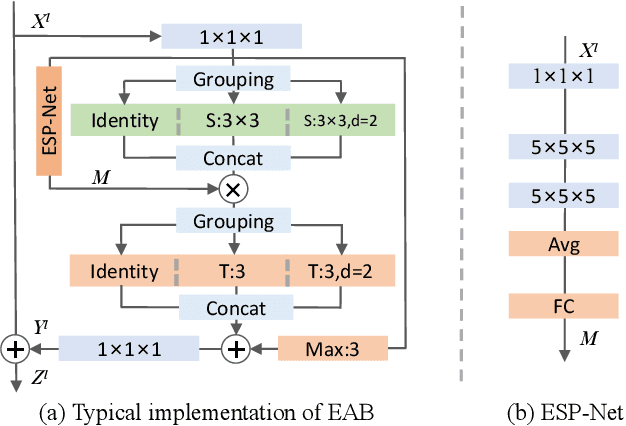
Efficiently modeling spatial-temporal information in videos is crucial for action recognition. To achieve this goal, state-of-the-art methods typically employ the convolution operator and the dense interaction modules such as non-local blocks. However, these methods cannot accurately fit the diverse events in videos. On the one hand, the adopted convolutions are with fixed scales, thus struggling with events of various scales. On the other hand, the dense interaction modeling paradigm only achieves sub-optimal performance as action-irrelevant parts bring additional noises for the final prediction. In this paper, we propose a unified action recognition framework to investigate the dynamic nature of video content by introducing the following designs. First, when extracting local cues, we generate the spatial-temporal kernels of dynamic-scale to adaptively fit the diverse events. Second, to accurately aggregate these cues into a global video representation, we propose to mine the interactions only among a few selected foreground objects by a Transformer, which yields a sparse paradigm. We call the proposed framework as Event Adaptive Network (EAN) because both key designs are adaptive to the input video content. To exploit the short-term motions within local segments, we propose a novel and efficient Latent Motion Code (LMC) module, further improving the performance of the framework. Extensive experiments on several large-scale video datasets, e.g., Something-to-Something V1&V2, Kinetics, and Diving48, verify that our models achieve state-of-the-art or competitive performances at low FLOPs. Codes are available at: https://github.com/tianyuan168326/EAN-Pytorch.
Prediction-assistant Frame Super-Resolution for Video Streaming
Mar 17, 2021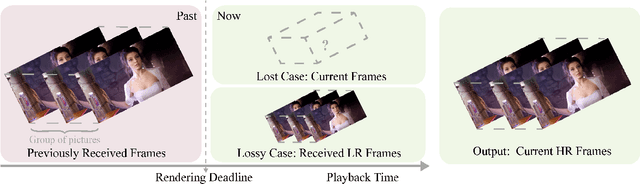
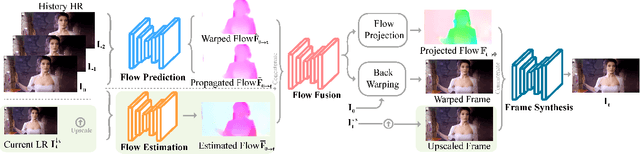
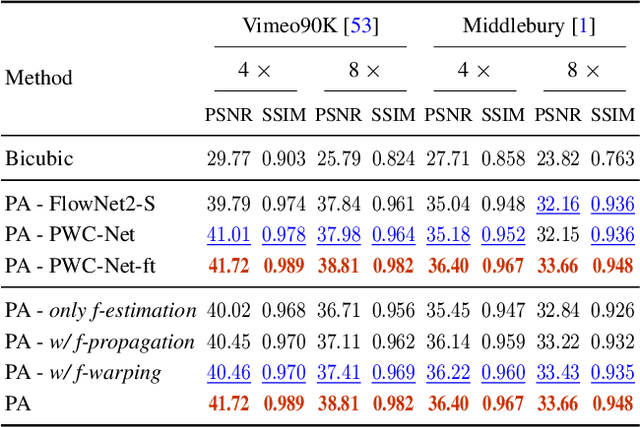

Video frame transmission delay is critical in real-time applications such as online video gaming, live show, etc. The receiving deadline of a new frame must catch up with the frame rendering time. Otherwise, the system will buffer a while, and the user will encounter a frozen screen, resulting in unsatisfactory user experiences. An effective approach is to transmit frames in lower-quality under poor bandwidth conditions, such as using scalable video coding. In this paper, we propose to enhance video quality using lossy frames in two situations. First, when current frames are too late to receive before rendering deadline (i.e., lost), we propose to use previously received high-resolution images to predict the future frames. Second, when the quality of the currently received frames is low~(i.e., lossy), we propose to use previously received high-resolution frames to enhance the low-quality current ones. For the first case, we propose a small yet effective video frame prediction network. For the second case, we improve the video prediction network to a video enhancement network to associate current frames as well as previous frames to restore high-quality images. Extensive experimental results demonstrate that our method performs favorably against state-of-the-art algorithms in the lossy video streaming environment.
Generative Model without Prior Distribution Matching
Sep 23, 2020
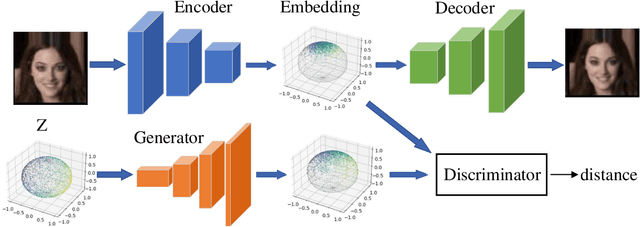

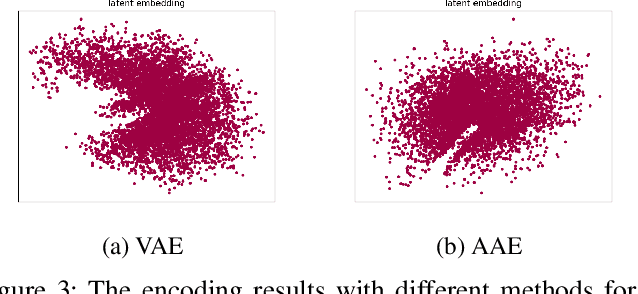
Variational Autoencoder (VAE) and its variations are classic generative models by learning a low-dimensional latent representation to satisfy some prior distribution (e.g., Gaussian distribution). Their advantages over GAN are that they can simultaneously generate high dimensional data and learn latent representations to reconstruct the inputs. However, it has been observed that a trade-off exists between reconstruction and generation since matching prior distribution may destroy the geometric structure of data manifold. To mitigate this problem, we propose to let the prior match the embedding distribution rather than imposing the latent variables to fit the prior. The embedding distribution is trained using a simple regularized autoencoder architecture which preserves the geometric structure to the maximum. Then an adversarial strategy is employed to achieve a latent mapping. We provide both theoretical and experimental support for the effectiveness of our method, which alleviates the contradiction between topological properties' preserving of data manifold and distribution matching in latent space.
Video-ception Network: Towards Multi-Scale Efficient Asymmetric Spatial-Temporal Interactions
Jul 22, 2020
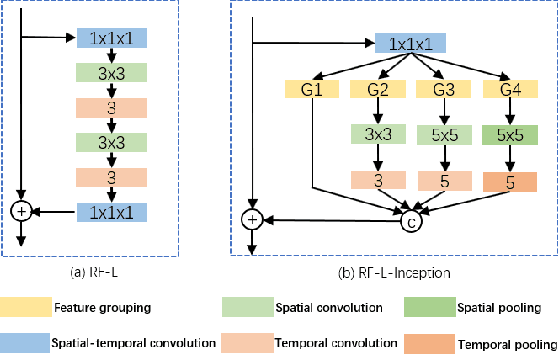
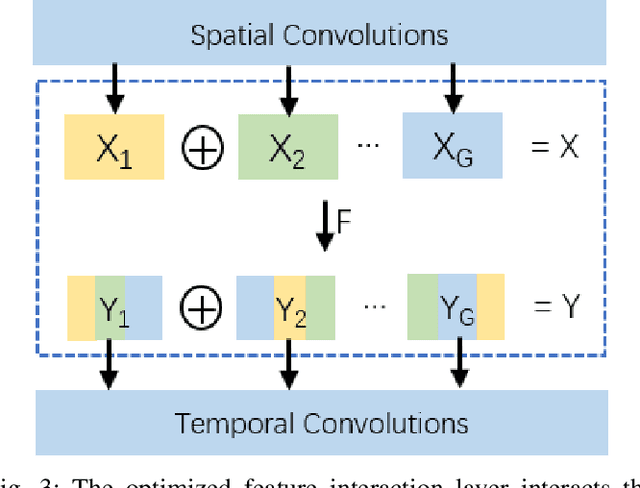
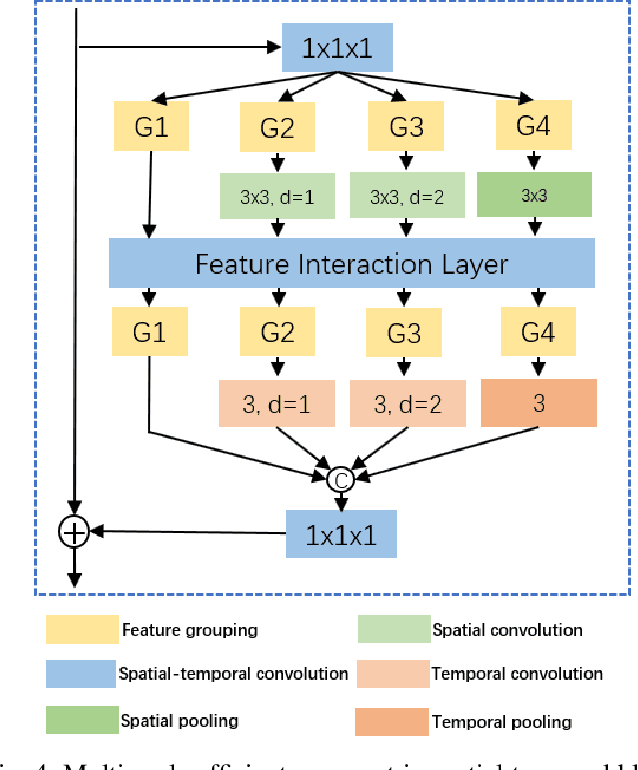
Previous video modeling methods leverage the cubic 3D convolution filters or its decomposed variants to exploit the motion cues for precise action recognition, which tend to be performed on the video features along the temporal and spatial axes symmetrically. This brings the hypothesis implicitly that the actions are recognized from the cubic voxel level and neglects the essential spatial-temporal shape diversity across different actions. In this paper, we propose a novel video representing method that fuses the features spatially and temporally in an asymmetric way to model action atomics spanning multi-scale spatial-temporal scales. To permit the feature fusion procedure efficiently and effectively, we also design the optimized feature interaction layer, which covers most feature fusion techniques as special case of it, e.g., channel shuffling and channel concatenating. We instantiate our method as a \textit{plug-and-play} block, termed Multi-Scale Efficient Asymmetric Spatial-Temporal Block. Our method can easily adapt the traditional 2D CNNs to the video understanding tasks such as action recognition. We verify our method on several most recent large-scale video datasets requiring strong temporal reasoning or appearance discriminating, e.g., Something-to-Something v1, Kinetics and Diving48, demonstrate the new state-of-the-art results without bells and whistles.