 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-ception Network: Towards Multi-Scale Efficient Asymmetric Spatial-Temporal Interactions
Jul 22, 2020
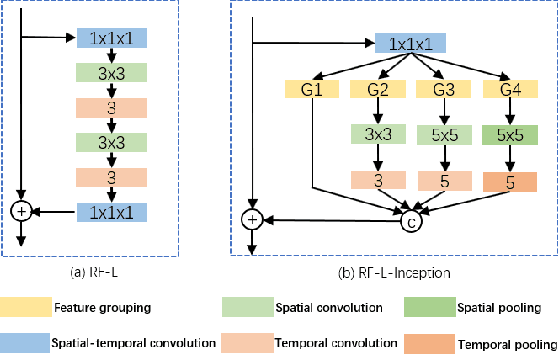
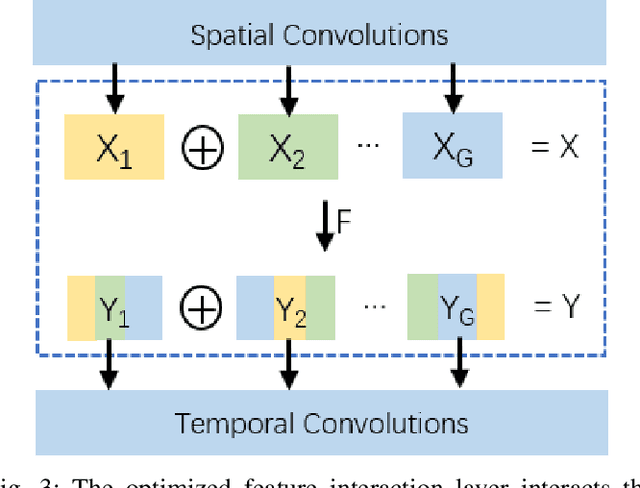
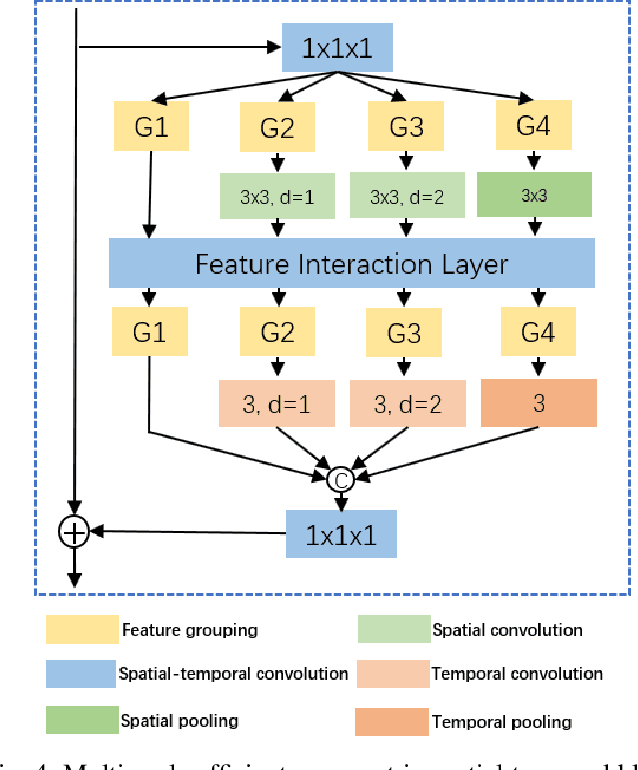
Previous video modeling methods leverage the cubic 3D convolution filters or its decomposed variants to exploit the motion cues for precise action recognition, which tend to be performed on the video features along the temporal and spatial axes symmetrically. This brings the hypothesis implicitly that the actions are recognized from the cubic voxel level and neglects the essential spatial-temporal shape diversity across different actions. In this paper, we propose a novel video representing method that fuses the features spatially and temporally in an asymmetric way to model action atomics spanning multi-scale spatial-temporal scales. To permit the feature fusion procedure efficiently and effectively, we also design the optimized feature interaction layer, which covers most feature fusion techniques as special case of it, e.g., channel shuffling and channel concatenating. We instantiate our method as a \textit{plug-and-play} block, termed Multi-Scale Efficient Asymmetric Spatial-Temporal Block. Our method can easily adapt the traditional 2D CNNs to the video understanding tasks such as action recognition. We verify our method on several most recent large-scale video datasets requiring strong temporal reasoning or appearance discriminating, e.g., Something-to-Something v1, Kinetics and Diving48, demonstrate the new state-of-the-art results without bells and whistles.